













In Scoring.One, we have introduced a functionality that significantly changes the way we work with Python models and scripts. The new environment architecture allows you to run code in multiple independent versions of Python with different libraries and configurations. This means greater flexibility, security, and predictability in machine learning deployments in manufacturing.
This solution was created as a response to the growing needs of organizations that develop increasingly complex scoring processes and require stability, scalability and full control over the execution environment.
How at Scoring.One we combine different technologies and scripting languages in one data processing process
One of the basic distinguishing features of Scoring.One is the ability to implement and use ML models and algorithms created in various technologies. Currently, Scoring.One supports models built in:
- Algolytics platform (scoring code implemented as a Java class)
- Python
- R
- PMML
In the scenario editor, it is possible to use all of the above elements and fragments of code prepared in Groovy/Java, Python or R. Importantly, in one scenario you can use any number of models and script elements prepared in different technologies.
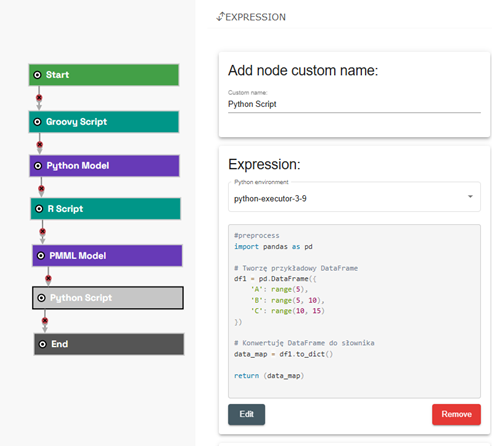
What are the new Python environments in Scoring.One?
The new Python executors are independent containers responsible for running Python scripts and models in isolated environments. Each worker has:
- your own version of Python (e.g. 3.7, 3.9, 3.12),
- an individual set of libraries,
- own runtime configuration,
- automatic registration mechanism in Scoring.One.
This allows you to maintain multiple environments in parallel without worrying about library conflicts or differences between the training environment and production.
For whom and why is it important?
New Python environments are especially important for organizations that work with multiple ML models in parallel and develop them across different technology stacks. The most benefits will be noticed by:
Banking and finance
Many scoring and anti-fraud models work in parallel, and each may require different dependencies.
Telco and the subscription industry
Churn, propensity, and recommendation models often use different ML libraries that are difficult to maintain in a single environment.
E-commerce and marketing
Dynamic testing of new variants of predictive models requires full isolation of environments.
Public sector
Stability and transparency of models is key - isolation of environments minimizes risk.
Thanks to Python workers, teams get:
- full flexibility in the choice of technology,
- predictability of implementations,
- higher safety of models,
- no library conflicts between projects.
How does the Python worker architecture work?
To provide full control over the runtime, Scoring.One uses separate execution units.
Workers communicate with the platform through a set of endpoints:
- /register – registering a new environment,
- /compute – run Python models,
- /compute/python – running Python scripts,
- /health – monitoring the status of the service.
The Scoring.One engine automatically selects the right environment for a given model based on its configuration. This makes the entire process scalable and predictable.
Choosing a Python environment
A new environment parameter is available:
- in the GUI – when implementing the model and configuration of the expression node,
- in the API – by downloading the list of available environments:
GET /api/python/environment
This allows you to create models in one environment and run them in another, or test multiple variants in parallel.
Deploying Python models in practice
The process of deploying Python models remains simple, but benefits from the ability to choose the runtime. The ZIP package with the model should include:
- Python script with logic running the model/algorithm,
- Input metadata file
- Pickle/dill file with the ML model.
When deploying, the user indicates the environment in which the model is to be executed. This guarantees repeatability and compliance with the training phase.
Data handling and serialization
Python workers support a wide range of data types used in data science:
- Pandas facilities,
- NumPy tables,
- SciPy rare arrays,
- Python date and numeric types,
- standard JSON.
The conversion is done automatically, you don't need to create your own serializers.
Error handling
The system presents the full tracebacks, the location of the error, and the execution context. This makes it easier to diagnose problems and shortens repair time.
Scaling environments – on-premise, cloud and hybrid
Thanks to the modularity of the workers, they can be run in any infrastructure:
On-premise
Full control over the infrastructure, especially in regulated organizations.
Cloud
Flexibly scale environments, deploy quickly, and automate.
Hybrid
A combination of the advantages of both approaches: locally critical models, experimental models – in the cloud.
How to implement new Python environments – step by step
To get started quickly with the new architecture, it's a good idea to go through a short list of steps:
- Define the environment requirements (Python version + libraries).
- Prepare an image of the container.
- Test the model locally.
- Run the worker in the target environment.
- Wait for its automatic registration on Scoring.One.
- Select an environment when deploying the model.
- Perform final integration tests.
This approach is fast, secure, and scalable.
FAQ – frequently asked questions
Can I mix models running on different versions of Python?
Yes - each element of the scenario can run in a different Python environment.
How do I check the list of available environments?
Via GUI or API (GET /api/python/environment).
Can a worker run on another server?
Yes - provided they have access to Scoring.One.
What data types are supported?
Pandas, NumPy, SciPy, datetime, JSON, and many more.
Summary
The new Python environments in Scoring.One give you full flexibility and control over the process of executing Machine Learning models. They allow you to build and maintain complex scoring processes without worrying about library conflicts, environmental stability or infrastructure scalability. This makes working with ML models simpler, faster, and more predictable - regardless of the number of deployed models and their complexity.
Want to better understand how Scoring.One supports building, deploying, and scaling Machine Learning models? Explore all the capabilities of the platform and the architecture of operation.



