













In an era where business decisions must be made in milliseconds, and machine learning models power an ever‑growing range of processes—from credit scoring and marketing automation to fraud detection—the feature store has become a core part of modern ML infrastructure. It serves as a central repository for machine learning features, enabling teams to manage and reuse them across multiple ML pipelines. This not only accelerates data science workflows but also enforces consistency and standardization across analytics and ML teams.
In this article, you will learn what a feature store is and how it works in real‑world machine learning systems. We’ll walk through the key business benefits of adopting a feature store, including improved data consistency, faster model development, and better collaboration between teams. You’ll also see practical feature store use cases across industries such as banking, e‑commerce, and energy, along with the roles involved - from data scientists to IT architects. In addition, the article introduces the Algolytics platform and its Event Engine module, highlighting the capabilities that differentiate it from other solutions. Finally, you’ll learn how to implement a feature store step by step and explore common usage patterns from real machine learning projects.
What is a feature store? ML features
A feature store is a centralized repository of features used by machine learning models. It sits between raw data sources and ML models, providing a consistent way to store, compute, and serve features for both model training and production inference. By introducing a feature store, organizations establish a single source of truth for feature values, eliminating discrepancies between the data used during training and the data used in production.
A modern feature store typically operates in two modes: online and offline. It ingests and integrates data from multiple sources, including real‑time data streams and batch data from cloud‑based systems. Features are organized into feature groups - logical collections enriched with metadata and descriptions - which makes it easier to discover, manage, and reuse features across different use cases.
Basic concepts:
- Feature – a single input variable used by a machine learning model, describing a specific property of an entity (for example, the number of transactions in the last 24 hours).
- Feature group – a logical collection of related features that share common metadata (such as descriptions, definitions, and data lineage) along with identification keys that define the entity they apply to (for example, a customer, account, or device).
- Entity profile – a snapshot of current feature values describing a specific entity (such as a customer or account) at a given point in time.
- Feature vector – an ordered set of feature values passed to a machine learning model at inference time.
What business benefits do feature stores provide?
Main benefits of the feature store:
- Consistency between training and production scoring – the same feature definitions are used during both model training and production scoring, eliminating discrepancies between training data and production data.
- Faster deployment of new machine learning models – a feature store enables teams to reuse existing, well‑defined features across multiple projects and models without duplicating data processing logic. Instead of building pipelines from scratch, data scientists work with a shared feature library, significantly reducing data preparation time—often by weeks or even months.
- Improved team collaboration – data science, data engineering, and IT teams operate on a single source of truth. The metadata catalog makes it easy to define and discover features, while allowing data scientists to track feature ownership and understand which models and endpoints consume them.
- Lower infrastructure costs – avoiding duplicated data processing pipelines reduces maintenance overhead and total cost of ownership (TCO). Rather than managing multiple tools, teams can rely on a single platform for feature management.
- Support for real‑time decision‑making – feature stores enable products and systems to react immediately to user events, with decisions made in milliseconds instead of minutes.
- Regulatory compliance and auditability – built‑in feature lineage and traceability make it easier to meet legal and audit requirements, which is critical in regulated industries such as finance and insurance.
- Feature quality monitoring – the system detects and alerts on issues such as data drift, missing values, or delayed updates, allowing teams to address data quality problems before they impact model performance.
Feature stores and real-time data processing applications
Stream processing combined with a feature store enables decision‑making in milliseconds. Below are representative use cases across different industries:
- Online credit scoring (banking) – loan applications are evaluated in under 200 milliseconds based on a customer’s behavioral history, external credit bureau data (e.g. BIK), and repayment patterns.
Features: number of applications in the last 30 days, credit limit utilization, history of late payments. - Payment fraud detection – suspicious card transactions are identified in real time, before authorization.
Features: number of transactions in the last 5 minutes and 24 hours, geographic distance between consecutive transactions, terminal or merchant type, unusually high transaction amounts. - Real‑time marketing in e‑commerce – product recommendations are generated based on recent user behavior, cart activity, and purchase history.
Features: product categories viewed in the last hour, abandoned cart value, visit frequency. - Churn prediction in telecommunications – the risk of customer churn is identified based on current service usage patterns.
Features: number of customer service requests, changes in data usage or call minutes, time since the last tariff change, in‑app activity. - Sensor failure prediction – models are used to proactively detect the risk of sensor failure and route devices for maintenance before breakdowns occur.
Features: average and maximum sensor temperature, number of duty cycles, continuous operating time, distance to the nearest service point. - Dynamic pricing (insurance, transport) – insurance premiums or tariffs are calculated dynamically in real time based on the current risk profile.
Features: claims history, driving behavior patterns, location data. - Content personalization (media, streaming) – content such as recommended videos is tailored to individual user preferences.
Features: recently viewed categories, time spent on content, return frequency.
Who uses the feature store – roles, teams, organizations
A feature store is not just a tool for data scientists. As a centralized repository of features, it is used by multiple roles across the organization - from analysts to IT architects.
Main roles and their perspective:
- Data scientist – works with ready‑to‑use, precomputed features, enabling faster model development and experimentation with new feature combinations. Data scientists need visibility into feature origins and understand which models and endpoints consume them in order to reuse features in future projects. A feature store provides this through feature history tracking, including data lineage, source systems, and transformation logic.
- ML engineer / MLOps – is responsible for reliably serving features to models running in both online and batch environments. This role manages model deployment, integration with scoring systems, and versioning across the machine learning lifecycle.
- Data engineer – builds and maintains integrations with data sources and manages pipelines that transform raw data into features stored in the feature store. This includes defining data transformations and time windows.
- Business analyst / Risk officer – uses predefined feature sets in reports and analytical workflows. This role understands model logic and ensures alignment with business rules, risk policies, and regulatory requirements.
- IT architect / CTO (Chief Technology Officer) – makes architectural decisions around deployment models (cloud, on‑premise, or hybrid), evaluates total cost of ownership (TCO), oversees system integration, and ensures security, scalability, and compliance of the overall solution.
Algolytics’ clients are primarily medium and large organizations across Poland and the CEE region (Central and Eastern Europe) with mature credit, anti‑fraud, and marketing processes. These typically include banks, insurance companies, telecommunications operators, and e‑commerce platforms.
It is also worth noting that smaller companies using SaaS solutions - such as ready‑made B2B or B2C credit scoring APIs - indirectly benefit from an embedded feature store, even if they do not manage it directly. In these cases, feature computation and management are handled transparently by the provider’s platform.
Feature store by Algolytics – what makes Event Engine stand out
Event Engine is a core component of the Algolytics platform - a proprietary real‑time event processing engine that also serves as a feature store. It is a fundamental part of the platform’s architecture, designed from the ground up to support real‑time machine learning. Event Engine enables teams to manage the full feature lifecycle, from creation and storage to serving, updates, and deletion, streamlining ML workflows and simplifying data management.
Key differentiating capabilities of Event Engine (feature store):
- Real‑time processing – real‑time data processing with scoring latency below 5 milliseconds, enabling decisions to be made almost immediately after an event occurs.
- State checkpointing – inactive profiles are persisted to the database and dynamically restored when needed, allowing the system to manage millions of entity profiles without performance degradation.
- Flexible scaling – dynamic resource allocation based on current workloads ensures high availability and consistent performance under varying traffic conditions.
- High performance – scoring throughput of up to 20,000 events per second, making Event Engine well suited for large‑scale ML environments that require low latency and high scalability.
- Unified online and offline processing – a single feature definition and a single source of truth. Features used for model training are identical to those available during production scoring, eliminating training‑serving skew.
- In‑memory processing optimization – aggregate updates are computed on the fly without querying the database. Supported time window mechanisms include tumbling windows, sliding windows, event‑based windows, and real‑time (continuously updated) windows.
- Automatic training dataset generation – native integration with the AutoML module (Automatic Business Modeler, ABM). Event Engine generates feature tables, ABM trains machine learning models, and model deployment is handled automatically by the Scoring.One MLOps platform.
- End‑to‑end MLOps integration – Event Engine manages events, state, and features, while Scoring.One acts as the decision engine. Together, they form a coherent decision flow—from event ingestion to final outcome.
- Metadata‑driven feature management – feature definitions can be modified without changing application code. Updates require only a metadata change followed by configuration reload.
- Pattern‑based feature generation – the ability to generate thousands of aggregates from a single template. A single definition can produce counters, sums, and averages across multiple time windows for multiple fields.
The Algolytics platform is available in the cloud (Azure, AWS, and GCP), on‑premise, and in a hybrid deployment model. This flexibility is particularly important for the financial and telecommunications sectors in Poland, where regulatory requirements often limit or exclude the use of fully public cloud environments.
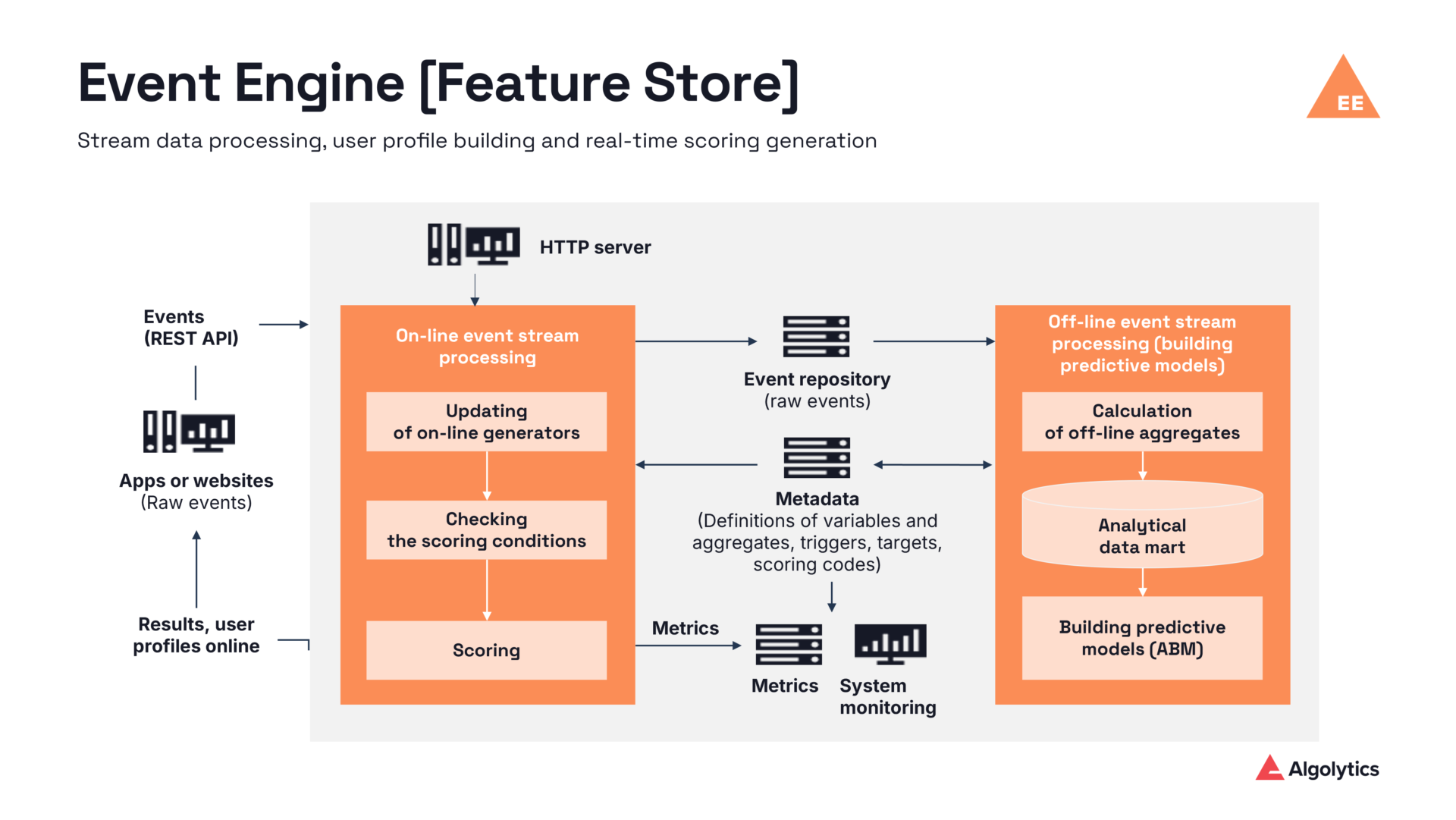
Online and offline architecture in Event Engine by Algolytics
Online processing – step by step
- Event ingestion – events such as logins, payments, or clicks are sent from the application to Apache Kafka via REST/JSON. The system can perform real‑time feature operations, such as instantly joining data from multiple feature groups, enabling fast, low‑latency feature access.
- Transformation – Event Engine (feature store) immediately transforms incoming data (JSON → primitive variables) based on metadata definitions, including JSONPath expressions and Java functions. It can ingest data from various sources such as application logs, event streams, and databases, enabling flexible data integration for feature computation.
- Trigger evaluation – the system determines whether a given event requires scoring, for example when a loan application is submitted or a high‑value transaction occurs.
- Profile update – the in‑memory entity profile is updated with counters, aggregates, and time‑based windows, including 5‑minute, hourly, daily, and a special current window (WINDOW_CURRENT_TIME).
- Scoring – a feature vector is assembled and passed to a machine learning model (trained via ABM or executed in Scoring.One). The prediction result is produced within single‑digit milliseconds.
- Persistence – the event is written in parallel to durable storage, such as a relational database, NoSQL store, or object storage, ensuring long‑term persistence and auditability.
Offline processing – step by step
- Analytical table structure – rows represent users or contracts, while columns contain features and the target variable (for example, whether a specific event occurred). Data can originate from multiple sources and time points, allowing historical and current information to be combined into a single analytical dataset.
- Scheduled batch processing – batch jobs are executed cyclically to compute aggregates over defined time windows preceding the target event. Based on these calculations, the system generates training datasets used to build machine learning models.
Data synchronization and consistency
Event Engine ensures full synchronization between online and offline processing, eliminating the risk of training‑serving skew and guaranteeing that machine learning models use the same feature definitions during both training and production scoring.
Advanced feature store features
- Time windows – support for tumbling (non‑overlapping), sliding (overlapping), event‑based windows (last k events), and real‑time windows with continuous updates, providing maximum data freshness at the cost of higher processing load.
- Memory management – checkpointing mechanisms combined with offloading infrequently used profiles to disk ensure efficient memory utilization without compromising performance.
- Derived features – support for ratios, differences, and custom transformations implemented in Java when standard aggregations are insufficient.
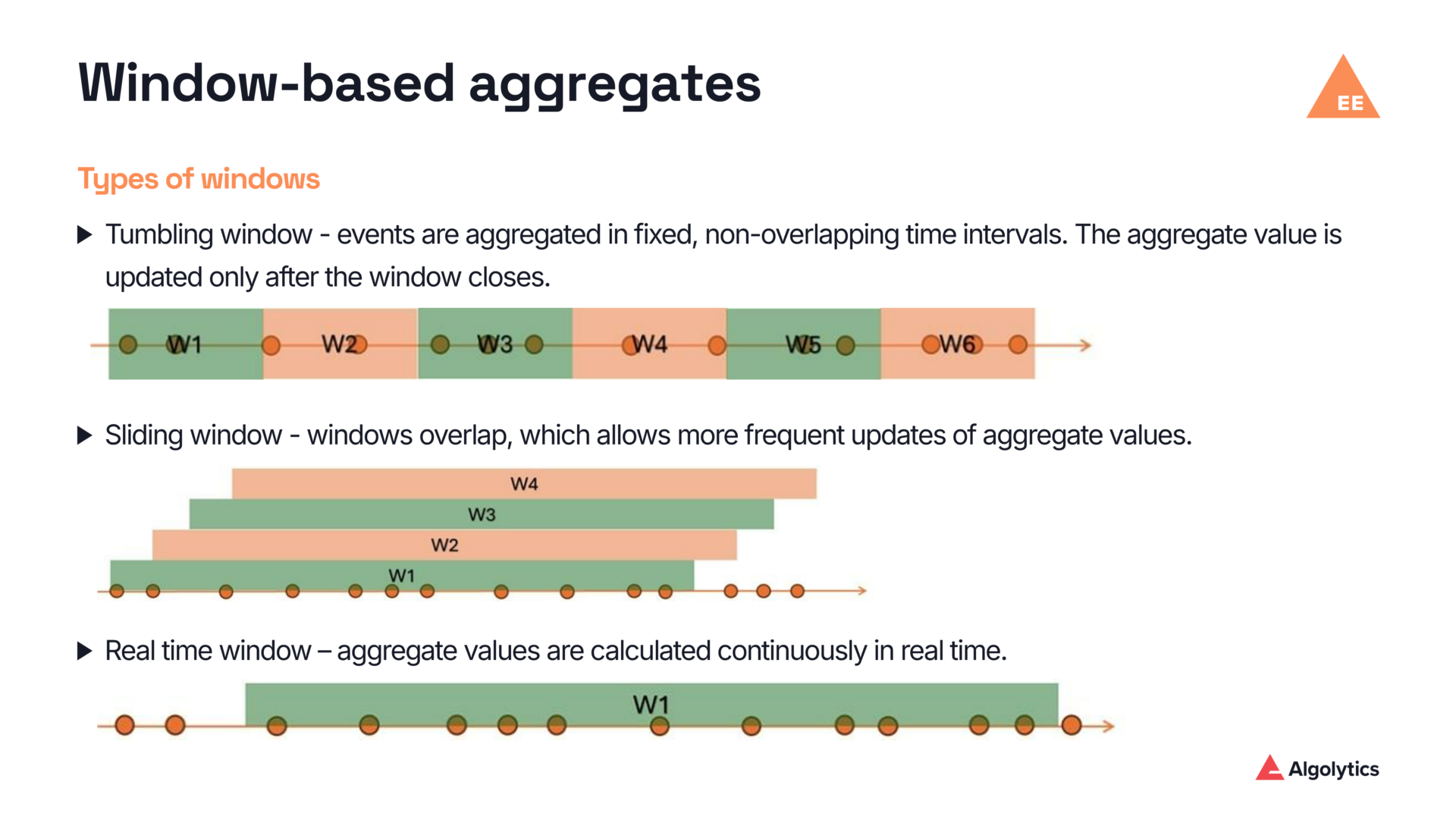
With this architecture, Event Engine enables scalable feature management while ensuring high data quality, security, and compliance with regulatory requirements.
Defining features in Event Engine (feature store) – variables, aggregates, time windows
Event Engine is configured through metadata that describes both the structure of events and the logic used to compute features. Each feature includes a metadata description that clearly explains its purpose and function, allowing users to quickly understand how a feature is used without analyzing raw data or production code.
Features stored in the feature store are defined with specific machine learning models in mind. Analysts and data scientists can create and manage these definitions without writing production code, while all feature definitions are stored in a centralized repository. This enables teams to reuse existing features consistently across multiple models and projects.
Primary variables
For a PageView event (example fields: url, timeOnPage, browser, sessionId, geo), primitive variables are defined using:
- Data ingestion from multiple sources, including real‑time streams, application logs, and tabular datasets from cloud services
- Support for multiple data formats in both streaming and batch processing
- JSONPath expressions referencing fields within the event payload
- Java‑based formulas/functions for transforming raw values
- Mappings and normalization rules
Versioning and metadata management in the feature store make it possible to track changes to feature definitions and their origin over time.
Example: the variable time_on_page_seconds extracts a value from a JSON field and converts it to seconds.
Generators
Aggregates are derived features maintained within an entity profile. A feature store can perform a wide range of aggregation operations, making it possible to create advanced features based on both historical and real‑time data. When defining an aggregate, the following elements are specified:
| Element | Description | Examples |
| Aggregation function | Type of aggregation operation | SUM, COUNT, AVG, MAX, MIN, DISTINCT_COUNT |
| Window type | Aggregation scope | Global, Time‑based, Event‑based, Current |
| Window size | Window length | 7 days, 100 events, 1 hour |
| Offset / lag | Time offset between windows | Aggregate from 24 hours ago vs current |
A feature store enables teams to discover existing features that can be reused across new projects, accelerating the creation of analytical datasets and improving consistency across machine learning models.
Examples of practical aggregates:
- Number of login attempts within a 10‑minute window
- Total transaction value over the last 30 days
- Average time spent on a page across the last five visits
- Maximum value of a single transaction over the entire history
Derived features
Event Engine (feature store) supports the creation of advanced feature types such as:
- Ratios / shares – the proportion of transactions coming from a specific channel relative to the total transaction volume.
- Differences – the difference between a current value and a historical reference value.
- Velocity features – measures the rate of change over time, for example a sudden increase in the number or value of transactions.
- Custom transformations – custom Java‑based logic used to transform raw data into feature values tailored for machine learning models when standard transformations are insufficient.
Automatic feature generation in feature store
A single command in the feature store can generate hundreds of aggregates based on a predefined pattern, enabling feature generation at scale. For example, a rule such as “for each numeric field in the event, compute count, sum, and average over 1‑hour, 24‑hour, and 7‑day windows” results in 90 aggregates created from just 10 fields—without manually defining each one.
By automating feature engineering, the feature store allows data scientists to build, test, and deploy machine learning models more quickly. This automation significantly accelerates the creation of training datasets and experimentation with new features.
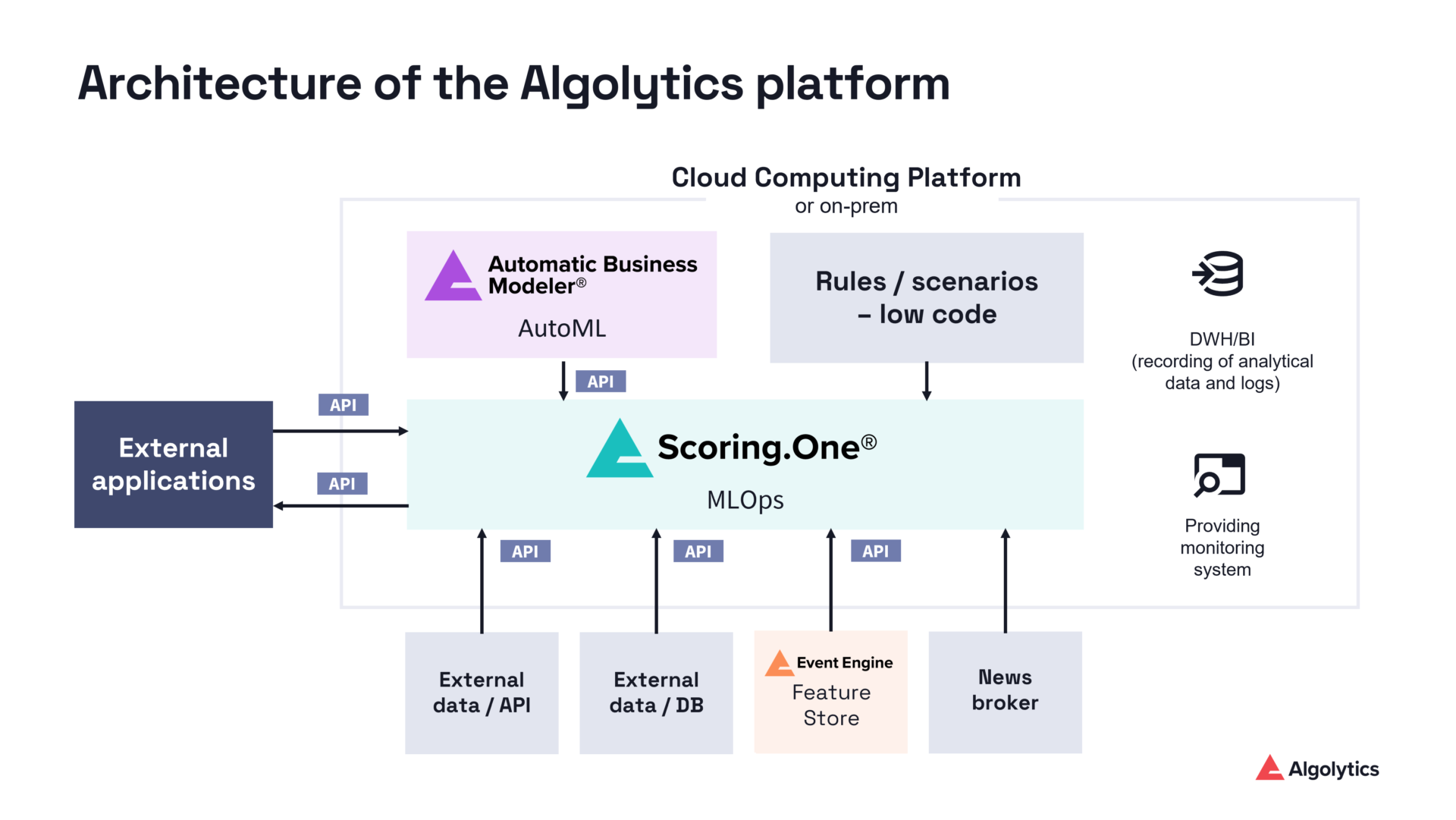
Integration of Event Engine (feature store) with MLOps Scoring.One
Role of Scoring.One
Scoring.One is a stateless scoring and decision engine that:
- imports machine learning models and allows decision rules to be defined,
- retrieves feature vectors from Event Engine (feature store),
- performs scoring based on features provided by the feature store,
- returns the decision or score to the calling system.
Statelessness means that Scoring.One does not retain user or entity context between requests. All state and historical context are maintained in Event Engine, which acts as the system’s memory.
Process flow
- Request – the client application (such as a transactional system or CRM) sends a request to Scoring.One, including various types of data delivered in both streaming and batch modes.
- Transformation – request data is mapped to the required internal format, enabling Scoring.One to handle heterogeneous data sources and structures.
- Event recording – the structured event is asynchronously forwarded to Event Engine via Kafka, where features are persisted as shared resources and made available for reuse across other processes.
- Profile update – Event Engine (feature store) updates the in‑memory entity profile, while also making existing features discoverable and reusable by other teams and models.
- Profile retrieval – Scoring.One retrieves the current feature vector (e.g. via the /profile?userid=X endpoint).
- Scoring – the machine learning model computes the result, such as fraud probability, credit decision, or recommendation.
- Response – the result is returned to the calling system within a few milliseconds.
Benefits of architecture
- Simpler scaling – Scoring.One is horizontally scalable through multiple instances, while Event Engine (feature store) manages state by continuously storing and updating user or entity profiles.
- Feature quality assurance – the feature store monitors feature quality and helps ensure consistency and reliability, which is critical for achieving high accuracy in machine learning models.
- Granular access control – support for multiple levels of data access, such as row‑level and column‑level permissions, enables fine‑grained security and compliance enforcement.
- Easy deployment of machine learning models – built‑in support for versioning, A/B testing, and monitoring within MLOps simplifies machine learning model lifecycle management.
Comparison of Event Engine (feature store) with other solutions (cloud, open-source, classic stream processing)
Classic stream processing engines (feature store)
Apache Flink, Spark Streaming, Kafka Streams, Apache Storm, SAS ESP:
- Highly flexible – real‑time data processing
- Not a feature store out of the box – no metadata repository, versioning, or feature lifecycle management
- High operational overhead – requires a large engineering team
- Feature store can be built, but takes months
Cloud‑based feature stores
AWS SageMaker FS, GCP Vertex AI FS, Azure FS, Databricks FS:
- Tightly integrated with the vendor’s cloud ecosystem
- Strong dependency on services of a single provider
- High costs at scale and with heavy real‑time traffic
- Limited on‑premise flexibility, which can be problematic for regulated industries (e.g. finance, public sector in Poland)
- Vendor lock‑in, making migration difficult
Event Engine (feature store by Algolytics)
- Combines feature store and stream processing in a single component, enabling feature management at scale.
- Flexible deployment – public cloud (Azure, AWS, GCP), on‑premise, or hybrid.
- Built‑in AutoML (ABM) and MLOps (Scoring.One) integration – a complete ML pipeline.
- Low TCO thanks to lightweight architecture and automation.
- Adapted to regulatory requirements and the local Poland/CEE market.
- Polish‑language support and knowledge of local regulations.
Feature store and stream processing comparison table
| Tool | Production‑ready | Streaming Feature Store | Aggregation automation | AutoML integration | Online scoring latency | Target user |
| Algolytics Event Engine (feature store) | ✔️ Yes | ✔️ Yes | ✔️ Full (metadata, windows) | ✔️ ABM | ✔️ < 5 ms | Data Scientist, ML Engineer |
| Apache Flink | ❌ No | Possible (custom) | ❌ No | ❌ No | ✔️ (with code) | Data Engineer, Developer |
| Apache Spark Streaming | ❌ No | Batch / micro‑batch | ❌ No | ❌ No | ❌ No | Data Engineer |
| Apache Storm | ❌ No | Yes (stateless) | ❌ No | ❌ No | ✔️ Very low | Developer (real‑time, IoT) |
| SAS ESP | ✔️ Yes | ✔️ Yes (GUI) | Limited (manual) | ❌ No | ✔️ Medium | Analyst, SAS team |
| Feast | ✔️ Yes | ✔️ Yes | ❌ No | ❌ No | ✔️ (Redis‑based) | Data Engineer (ML platform) |
| Hopsworks | ✔️ Yes | ✔️ Yes | ❌ No | Manual | ✔️ Low | ML Engineer, AI team |
| Databricks Feature Store | ✔️ Yes | Spark‑based | ❌ No | ✔️ MLflow | Seconds | ML Engineer, DevOps |
| Tecton | ✔️ Yes | ✔️ Yes | ✔️ Yes | ✔️ Yes | ✔️ (Redis, DynamoDB) | ML Platform Engineer |
| Vertex AI Feature Store | ✔️ Yes | ✔️ Yes | ❌ No | ✔️ Vertex AI | ✔️ Low | ML teams (Google Cloud) |
| Qwak | ✔️ Yes | ✔️ Yes | ✔️ Yes | ✔️ Yes | ✔️ Low | ML Platform, MLOps |
| Nussknacker | ✔️ Yes | Possible (integration) | Limited (UI) | ❌ No | REST‑based | Business Analyst, Decision Architect |
Re‑creating Event Engine (feature store) functionality using hyperscaler services – estimated setup cost: ~300 MD
Event Engine (feature store) combines real‑time event processing, feature management, and ML automation - covering both online and offline workloads - in a single component. Re‑creating comparable functionality using hyperscaler platforms (AWS, GCP, Azure) requires integrating multiple cloud services, resulting in high implementation and maintenance costs, estimated at around 300 MD (man‑days).
Below is a comparison of a typical set of services required to build feature‑store‑like functionality across the three major public cloud platforms.
| Cloud | List of services | Number | Additional production services | Additional services (min.) | Typical total |
| AWS | Kinesis Data Streams, (optional Firehose*), Lambda (consumers), DynamoDB (profiles), API Gateway (REST), S3 (data lake), Athena (reporting) | 6–7 | CloudWatch + X‑Ray, WAF, KMS, Glue (catalog/ETL), Lake Formation (governance) | 4–5 | 10–12 |
| GCP | Pub/Sub, Dataflow (Beam), Bigtable (profiles), Cloud Run (API), API Gateway/Endpoints, BigQuery (storage & SQL) | 6 | Cloud Armor (WAF), Cloud Monitoring & Logging (Ops Suite), Secret Manager + KMS, Data Catalog | 4–5 | 10–11 |
| Azure | Event Hubs, Stream Analytics, Cosmos DB (profiles), App Service (API), API Management (gateway), ADLS Gen2 (data lake), Synapse Serverless (SQL) | 7 | Front Door + WAF, Monitor + Log Analytics, Key Vault, (optional Event Hubs Capture*), Data Factory / Databricks (ETL) | 4–6 | 11–13 |
Such a complex architecture requires significant effort not only for configuration and integration, but also for ongoing maintenance and monitoring. As a result, total setup and development costs can be very high, which positions Event Engine (feature store) as a competitive, integrated alternative with lower TCO and full control over the machine learning feature and model lifecycle.
Example feature store use cases with Algolytics – ML‑driven processes
Below are selected end‑to‑end scenarios illustrating how Event Engine and Scoring.One are used in practice across areas such as credit scoring, fraud detection, marketing optimization, and sales forecasting.
In each scenario, features are used for model training, production scoring, and ongoing prediction quality monitoring.
Scenario 1: Online credit scoring for B2C customers
Background: Bank offering online consumer loans
Flow:
- The customer submits a loan application via a mobile app or website.
- Application data is sent as an event to Event Engine (feature store), supporting multiple data sources and feature engineering scenarios.
- Event Engine updates the customer profile by aggregating data from repayment history, card usage, and demographic information.
- External data (e.g. from BIK) is fetched and added to the profile.
- Scoring.One retrieves the feature vector from Event Engine and performs real‑time scoring.
- The credit decision (approval, rejection, or referral to an analyst) is returned within seconds.
Typical features: repayment history, credit limit utilization, number of applications in the last 30 days, employment stability, spending patterns.
Scenario 2: Card transaction fraud detection
Context: Payment operator or bank processing card transactions
Flow:
- Each card transaction is sent to Event Engine (feature store) as an event.
- The system computes features such as transaction counts over the last 5 minutes and 24 hours, geographic distance between consecutive transactions (location intelligence), merchant or terminal type, and unusually high amounts. Raw data is transformed into features.
- The anti‑fraud model in Scoring.One evaluates the probability of fraud.
- Decision: authorize the transaction, suspend it, or flag it for further verification.
- End‑to‑end latency: tens of milliseconds.
Typical characteristics: transaction velocity, geolocation, deviation from the user’s normal behavior pattern.
Scenariusz 3: Real-time marketing in e-commerce
Context: E‑commerce platform with personalized recommendations
Flow:
- User interactions from the application (view, add_to_cart, purchase) are streamed to Event Engine (feature store).
- The feature store computes activity‑based features such as viewed product categories, abandoned carts, and time since last purchase.
- Large‑scale feature management across different types of marketing data enables efficient storage, discovery, and reuse of features in both streaming and batch modes.
- Recommendation models or business rules in Scoring.One analyze the customer profile.
- A personalized offer (product recommendation or discount coupon) is returned during the user session.
- Conversion rates increase as a result of relevant, real‑time recommendations.
Typical features: recently viewed categories, cart value, visit frequency, price sensitivity.
How to get started with a feature store and Event Engine in your organization
Implementation steps
- Identify a priority use case – choose one scenario with clear P&L impact (fraud detection, credit scoring, churn prediction, recommendations).
- Inventory data sources – map available online data (application logs, transactional events, streams) and offline data (CRM, data warehouses, billing systems, spatial data).
- Choose deployment architecture – cloud, on‑premise, or hybrid, taking into account regulatory requirements, security policies, and existing infrastructure.
- Design initial features – define primary variables and aggregates in time windows. Start with 20–50 features, not thousands, and leverage domain expertise.
- Integrate the scoring engine – connect Event Engine (feature store) with Scoring.One or existing tools and validate performance against target SLAs (e.g. < 50 ms per decision).
- Run a pilot – deploy on a limited subset of users or transactions and monitor model quality, feature stability, and latency.
- Scale – after pilot validation, extend to additional ML models and business domains (credit → fraud → marketing → sales forecasting).
Best practices for feature store implementation
An effective feature store implementation requires clearly defined design principles.
Design features for reuse
The feature store should act as a central feature library that enables features to be reused across multiple models and projects. Treating features as shared, reusable assets helps eliminate duplicated work, shortens model preparation time, and improves consistency of machine learning solutions across the organization.
Ensure consistency between training and production scoring
One of the key principles is using the same feature definitions during model training and in production. Inconsistent feature definitions lead to data discrepancies, known as training‑serving skew, and result in prediction errors. A feature store should rely on a single feature computation mechanism and a single source of truth.
Share a feature catalog
A feature store should provide a feature catalog enriched with metadata, descriptions, and information about feature usage in models. This simplifies feature discovery, promotes reuse, and improves collaboration between data science, data engineering, and IT teams.
Support online and offline processing in one system
A well‑designed feature store must support both real‑time (streaming) processing used for production scoring and batch (offline) processing required for training datasets and historical analysis. Supporting both modes within a single system simplifies the overall architecture and reduces tool sprawl.
Apply granular data access control
Feature stores often operate on sensitive data, making granular access control essential. Mechanisms such as row‑level and column‑level permissions help ensure data security and compliance with regulatory requirements.
Interested in seeing how Event Engine (feature store) and the Algolytics platform can work in your organization?
Contact us to schedule an architectural workshop or a proof of concept. We’ll help you identify the most valuable use case and design an implementation tailored to your needs - whether you operate in banking, telecommunications, e‑commerce, or any other domain that requires real‑time decision‑making.



