













Challenges of user identification in cookie-based models
In web analytics, as well as in many specific applications (e.g. fraud identification), it is crucial to recognize unique users visiting the website correctly. In practice, however, the same person often uses multiple devices – for example, a smartphone, tablet, and computer – that appear to be separate users from the point of view of analytical systems. Without additional mechanisms, each browser or device receives its own identifier (so-called cookie), which means that the same person on different devices is counted multiple times. This results in inflated visitor statistics and distorted data on customer behavior – e.g. one person using a phone and a laptop would be treated as two different users.
Clearing cookies or using private mode is an additional challenge. Many Internet users regularly delete cookies or block them for privacy reasons. As a result, after clearing the browser data, the returning user receives a new ID and is again seen as a "new" visitor.
Unification of identity as a prerequisite for correct AI analyses and models
From a business perspective, this distorts cohort analysis, conversion path tracking, and attribution models – for example, it's difficult to assess the actual number of returning customers or attribute the impact of individual marketing channels to a single person.
Input data to machine learning models also loses quality, because the behavior of one user is dispersed among many artificially created identities. Therefore, a solution is needed that, despite these difficulties, will allow for unambiguous identification of the user (or household) in the multi-device world and, despite the deletion of cookies – so that user statistics are reliable, and predictive models and marketing campaigns operate on accurate data.
What is the Identity Graph?
The solution to these problems is the concept of the Identity Graph. In simple terms, it is a graph database that stores relationships between different identifiers that can represent the same user. Nodes in a graph are various types of identifiers related to online interactions:
- unique device or browser identifiers (e.g. cookies assigned by the website),
- device fingerprints,
- IP addresses,
- Login IDs (e.g., the logged-in user's UUID or email address)
The identity graph built by Algolytics integrates the above elements. Each node represents a specific identifier, and the edges of the graph reflect the observed relationships between them – for example, the fact that a particular cookie appeared from a specific IP address, or that a certain device fingerprint was associated with several different cookies.
The graph structure allows you to discover connections even between seemingly distinct identifiers. For example, if user A first visited the page on a phone (cookie X, fingerprint F1, IP1) and then on a laptop (cookie Y, fingerprint F2, IP1), then the graph will capture the common address IP1 and perhaps other features as a link, suggesting that X and Y are the same person. Another example is when a user logs in on one device – then their account ID is associated with a cookie and fingerprint from that session, which will add edges between these identifiers in the graph. Over time, the identity graph grows, grouping identifiers into components corresponding to real individuals (a person or a household).
Crossuid mechanism – consolidation of user identity in analyses
The associated identifiers are given a common group identifier – in Algolytics, called crossuid (it can be understood as an anonymous identifier for a user or household). It is the crossuid that is the target key used further in analytics instead of individual cookies or devices. Thanks to this, instead of three separate records for a user on a phone, a user on a laptop and a user on a tablet, we get one merged profile (crossuid) to which all actions of this user are assigned
Identity graph as a map of user relationships
The identity graph, therefore, acts as a map of relationships – its nodes (cookies, logins, fingerprints, IPs, etc.) connected by edges form networks corresponding to unique users. When the graph is fed with enough data, it can effectively combine and consolidate fragmented user information from different sources, providing a consistent view of the customer across all online channels. This approach is increasingly used in marketing and analytics – from CDP platforms to anti-fraud solutions – now also available as a ready-made component of the Scoring.One platform.
Device fingerprinting
One of the important elements of the identity graph is device fingerprinting, i.e. a technique of identifying a device based on its characteristic features. A browser's fingerprint is in practice a unique hash calculated by a script based on several information revealed by the browser are taken into account, the User-Agent header (containing the browser and operating system version), screen resolution, list of installed fonts, time zone, language, and even such niche parameters as the Canvas API test result or AudioContext. Many of these parameters in a single combination are unique to a given device, so that the resulting fingerprint acts as a digital "fingerprint".
Importantly, the fingerprint ID is not stored on the user's side, so it is not subject to simple cleaning like cookies – each time it can be recalculated from the current browser properties.
Fingerprinting – a resilient method of user identification despite cookie deletion and IP changes
Thanks to fingerprinting, we can recognize a user even if they change their IP address or clear their cookies. For instance, if a user regularly deletes cookies, they receive a new one on their next visit. However, the characteristics of their browser and device—such as the same set of plugins, screen resolution, fonts, and other attributes—typically remain unchanged. The system generating the fingerprint will detect that the new cookie shares the same device fingerprint as a previously observed user, indicating it is likely the same person. As a result, a fingerprint node will be created in the identity graph and connected by edges to both the old and new cookie nodes—effectively merging the two sessions into a single identity.
The use of fingerprinting in marketing and cybersecurity
Similarly, fingerprinting helps to combine activity from different browsers on the same device – although here the effectiveness is sometimes lower, because not all features (e.g. the list of plugins) are shared between different browsers. Nevertheless, fingerprinting is a powerful complement to classic identification methods, increasing the system's resistance to typical tracking procedures (such as incognito mode or ad blockers). It is worth noting that this approach is used not only in marketing analytics, but also in security – e.g. online banks use fingerprint devices to detect unusual logins (a different computer than usual) for multi-factor authentication
Scoring.One - orchestration of the entire process
The described identity graph has been implemented as part of the Algolytics Scoring.One platform – a universal engine for real-time data and event processing. Scoring.One is an integrated MLOps environment that combines stream data processing, scoring, and predictive analytics in a single system.
The platform allows you to deploy models and complex decision scenarios in days instead of months, processing thousands of queries per second for dozens of concurrent rules and models. In other words, Scoring.One can receive events in real time (e.g. events from a website, transactions, system logs), calculate defined features, ratings or business decisions based on them, as well as take feedback actions (e.g. return a response via API or update certain data in the database).

Real-time identity graph: Scoring.One architecture and operation
The scheme of operation of the algorithm is as follows: with each user interaction (e.g. a page view), Scoring.One registers an event and triggers an analytical scenario (the so-called scoring scenario). This scenario enriches the event data with additional information (e.g., geolocation and network data based on the user's IP) on the fly and updates the graph in the graph database. The platform allows you to define complex rules, thanks to which each subsequent observation (page entry, click, etc.) immediately affects the state of the identity graph.
What's more, Scoring.One provides an API for querying in real time – for example, you can send a query with a cookie ID, and the system will return the crossuid assigned to it, found based on the current state of the graph. All of these operations are highly optimized for performance, so you can interactively combine user data in a fraction of a second, even with hundreds of thousands of events moving daily.
Data validation and enrichment modules in Scoring.One
Thanks to the flexibility of Scoring.One, we have created a rich ecosystem of integrations – e.g. ready-made modules for data validation and completion (address geocoding, company verification), integrations with external databases (e.g. financial databases, address databases, etc.), or the ability to implement your ML models.
Integration with external IP address data sources is an important element. Scoring.One can retrieve information about a given IP on the fly, for example, geolocation (country, city), name of the organization/operator and type of link. This was used both to filter out bot traffic and to define rules for connecting devices in the graph – details described below.
User Identity Resolution Process
One of the functionalities provided by Scoring.One is a configurable tracking script that allows for quick and easy integration of algorithms that download data and send it to Scoring.One with the web portal.
Below is a step-by-step guide to how Algolytics identifies a user based on successive web events and assigns them a common crossuid:
Event capture and bot filtering
When Scoring.One receives a new event from a website (e.g., a tracking script call), The first step is to exclude bot traffic. The system checks the source IP address – if it is on the internal list of known robots (e.g. Googlebot scanners, Bing, Facebook crawlers, etc.), the event is rejected already at the level of the tracking scenario. In addition, after enriching IP data with information about geolocation, operator or type of connection, another filter is used: events in which the name of the telecommunications operator indicates large technology companies or cloud providers, typical for automatic traffic, are rejected. For example, traffic coming from addresses belonging to Apple, Google, Microsoft, Yandex, or Facebook will be ignored. Such addresses often generate hundreds of entries with unique cookies (a typical bot trace), which, if not filtered, would artificially generate a graph with millions of false connections and nodes.
Adding/updating an IP node
If the event comes from a real user, the platform registers their IP address (IP node) in the graph. IP addresses can be both home, business, and mobile addresses – and each of these types requires different treatment. The system labels IP addresses with attributes such as connection type, provider/service (ISP or organization), etc., which helps in making further decisions. Mobile addresses have been given a special separation logic: if the same mobile IP appears again within 48 hours, we assume that it may still be the same subscriber using the mobile operator's address pool – then we update the timestamp of the existing IP node. On the other hand, if more than 48 hours have passed since the last use, we treat the same IP as new, creating a separate node. This prevents the graph from combining strangers to whom the operator has assigned the same address, e.g. a week apart. This prevents the networks (graph components) from growing uncontrollably as a result of the dynamic rotation of IP addresses typical of mobile networks.
Linking cookies to IP
At the same time as identifying the IP, the system processes the cookie IDs present in the event. As standard, Algolytics uses its own tracking cookie (called ext_sceuid) and may also retrieve other session identifiers (e.g. Google Analytics cookie ga, sessionid, etc.). For each such identifier, a cookie node is created (if it does not exist) in the graph. Edges are then added to connect the cookie to the current IP node. Such an edge stands for "cookie X was seen at IP address Y" and is the first indication of a potential shared identity with other cookies appearing on this IP.
Add a device fingerprint
If a generated device fingerprint is present in the event, it is also included. The system creates a fingerprint node (e.g. on the basis of a provided browser identifier generated using a fingerprinting library) and binds it edge-to-edge with the cookie and IP node. As a result, a tripoint is created in the graph: IP – cookie – fingerprint, which means "cookie X and fingerprint F occurred together on IP Y". If the user clears the cookies and gets a new cookie X2, but fingerprint F remains the same, in the next event a connection X2 – F – Y will be created, and since F has already connected to X, a path connecting X to X2 will be built in the graph (through a common fingerprint). This will allow you to recognize that X2 is the same user as X, even though you have lost the cookie.
Binding the ID of the logged-in user
In a situation where the user is logged in and the event contains his permanent ID, the graph also records this. A login/algolytics_uuid node is created or updated, which is then associated with the previously created cookie node. In practice, this means, for example: "cookie X belongs to the logged-in user Jan Kowalski (user123)". Thanks to this, if the same John Smith ever logs in on another device (different cookie, fingerprint, IP), the system will quickly consolidate these sessions – in the graph, both cookies will have a common login node, so they will be in one component of the identity.
Assign a common identifier (crossuid)
The above operations add new nodes and associations to the graph. The last step is to determine whether the network that is just appearing has its group ID (crossuid) already assigned. To do this, the system checks whether a crossuid node within a radius of up to 10 edges in the graph is already connected to a given cookie node (considered as a starting point). Graph search ignores connections of the Corporate type, i.e. connections via the corporate/corporate network. This is to prevent the combination of many users into one group, who have appeared at the same address (e.g. in the office or café), but otherwise have no connection to each other. If a crossuid node is within range of 10 edges, it is assumed as the group identifier for the current device. On the other hand, if there is no crossuid for this subnet of associations yet, the system will create a new crossuid node and associate it with the analyzed cookie. Thus, the entire newly created component of the graph (e.g. including cookies, fingerprint and IP of a given user) is marked with a fresh group identifier. Each crossuid is a unique UUID and represents a separate group of devices in the graph, which – depending on the context – can be identified with a single anonymous user or just a household.
User ID on Demand – How the Algolytics API Works
At this stage, the platform can return the result to the customer, e.g. via an event API or a method in JavaScript, so that further interactions can already use this merged identifier. Algolytics has a dedicated scenario that provides an HTTP API to get crossuid on demand.
For example, calling the API with a specific Algolytics cookie (ext_sceuid) or session fingerprint will query the graph database for the appropriate crossuid. In response, the service returns a unique crossuid in UUID format, along with any additional metadata (e.g., creation date).
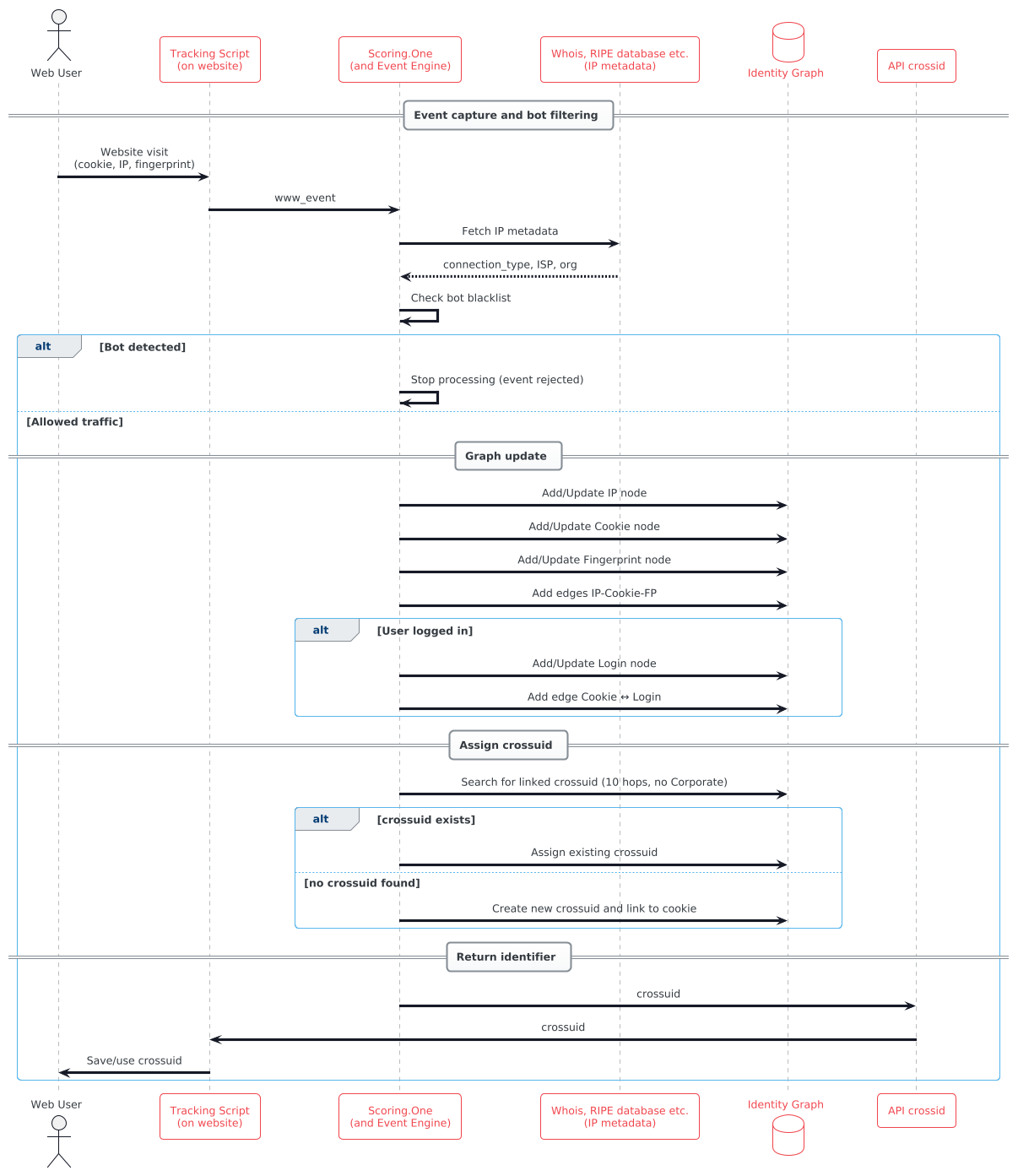
This identifier can then be used on the frontend side (e.g. stored in the local browser database) or forwarded to further analysis systems as a stable user key. Importantly, one person is always assigned the same crossuid (as long as there is some path of association between their devices), so even after a long time, you can recognize a returning customer. If, on the other hand, a potentially very complex graph occurs (e.g. a network of connections pointing to a bot that generates thousands of connections), the system has protection mechanisms – e.g. a time limit of 10 seconds for a graph query and the selection of the oldest crossuid in the event of a collision detection.
Application examples and benefits
The described solution – combining graph identification with the capabilities of Scoring.One – opens up a number of possibilities for practical use in business. Below are some key uses and benefits:
More accurate web analytics
With the identity graph, metrics such as the number of unique users, frequency of visits, and conversion paths become more reliable. Eliminating duplicates (caused by multiple devices or resetting cookies) means that KPIs – e.g. average number of sessions per user, customer lifetime – reflect the actual behavior of one person, rather than the sum of several pseudo-identities. This allows companies to better assess the effectiveness of marketing and product activities.
Better ML modelling and personalization
Consolidation of user data translates into richer profiles with more attributes and a longer history of behavior. Machine learning models (e.g. for recommendations, churn prediction or fraud risk assessment) can use a more complete picture of customer activity. This improves their prediction accuracy because we eliminate the "noise" in the form of distorted data (e.g., the model no longer confuses one user with three). Additionally, crossuid can serve as a stable key to combine data from different sources (e.g., transactional, CRM, behavioral data), which is conducive to creating more advanced input features for models.
More relevant marketing and UX campaigns
With a common identifier, marketers can run consistent cross-device campaigns – e.g., limit the number of ad impressions per actual user (frequency capping) regardless of device, or continue the marketing message started on a computer also on a smartphone. Customer segmentation becomes more precise – you can create groups of users based on full activity (e.g. people viewing a given product first on their phone, and then buying on their desktop). For the user himself, this results in better content matching (personalization) and less irritation with repetitive messages. The user experience also improves – e.g. by knowing the crossuid, the website can recognize a returning customer and ensure session continuity (maintaining the shopping cart between devices, etc.).
Reduce erroneous data and detect bots
Implementing an identity graph enforces a rigorous approach to data quality. Bot filtering mechanisms remove spam and artificial traffic from traffic before it reaches analyses or models. This translates into clearer reports and resistance to abuse (e.g. manipulation of page view counters by scripts). In addition, the graph itself can be used to detect suspicious patterns – e.g. an IP node suddenly connected to hundreds of unique cookies (bot signal) or a fingerprint appearing on dozens of accounts (fraud signal) can automatically raise the alarm. Identifying inauthentic users in real time allows you to react quickly (block, change strategy) before they affect business metrics.
No more distributed identity – consistent customer data
The solution developed by Algolytics shows that graph user identification combined with an efficient event processing engine can effectively solve the problems of distributed identity in web analytics. From a business point of view, this translates into more reliable customer data, the ability to conduct advanced behavior analysis, and optimization of marketing activities for real people, not browsers. Technically, the use of the Scoring.One platform guarantees scalability – the system works in real time even for high traffic volumes – and flexibility in adjusting rules.




