













With the growing popularity of machine learning, enterprises are increasingly recognizing that the biggest barrier is not creating and training models, but their real implementation and maintenance in production environments.
In many companies, AI projects start with great enthusiasm: the team finds a sensible idea for the use of technology, builds a high-quality model and shows that such a solution can really support the business.
However, when it comes to moving from prototype to production, the team is confronted with multi-layered IT architecture, distributed data sources, and integration difficulties – at this stage many initiatives begin to break down.
What's more, even if the team manages to get the project to implementation, the operation and maintenance of the solution itself turns out to be just as problematic. Changing one function, correcting a model parameter or adding another pipeline element requires going through the entire implementation cycle again. In practice, this means that even a minor modification can become an expensive, multi-step process that slows down development.
In this article, you'll learn how to simplify and accelerate the adoption of ML models.
The real needs and limitations of the organization
The study "Maturity of Polish companies in the area of data and AI" conducted by Algolytics in cooperation with SW Research shows that only a small number of companies actually use machine learning in production. This is not the result of a lack of motivation - most organizations see the potential of AI. The problem lies in competence barriers and insufficient budgets.

The situation is further complicated by the fact that the traditional approach to implementing ML models involves many roles: from data scientists, through data engineers, to DevOps specialists and system architects. Each of these groups is responsible for a different stage of work and requires specialist competences, which makes it necessary to build large, multidisciplinary teams.
Organizational challenges are also compounded by significant technical barriers, which in practice make ML implementations more difficult and time-consuming than teams at the prototyping stage can assume:
- Large training data sizes - processing huge data sets requires a lot of computing power and limits the pace of experimentation.
- Complex integrations with data sources - connecting multiple, often heterogeneous and distributed systems is time-consuming, costly and error-prone.
- Poor data quality and lack of effective validation mechanisms - erroneous or incomplete data reduces the effectiveness of models and increases the risk of wrong business decisions.
- Too long system response time or long batch processing - high latency makes it difficult to use real-time models, especially in processes that require immediate decisions.
- High labor intensity of implementing changes - each modification of the model, function or pipeline requires extensive coordination and re-going through the implementation stage, which slows down iterations.
- Difficult evaluation and monitoring - the lack of central tools for monitoring the quality of models causes that the detection of model degradation is delayed and often manual.
All this is compounded by the technological limitations of computing environments. The most popular environment in the ML ecosystem - Python - despite its flexibility, has fundamental barriers to scalability.
Global Interpreter Lock* prevents true parallel processing in a single process, and scaling requires duplication of the entire environment, which generates higher memory consumption and increased latency. As a result, organizations often have to maintain multiple instances of an application just to bypass these technical limitations.
* Global Interpreter Lock (GIL) is a mutex in CPython (the standard Python interpreter) that ensures that only one thread executes bytecode of Python code at any given time - even on multi-core processors - to protect memory management mechanisms. While this simplifies memory management and improves performance in single-threaded mode, it creates a bottleneck for CPU-intensive tasks that are executed multithreaded, preventing Python code from actually executing in parallel.
From a complex toolset to a unified runtime
The key to breaking these barriers lies not in adding more services or mechanisms, but in simplification. The greatest efficiency gains can be achieved by creating an environment that performs the full scoring process within a single, consistent application. Instead of building dozens of microservices, it is worth betting on a monolithic execution engine equipped with lightweight, modular processors that handle individual steps: data retrieval, transformations, model run, rule calculations and decision logic.
The use of an architecture based on asynchronous event processing allows you to handle multiple pipeline instances at the same time, without blocking each other's tasks. The data goes to the engine and flows through subsequent processors as if through a stream of events, and each element reacts when it is needed. This allows the system to simultaneously retrieve data from databases and APIs, perform transformations, run models, and aggregate results, making full use of infrastructure resources.
This approach opens the way to the implementation of even very complex analytical applications - from simple classification models, through recommenders using hundreds of parallel models, to intelligent agent-based solutions combining language models, scraping data from the Internet and near-real-time analysis of offers.
Performance that makes a difference
One of the key factors determining the cost and scalability of ML systems is computational time. In an architecture based on lightweight, compiled model implementations instead of classic Python libraries, it is possible to achieve significant resource savings. When a model is represented as directly executable code, such as in Java, costly interpretations and the need to load dependency sets are eliminated. Such a model performs fast arithmetic operations without unnecessary overhead.

In benchmarks, the differences in operating costs turned out to be significant. Popular open-source tools and cloud solutions showed maintenance costs up to 23 times higher compared to Algolytics' MLOps platform. This difference is not due to the model itself, but to the entire execution ecosystem: the elimination of redundant containers, libraries, dependencies, communication overhead, and the lack of precise use of hardware resources.
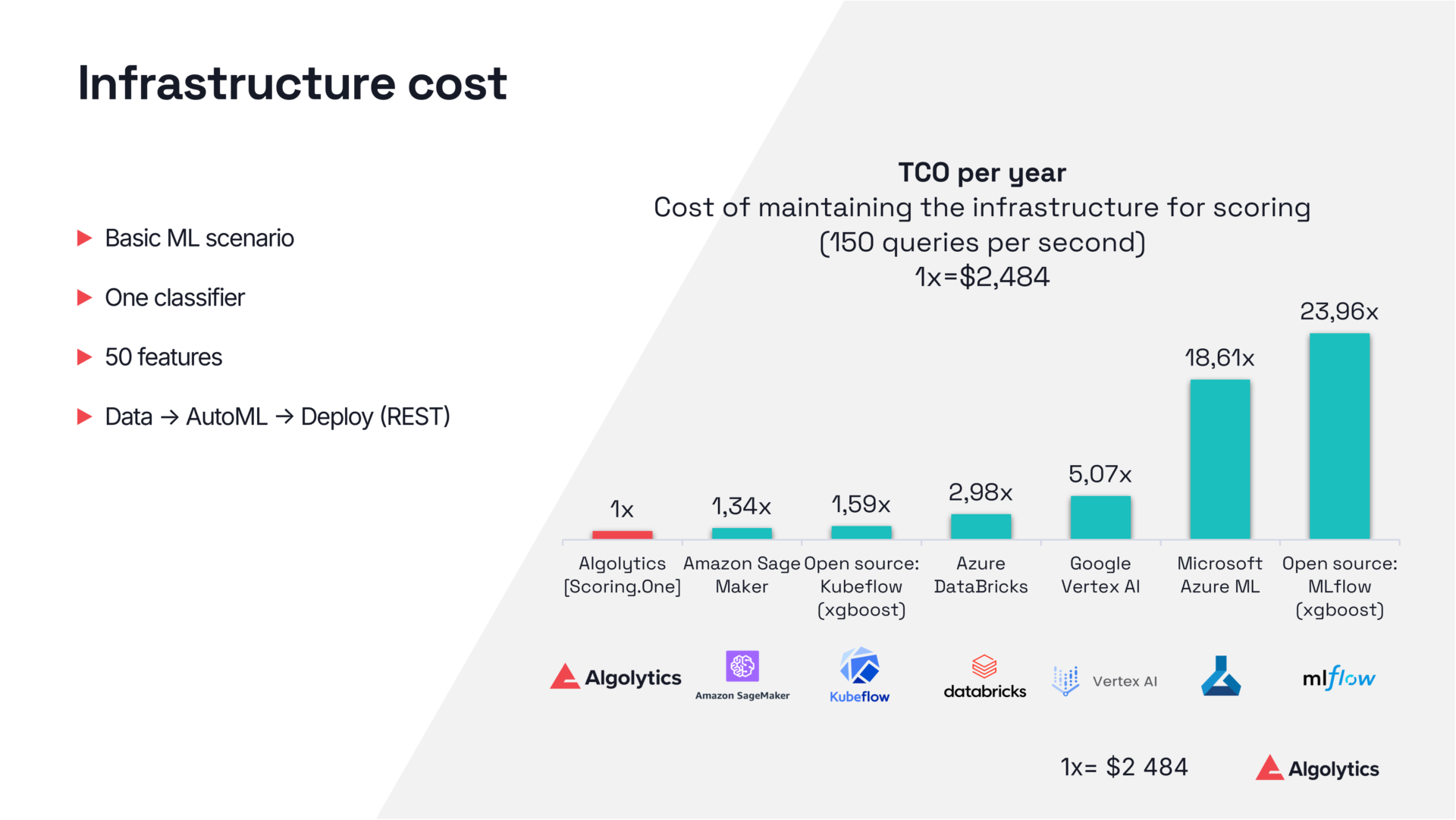
Equally important is the approach to automatic model building. Classic AutoML systems create complex constructs with multiple layers and ensembles that can be difficult to deploy at scale. The use of heuristics that promote simpler models leads to a situation where performance is significantly higher with minimal loss of prediction quality. Focusing on inference time instead of maximum accuracy gives a real advantage in systems operating under heavy loads. This is the approach we took in our AutoML solution.
Modeling complex ML applications without code
Another important element is the availability of a working environment that allows you to build, debug and deploy complex ML applications without having to write extensive code. Design interfaces that enable visual pipeline building, data integration, step-by-step testing, and version control allow a single person to prepare an application in a short time that would require weeks of work by the entire team in a classic approach.
A scenario designer with modules for data retrieval, transformation, model run, integration with external systems, or error handling allows you to build complex flows in an intuitive way. Even tasks that require code can be performed in lightweight scripts, without the need to build separate microservices or environments. Debugging is done in real time, allowing you to analyze the results at every step and correct errors immediately.
This makes the deployment process iterative and fast. Pipeline versioning, validation, and instant model publishing make the ML deployment lifecycle much shorter, enabling you to respond faster to changes in data and business needs.
Scaling in practice
The most measurable proof of the effectiveness of a simplified architecture is its behavior under heavy load. Based on the Algolytics platform, we are able to maintain several thousand models and scenarios on one instance of the Scoring.One application, operating in near real time, without a visible decrease in performance.
This allows businesses to move away from costly server farms and complex autoscaling mechanisms. An efficient computing unit turns out to be sufficient to handle traffic with a volume of several thousand queries per second. Instead of expanding the infrastructure, the organization gains an environment that is optimized to operate in a high bandwidth regime.
Summary: The future of MLOps is simplified complexity
Machine learning is no longer a niche technology and is becoming a critical component of modern IT systems. However, in order for it to be widely implemented, it is necessary to move away from multi-layered, difficult-to-maintain tool ecosystems. The greatest value today is not the multitude of components, but a coherent and effective environment.
The architecture of a monolithic, asynchronous execution engine, lightweight compiled models, the simplicity of AutoML, flexible design and debugging tools, as well as the ability to run hundreds of models in parallel without the need to expand the infrastructure - these are the foundations of modern MLOps.
This approach allows organizations with limited resources to step up to advanced predictive analytics and build large-scale AI applications faster, cheaper, and more confidently. The effectiveness of such solutions does not result from raw, expensive computing power, but from a well-thought-out architecture and a conscious reduction of complexity where it does not add value.
Learn more about successfully implementing machine learning in your organization:



