
















Nowoczesne silniki scoringowe oparte na uczeniu maszynowym korzystają z coraz bardziej złożonych przepływów danych: transformacji cech, modeli predykcyjnych, reguł biznesowych oraz zapytań do baz danych - wszystko to współdziała w ramach jednego scenariusza.
Gdy coś pójdzie nie tak, znalezienie dokładnego miejsca awarii potrafi zająć godziny, a nawet całe dni.
Aby temu zaradzić, wprowadziliśmy Debugger - nowy moduł w Scoring.One, zaprojektowany po to, by radykalnie uprościć debugowanie pipeline’ów ML, zwiększyć interpretowalność modeli oraz zapewnić pełną przejrzystość na każdym etapie wykonywania scenariusza scoringowego.
To najbardziej istotne usprawnienie, jakie wprowadziliśmy w Scoring.One w obszarze obserwowalności, śledzenia wykonania i efektywnego debugowania.
Dlaczego debugowanie scenariuszy ML w Scoring.One potrzebowało lepszego rozwiązania
Data Scientistom i Inżynierom Machine Learning pracującym w Scoring.One często przychodzi budować scenariusze, które łączą w sobie:
- modele predykcyjne,
- węzły transformacyjne i feature engineering,
- logikę decyzyjną i ewaluację reguł,
- wewnętrzne i zewnętrzne zapytania do baz danych,
- zagnieżdżone pod‑scenariusze i złożone rozgałęzienia.
W tak złożonym środowisku tradycyjna walidacja to za mało. Zespoły potrzebują możliwości:
- analizowania przepływu danych pomiędzy węzłami,
- śledzenia zmian wartości krok po kroku,
- diagnozowania błędów logicznych w czasie rzeczywistym,
- zrozumienia, dlaczego model wygenerował konkretny wynik,
- testowania scenariuszy na własnych zestawach danych wejściowych i przypadkach brzegowych.
Do tej pory taki poziom wglądu nie był dostępny bezpośrednio w Scoring.One.
Debugger całkowicie to zmienia, wprowadzając przejrzysty i interaktywny mechanizm śledzenia wykonania scenariusza.
Jak Debugger zapewnia pełną transparentność wykonania scenariusza
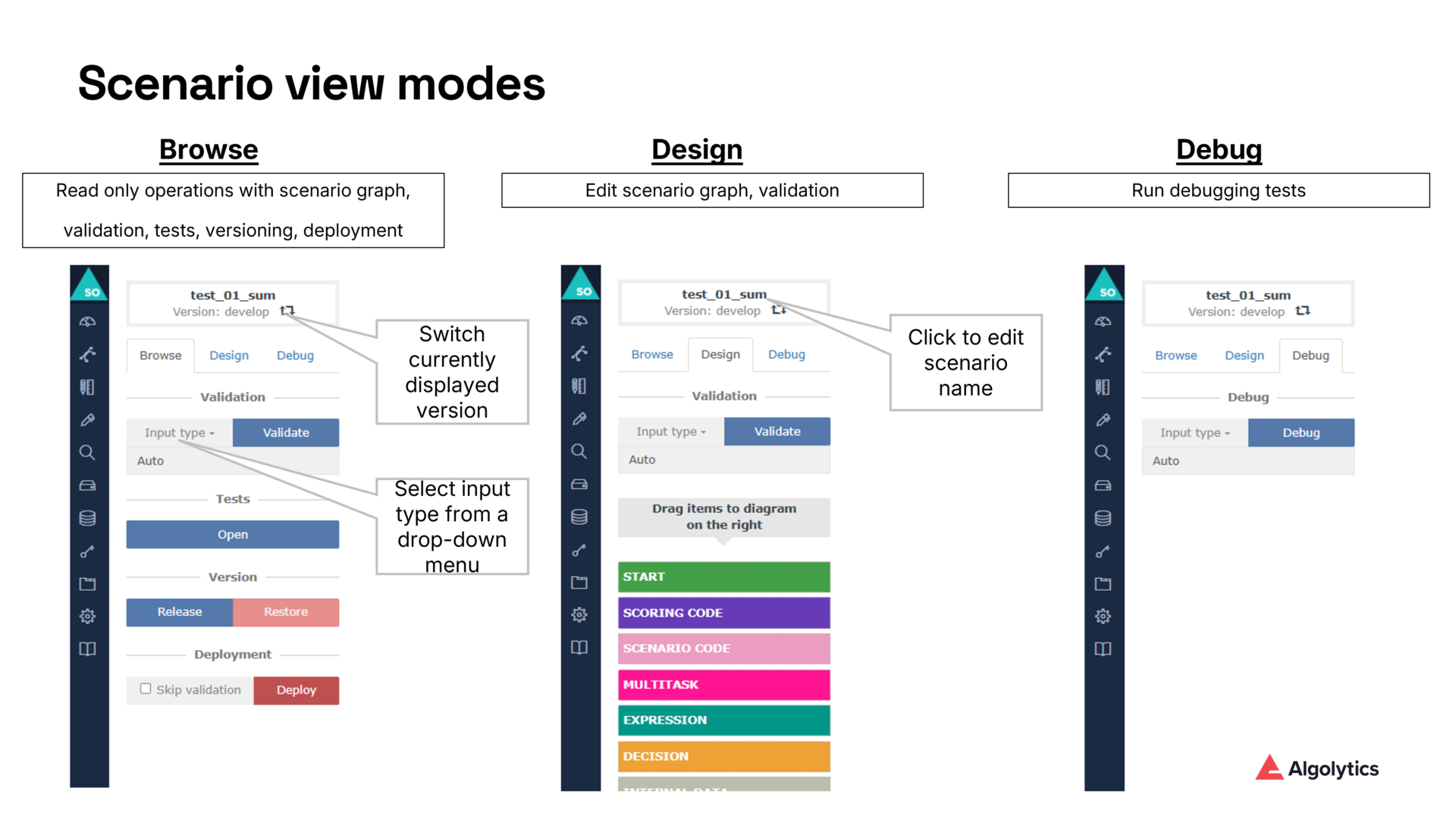
Debugger pojawia się w edytorze scenariusza jako nowy tryb - obok Browse i Design.
Po jego aktywowaniu użytkownik zyskuje możliwość:
- uruchamiania scenariuszy z w pełni kontrolowanymi danymi wejściowymi,
- wizualizacji ścieżek wykonania bezpośrednio na grafie scenariusza,
- podglądu wartości zmiennych po przejściu przez każdy węzeł,
- monitorowania znaczników czasu oraz szczegółowych metadanych wykonania,
- filtrowania dużych zbiorów danych za pomocą wbudowanych narzędzi.
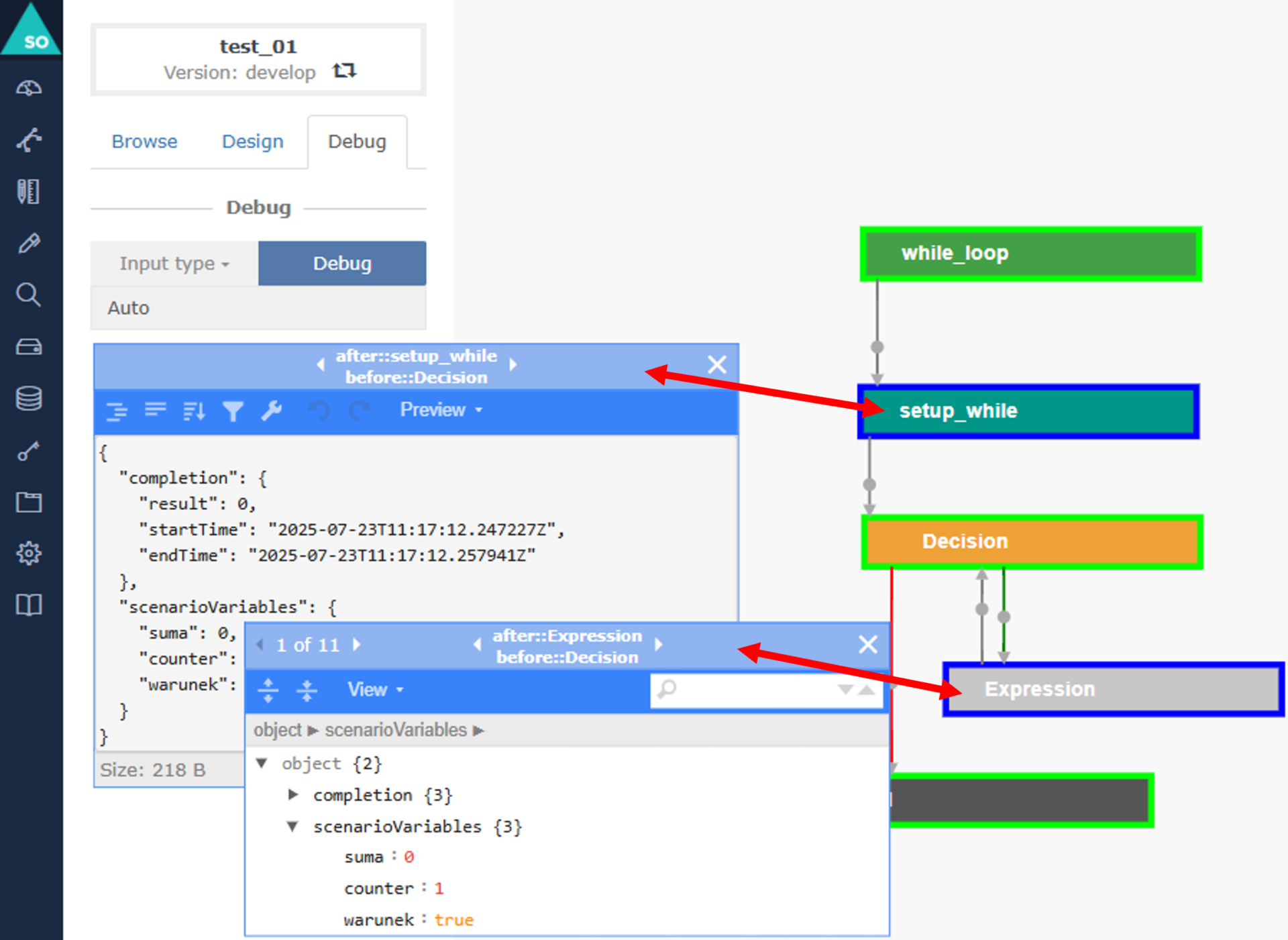
Zgodnie z dokumentacją, każdy wykonany węzeł zostaje oznaczony jasnozieloną krawędzią, co natychmiast pokazuje przebytą ścieżkę logiczną scenariusza.
Auto – domyślne wartości generowane automatycznie przez system,
Form – wartości wprowadzane ręcznie,
Inline – dane wejściowe w formacie JSON, przeznaczone do zaawansowanego testowania.
Dzięki temu debugowanie staje się łatwo dostępne zarówno dla analityków, jak i zespołów technicznych.
Inspekcja zmiennych na poziomie węzłów dla lepszej interpretowalności modeli
Kluczową możliwością Debuggera jest podgląd wszystkich wartości zmiennych po zakończeniu wykonania każdego węzła.
Po kliknięciu w węzeł użytkownik otrzymuje dostęp do dedykowanego, pływającego okna, które zawiera:
- czas rozpoczęcia i zakończenia wykonania,
- zmienne wyjściowe wygenerowane przez dany węzeł,
- predykcje modelu oraz przekształcone wartości cech,
- opcje formatowania i narzędzia filtrowania, przydatne zwłaszcza przy dużych wynikach.
Taka inspekcja na poziomie węzłów znacząco poprawia:
- interpretowalność modeli ML,
- kontrolę jakości feature engineeringu,
- diagnozowanie nieoczekiwanych wyników modelu,
- zrozumienie logiki rozgałęzień i podejmowanych decyzji.
Debugger wnosi do debugowania scenariuszy to, czym IDE są dla debugowania kodu - ale stworzone specjalnie z myślą o pipeline’ach scoringowych ML.
Wykorzystanie danych JSON do precyzyjnej reprodukcji przypadków brzegowych
Aby umożliwić rygorystyczne testowanie, Debugger akceptuje dane wejściowe w formacie JSON, co pozwala Data Scientistom odtwarzać:
- wartości brzegowe,
- braki danych lub nietypowe wzorce,
- scenariusze odstające (outliers),
- rzadkie warunki biznesowe,
- specyficzne profile klientów.
Przykładowy input JSON dla trybu Inline:
JSON
{
"age": 46,
"income": 12700,
"credit_history_length": 8,
"active_loans": 2
}Dzięki temu zespoły mogą precyzyjnie odtworzyć problematyczne lub nietypowe przypadki i przeanalizować, jak zachowuje się każdy element pipeline’u scoringowego.
Jak Debugger przyspiesza diagnostykę modeli ML i testowanie scenariuszy
Debugger zapewnia szereg korzyści o dużym wpływie na pracę zespołów Data Science:
✔ Szybsze debugowanie logiki scoringowej ML
Błędy można zidentyfikować, śledząc wizualnie wykonane węzły oraz przeglądając wartości zmiennych na każdym etapie.
✔ Lepsza interpretowalność i transparentność modeli
Zespoły mogą dokładnie sprawdzić, jak powstają predykcje i w jaki sposób przechodzą przez reguły biznesowe i transformacje.
✔ Większa pewność jakości scenariuszy gotowych do wdrożenia
Testowanie różnych typów danych wejściowych gwarantuje odporność scenariusza na rzeczywiste warunki.
✔ Mniej „ping‑pongu” między Data Science a zespołami inżynieryjnymi
Debugger działa jako wspólne źródło prawdy o zachowaniu scenariusza, eliminując nieporozumienia.
✔ Krótszy czas wdrażania modeli ML
Mniej czasu spędzonego na diagnozie błędów oznacza szybsze cykle wdrożeniowe oraz efektywniejsze iteracje.
Dlaczego Debugger podnosi wartość Scoring.One jako silnika scoringowego dla organizacji opartych na ML
Wprowadzenie Debuggera zmienia Scoring.One w platformę stawiającą na pełną obserwowalność pipeline’ów ML.
Dzięki całkowitej przejrzystości na poziomie każdego węzła, zmiennej i decyzji:
- rozwój scenariuszy staje się bardziej przewidywalny,
- debugowanie modeli przebiega znacznie szybciej,
- problemy z jakością danych są łatwiejsze do wykrycia,
- błędy integracyjne można zidentyfikować na wczesnym etapie,
- logika scenariusza staje się łatwiejsza do komunikowania i dokumentowania.
To prawdziwy game‑changer dla organizacji korzystających ze Scoring.One jako centralnego silnika scoringowego w obszarach takich jak: ocena ryzyka, wykrywanie nadużyć, scoring kredytowy i inne procesy oparte na ML.
Debugger: przejrzyste, wyjaśnialne i niezawodne pipeline’y scoringowe ML
Debugger całkowicie zmienia sposób tworzenia i monitorowania scenariuszy, umożliwiając:
- śledzenie wykonania krok po kroku,
- dogłębną inspekcję zmiennych,
- interaktywny, wizualny debugging,
- elastyczne testowanie danych wejściowych,
- szybsze procesy QA i wdrożeniowe.
Zapewniając Data Scientistom pełną widoczność logiki scenariusza i zachowania modeli, Debugger ustanawia nowy standard przejrzystości i niezawodności w budowaniu pipeline’ów scoringowych.



