













Whisper marketing and influencer marketing are important elements of many marketing campaigns. Dissemination of product information by a friend in specific target groups is much more powerful than advertising targeted directly at all people in a given community. It is natural, that we trust the recommendation of a friend rather than the marketing message of the company. Therefore, it is important to identify people who have the potential to influence their community.
You can search for such groups and influencers on portals such as Facebook or LinkedIn, but there are also other sources of information that can be used (e.g. telecommunication connections). Moreover, it is possible to search for groups that are not formally defined.
Each large population of people is divided into micro-communities. Their members can be assigned specific roles describing their „role” in the community and their ability to disseminate information.
Role of the influencer
The data defining community is often created naturally by contacting different people, visiting websites, posting content or commenting. Members of the micro-communities influence each other, but some of them have a greater influence than others. They are called influencers. Sending marketing information to an influencer, who will publish the content, is associated with gaining publicity in the micro-community to which it belongs.
AdvancedMiner allows for automated analysis of large databases describing the structure of interpersonal relationships. The databases can contain tens of millions of people and hundreds of millions of connections between them. The result of this analysis will be:
- an identification of micro-communities
- a determination of a given person’s ability to disseminate information
- a designation of contractual social roles (leader, follower)
- a multidimensional characteristics of a person in the context of his/her social relations
Social Network Analysis
In AdvancedMiner, Social Network Analysis consists of the following steps:
- building network
- network filtering (optional)
- network analysis
- network visualization (optional)
In order to complete the above-mentioned steps, a database table, which stores data on the network structure, is required. The example below has been done by using the YouTube user contact database available on the website: Arizona State University.
Network building
After selecting the table in Workflow and connecting it with the Build Network option from the SNA tab, in the settings, select the fields with the source and target node identifiers. Optionally, you can select third column Weight (by default, all connections’ weight is set to 1).
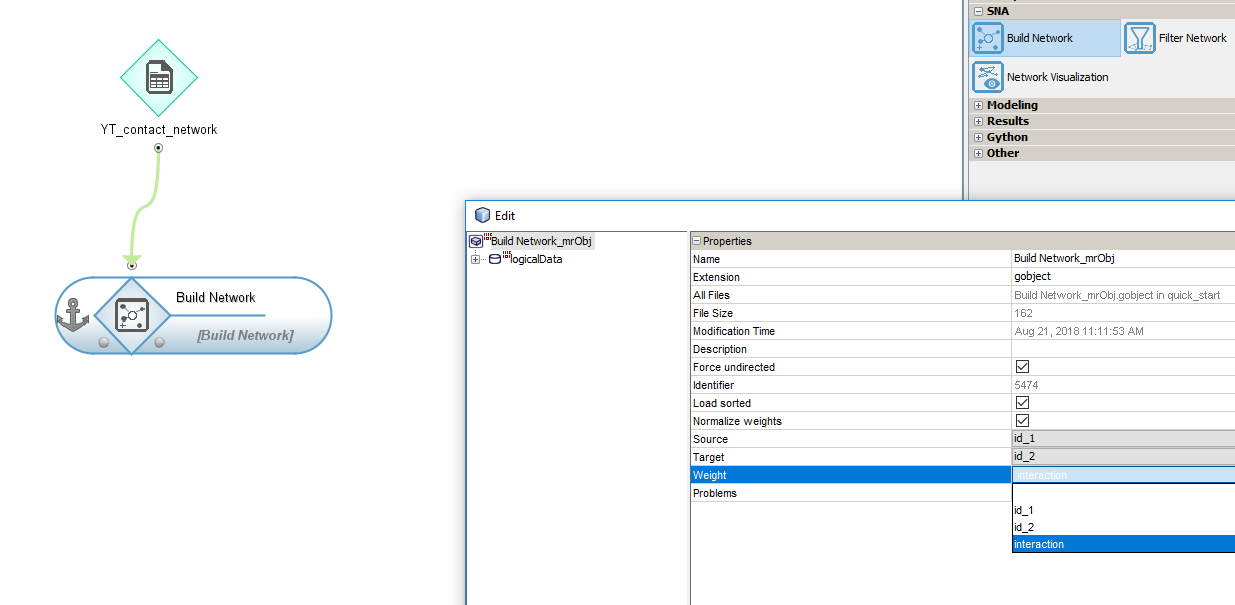
Network filtering
In some cases it may be necessary to filter in order to obtain a smaller network size. The SNA module allows you to perform this task. You need a database table containing fields with node numbers used to build the network.
In the Filter field, enter the condition according to which the network is to be filtered. It may contain such elements as:
- comparison of attributes
- checking the node id – function id(id1, id2, id3, id4, …) – TRUE will be returned for values stored in the set, for example id(1, 2, 3, 4), for nodes with numbers other than those given in brackets, FALSE will be returned
- neighbourhood membership – function neigh(expression, radius) – returns the TRUE for nodes that are adjacent to theradius meet the expression condition
- set membership – function attribute in [value1, value2 …] – returns TRUE for an attribute which is equal to one of the values given in brackets
Conditions can be connected by AND and OR operators.
Algorithms for network analysis in AdvancedMiner
Network analysis is the most important part of the work with networks. To perform it, select Network Analysis from the SNA tab and connect it to the table and the built network. To analyze the data, there are used built-in algorithms. It is possible to use one or more algorithms at once.
- Louvain community finder – a popular algorithm used for fast detection of communities in the network. Louvain community finder iteratively optimizes communities by maximizing modularity measure. The algorithm can also find a hierarchy of nested communities (ranging from large to many small communities).
- Modularity – a quantity with values in the range from -1 to 1. Modularity measures ties in communities as compared to ties between communities.
- Size constrained community finder – an algorithm that allows to search for a network community at a maximum size specified by the user.
- Community statistics – it calculates basic statistics for the community, i.e. number of ties inside the community, number of ties with other communities, relation of the number of ties inside the community to the number of ties both inside and outside the community, sum of weights inside the community, sum of weights of ties to other communities.
- Role Finder – an algorithm determining the role of a node in the network by finding similarities of connections between nodes. It is assumed that a node performing a specific role has a specific pattern of connections with other nodes. Two statistics are calculated: a leadership score and a participation score. Based on their values, roles are defined. Nodes with a high leadership rate are called leaders, whereas with low score are called followers. Nodes with a low participation rate are defined as peripheral.
PL – Peripheral leader
CL – Connecting leader
KL – Kinless leader
UPF – Ultra-peripheral follower
PF – Peripheral follower
CF – Connecting follower
KF – Kinless follower - Aggregator – algorithm calculating, for a node in the network, statistics based on a given node from its neighborhood on the basis of the data describing network connections, network data, and additional attributes describing every node. Among other things, there are calculated statistics describing a node position in the neighborhood, length of the paths from a node to node.
- Triad statistics – determines to how many different triad types a node belongs.
- Equivalence – the concept of equivalence is often used to describe the similarity of connections to other network nodes. It is presupposed that fully equivalent networks have direct connections to the same network nodes.
- Community equivalence – equivalence to community nodes.
- Page Rank Algorithm – algorithm used by Google Search to rate websites (but can also be used for other data describing the network). It determines the meaning of a given node based on the quality of the nodes connected to it.
- HITS Algorithm (Hyperlink-Induced Topic Search) – algorithm similar to the Page Rank algorithm also used to rate websites. It evaluates to what extent a node acts as a center or authority.
- Spreading Activation Algorithm – an algorithm simulating the propagation of information in the network. It starts with one initial node, which transfers energy to the nodes to which it is connected. In subsequent iterations, nodes that have an energy level above a given level transfer energy to the nodes associated with them.
Network analysis
In the analysis menu, select a column containing identifiers that are vertices in the network. Then add an appropriate algorithm and enter the data necessary for its execution.
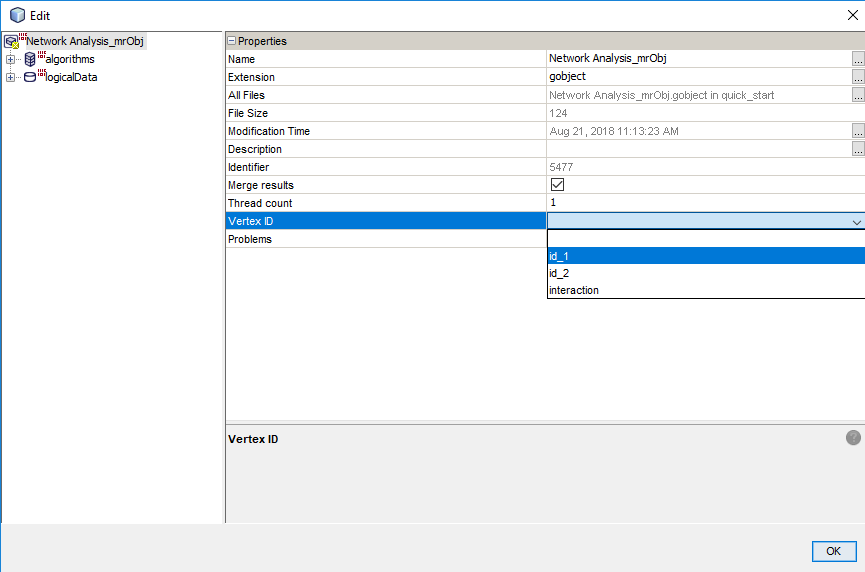
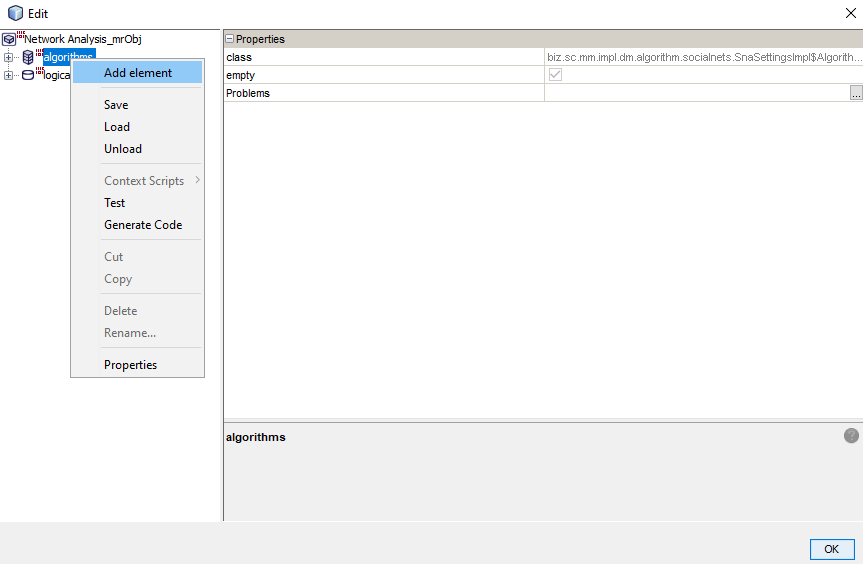
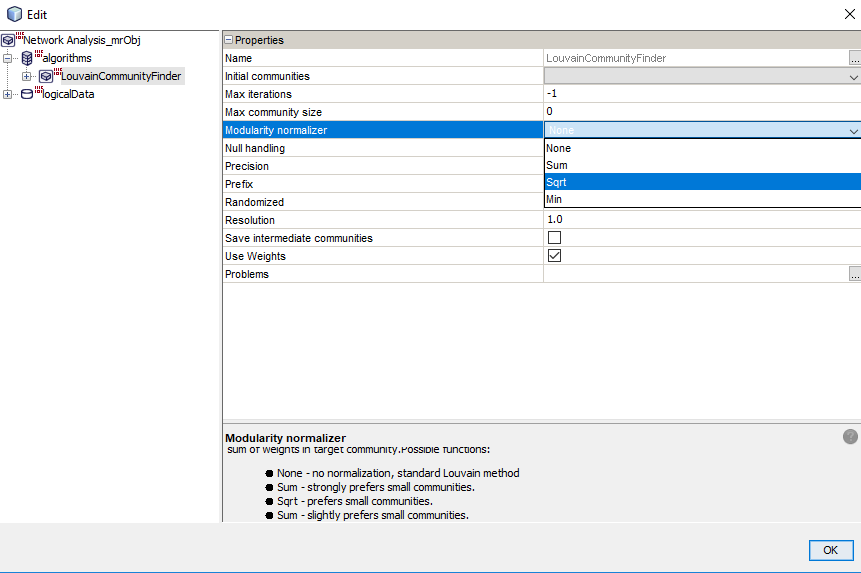
After pressing F6 a new table containing a column with a selected identifier (vertex) and columns containing information returned by selected algorithms is received.
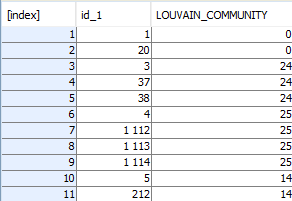
Network visualisation
In order to visualize the network, select Network Visualization. It can be connected to a built network or with executed filtering.
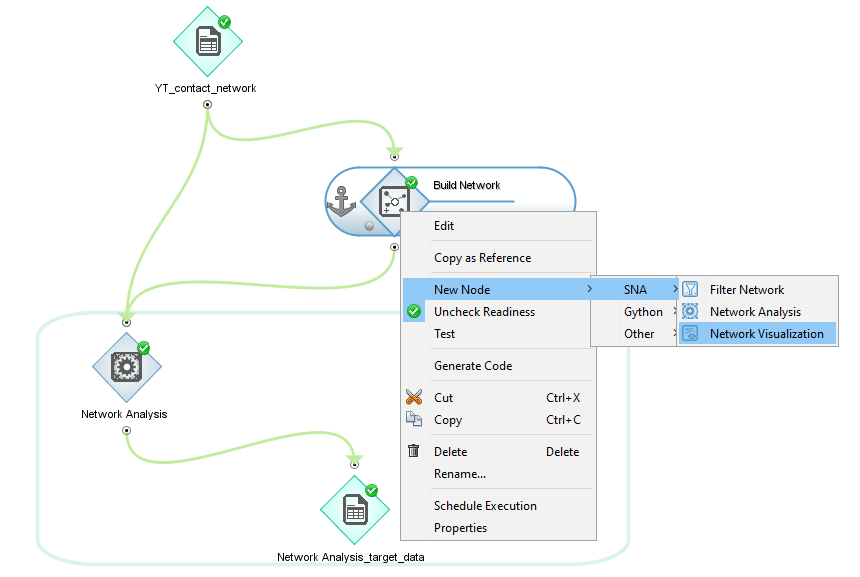
Visualization, in addition to presenting the network, can also present different types of variables and statistics related to network nodes or subnetworks, such as communities, roles. In order to present additional information to the visualization object, the attributes contained in other tables should be added to the visualization object.
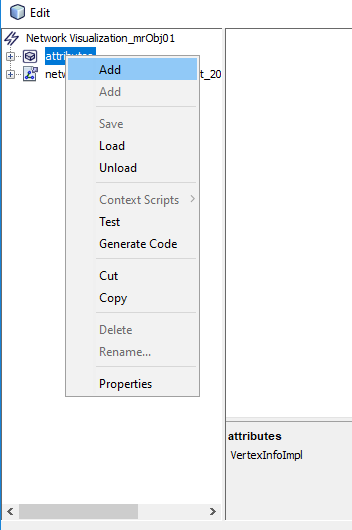
After loading the visualization, you can change the appearance of the presented graph with the sliders at the bottom of the window. The toolbar at the top of the window allows you to filter nodes, add supplementary data, launch the Freq tool or take a screenshot of the visualization window.

Press Ctrl+7 to start the navigator. It allows you to customize the content of the visualization.
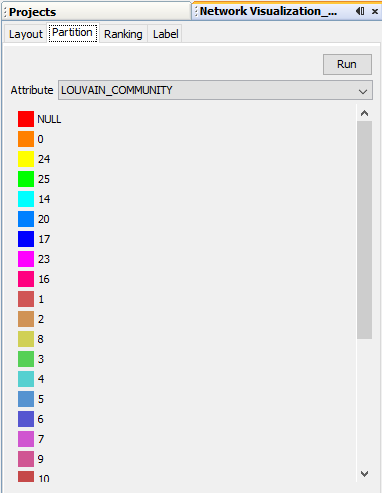
You can adjust the layout on the Layout tab. There are three different layouts available: ForceDirected, OpenOrd and Random.
Partition enables to divide the network. The network can be divided according to nominal or integer variables. Nodes with different values are assigned different colors.
Ranking is used to visualize additional numerical attributes of nodes. You can change the size of nodes, colors or even their saturation.
Label is a tab where it is possible to add labels with selected values of selected network attributes.
Navigator application examples
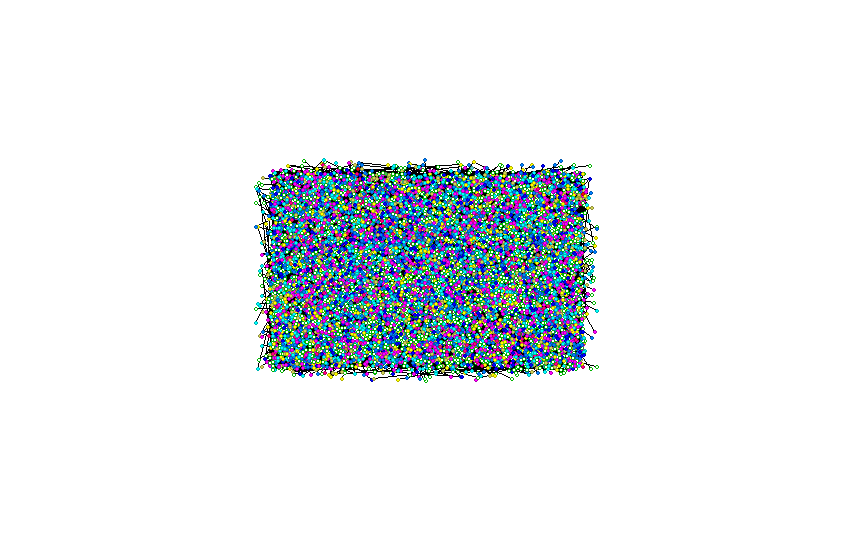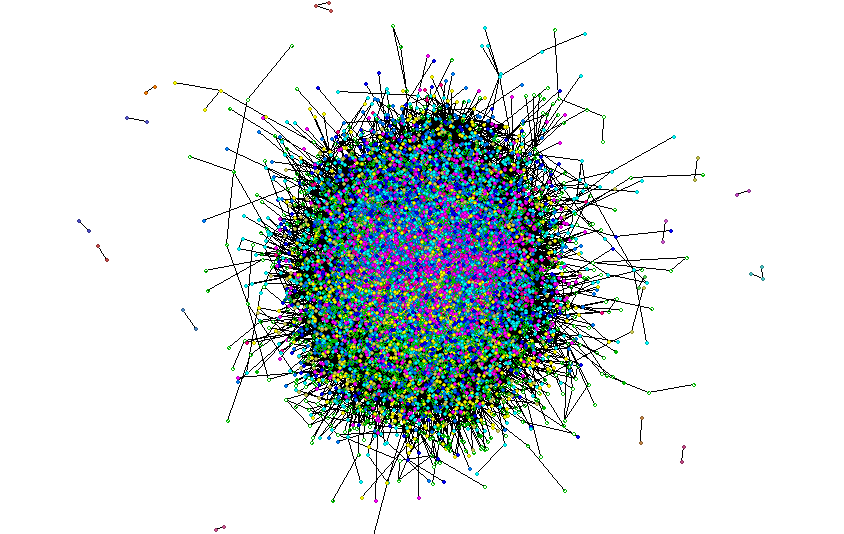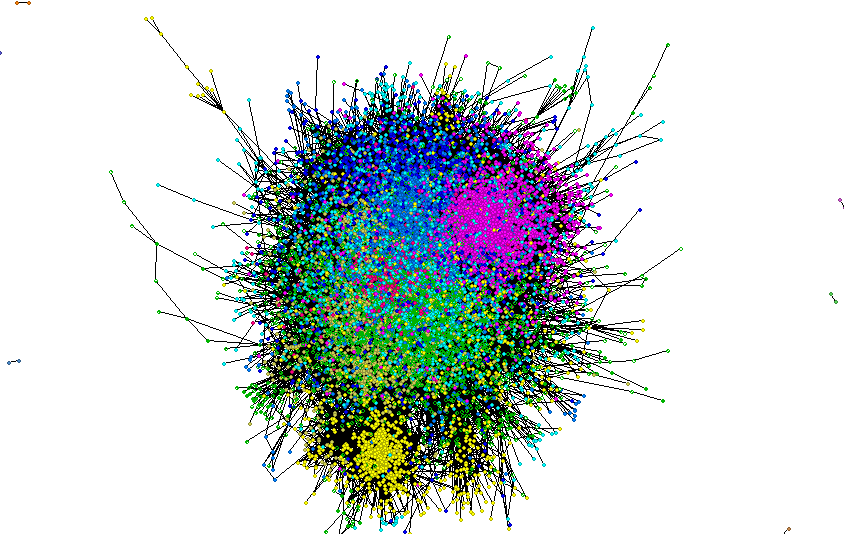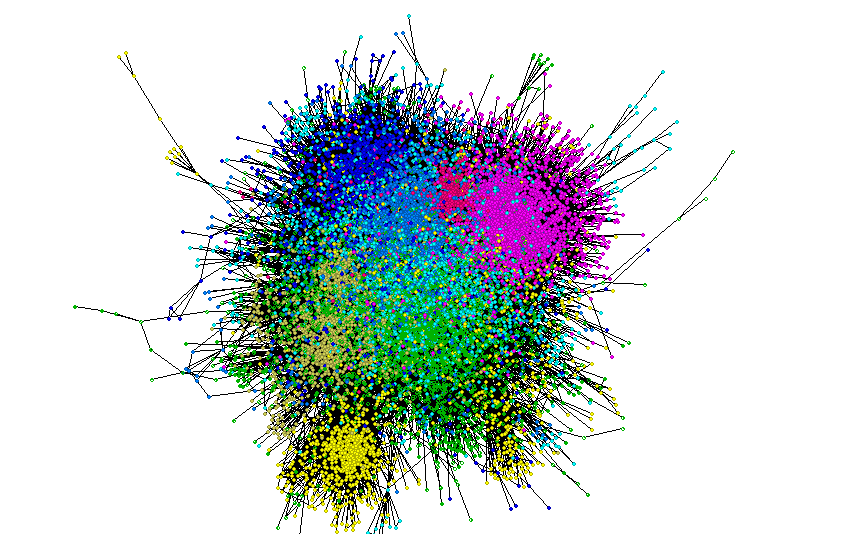
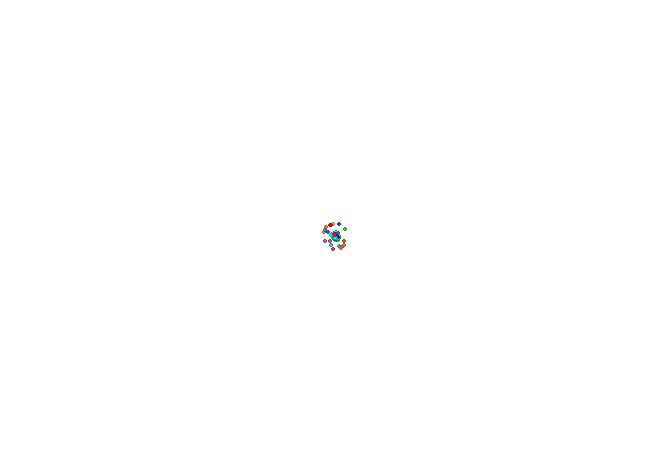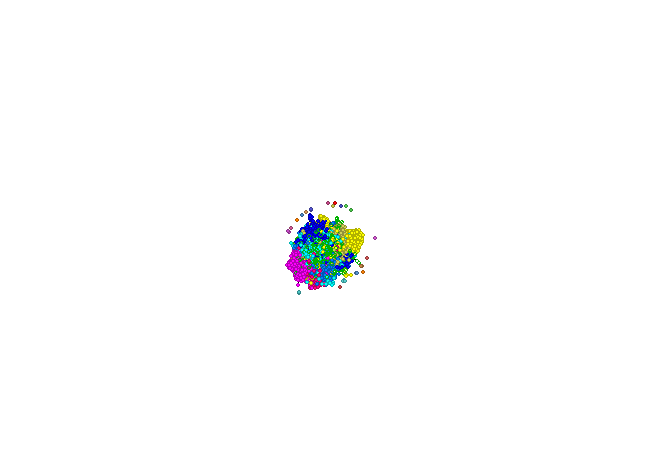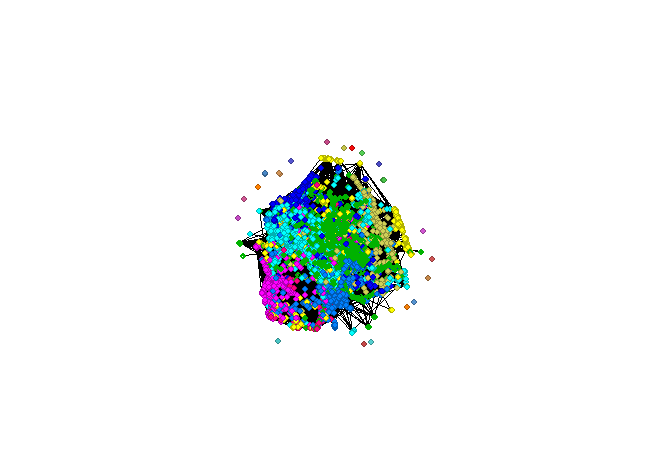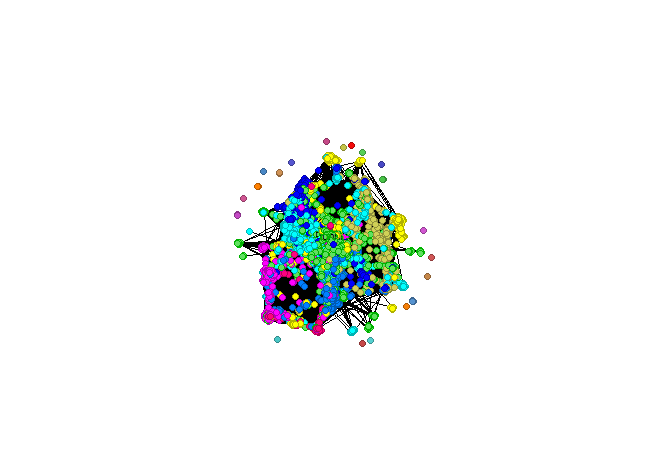
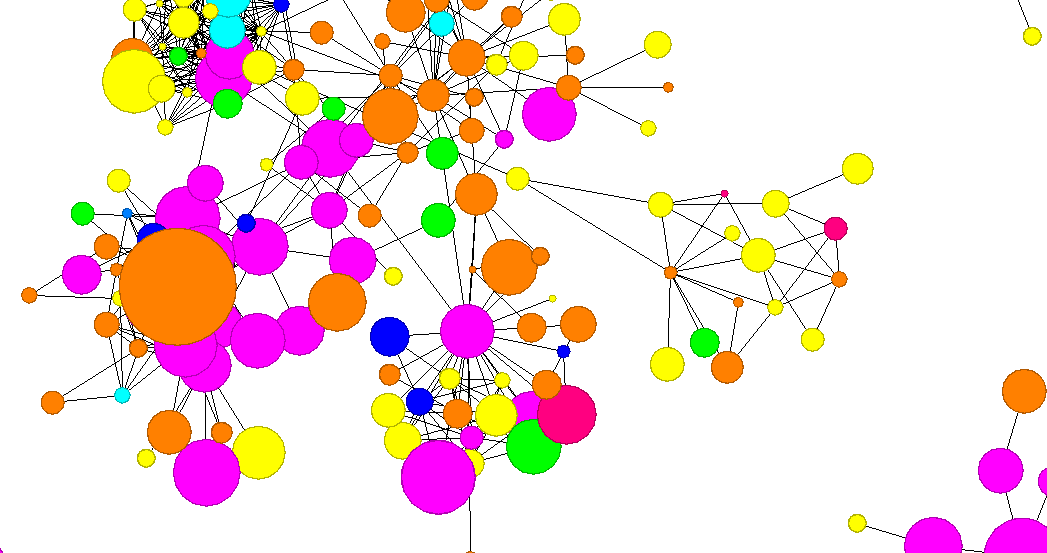
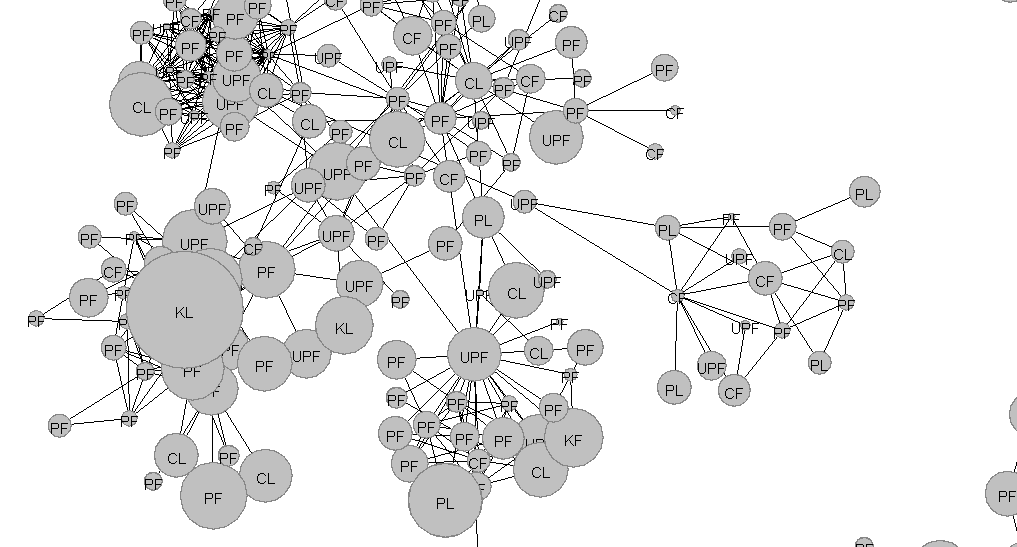
To sum up, after a few steps, you will understand how micro-communities are formed. You will find a person, who will make your campaign reach the widest possible audience. By using many algorithms, you will learn numerous statistics about each of the members of a given network, community and links between nodes.
The source of the used data set:
R. Zafarani and H. Liu, (2009). Social Computing Data Repository at ASU [http://socialcomputing.asu.edu]. Tempe, AZ: Arizona State University, School of Computing, Informatics and Decision Systems Engineering



