
















Location Intelligence w marketingu (wysyłka materiałów)
Jednym z zastosowań Location Intelligence jest optymalizacja działań marketingowych. W tym case study na tapetę bierzemy firmę e-commerce, która prowadzi wysyłkę drukowanych materiałów marketingowych, takich jak gazetki produktowe. Pokażemy, że z wykorzystaniem modelowania predykcyjnego oraz danych adresowych i ich szczegółowej charakterystyki można znacząco podnieść skuteczność dystrybucji gazetek względem losowego doboru punktów doręczeń.
Zadanie potraktowano jako problem look-alike / propensity: na podstawie adresów obecnych klientów firmy z branży e-commerce wyznaczane jest prawdopodobieństwo z jakim inne lokalizacje w Polsce posiadają bliźniacze cechy. Dzięki temu można wskazać miejsca zamieszkania osób, które z dużym prawdopodobieństwem mogą stać się nowymi klientami - np. po skierowaniu do nich działań marketingowych. W praktyce wynik modelowania może posłużyć do wyboru top-K punktów doręczeń gazetek produktowych zamiast doboru losowego.
Cel i założenia case study
Celem case study jest empiryczne wykazanie, że bogaty opis przestrzenny znacząco poprawia selekcję adresów do wysyłki – mierzoną m.in. przez precision/recall, PR-AUC oraz lift@K w porównaniu z selekcją losową. Model operuje na zagregowanych cechach lokalizacyjnych i nie wykorzystuje informacji pozwalających na identyfikację konkretnych osób. Analiza ma charakter adresopunktowy (lokalizacja jako jednostka prognozy), co odpowiada operacyjnemu sposobowi planowania dystrybucji drukowanych materiałów marketingowych.
Źródła danych i charakterystyka zbiorów
Dane do budowy modelu pochodzą z okresu 26.07–25.08.2025 i obejmują dwa zbiory:
- Target = 1: 128 535 adresów zamieszkania klientów sklepu (które zostały zgeokodowane na potrzebę budowy modelu)
- Target = 0: 200 000 adresów dolosowanych z pełnej bazy adresowej Polski, z których usunięto adresy obecnych klientów firmy e-commerce.
Dla każdego adresu zbudowano wektor ok. 750 cech opisujących lokalizację i jej otoczenie. Zmienne obejmują m.in.: charakterystykę budynków, profil mieszkańców i strukturę zasobów mieszkaniowych, dostępność i gęstość punktów POI, dostęp do usług różnych rodzajów, ekspozycję na zagrożenia naturalne, wskaźniki ryzyka finansowego, dostęp do Internetu i technologii transmisyjnych, miary jakości życia (oświata, zieleń, infrastruktura). Taki przekrojowy opis przestrzeni pozwala ująć czynniki popytowe i podażowe, które mogą determinować skłonność do zakupu po ekspozycji na materiał reklamowy.
Budowa modelu predykcyjnego
Do budowy modelu wykorzystano Automatic Business Modeler (AutoML) od Algolytics oraz algorytm XGBoost (Extreme Gradient Boosting), który stanowi uogólnioną metodę uczenia zespołu drzew decyzyjnych. W praktyce polega to na sekwencyjnym konstruowaniu wielu płytkich drzew. Dzięki temu model potrafi uchwycić nieliniowe zależności i interakcje między zmiennymi, co jest szczególnie istotne w danych przestrzennych, gdzie efekty są często warunkowe (np. znaczenie gęstości określonego typu punktów POI zależy od typu zabudowy czy struktury demograficznej w sąsiedztwie).
Mechanizm klasyfikacji adresów
Model zwraca prawdopodobieństwo, że pod danym adresem mieszka nowy klient firmy. Domyślnie w problemach klasyfikacyjnych za próg decyzyjny przyjmuje się wartość 0,5. W tym przykładzie oznacza to, że każdy adres z prawdopodobieństwem modelowym wynoszącym co najmniej 50% zostanie zakwalifikowany do wysyłki gazetki produktowej (klasa 1), a poniżej 50% zostanie odrzucony (klasa 0). W takim ustawieniu model działa w sposób zrównoważony - dobrze ogranicza niepotrzebne wysyłki (niewiele adresów nie klienckich przechodzi do kampanii), a jednocześnie wyłapuje znaczącą część adresów podobnych do adresów obecnych klientów. Akceptuje przy tym, że część wartościowych adresów może zostać pominięta.
Ocena skuteczności modelu
Macierz pomyłek przy progu 0,5 na zbiorze testowym (liczność 65707 obserwacji)
| Klasa rzeczywista | |||
| 1 | 0 | ||
| Klasa prognozowana | 1 | 68,6% | 31,4% |
| 0 | 20,3% | 79,7% | |
Wyniki macierzy pomyłek potwierdzają, że przy progu 0,5 model pracuje w sposób operacyjnie użyteczny. Niemal 70% zakwalifikowanych adresów to rzeczywiste trafienia (true positive) – miejsca, do których wysyłka gazetki ma wysokie szanse przełożyć się na zamówienie. Około 30% rekordów to błędy typu false positive, co w praktyce oznacza poniesienie kosztu dystrybucji bez oczekiwanego zwrotu. Z drugiej strony macierz ujawnia również około 20% pominięć (false negative) – wartościowe adresy, które nie weszły na listę przy bieżącym progu – jest tu pole do optymalizacji poprzez dostrojenie progu decyzyjnego. Prawie 80% adresów ze zbioru testowego zostało uznanych przez model za adresy odrzucone (true negative), co potwierdza że model skutecznie odsiewa adresy z niskim potencjałem, ograniczając tym samym wielkośćskalę i koszt wysyłki.
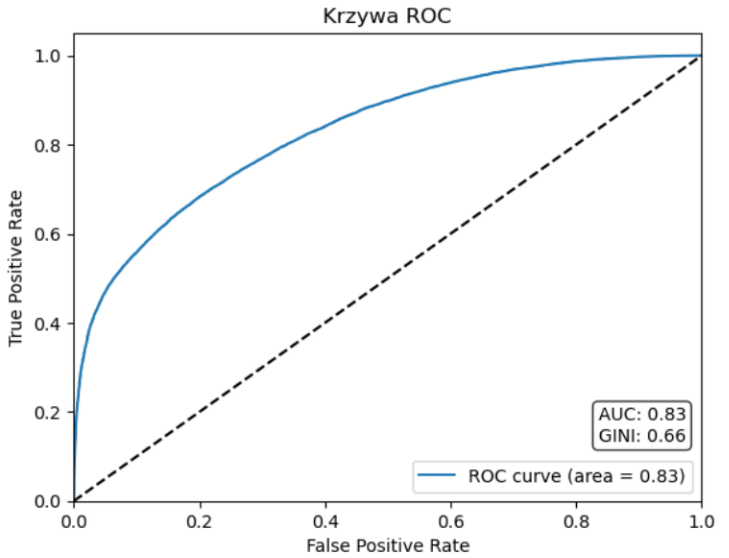
Rys. 1 Krzywa ROC modelu typującego adresy do kampanii marketingowej
Krzywa ROC oraz wskaźniki AUC i Gini opisują zdolność modelu do porządkowania adresów od najbardziej do najmniej perspektywicznych, niezależnie od konkretnego progu. Wartość AUC = 0,83 oznacza, że model potrafi znacząco podnosić odsetek trafień przy niskim poziomie błędów false positive. Jednocześnie GINI = 0,66 wskazuje na silną separację między rozkładami prawdopodobieństw dla adresów klienckich i nieklienckich, co przekłada się na (dosyć) wysoką zdolność modelu do ich rozróżniania. W praktyce uzyskany wynik należy uznać za wysoki - zwłaszcza, że model opiera się wyłącznie na opisie przestrzennym adresu. Przekłada się to na realną możliwość koncentracji budżetu tam, gdzie spodziewany zwrot z wysyłki jest największy.
Analiza cech wpływających na predykcję
Jedną z korzyści tak zbudowanego modelu jest możliwość niezwykle dokładnego opisu lokalizacji, w których mieszkają dotychczasowi klienci firmy. Można to zrobić poprzez analizę zmiennych, które w największym stopniu wpływają na predykcję. W modelu który stworzyliśmy są to:
- Liczba mieszkań w budynku
- Liczba kobiet zameldowanych w budynku
- Liczba działalności gospodarczych i firm zarejestrowanych w budynku
- Kubatura budynku
- Liczba mieszkańców i osób zameldowanych
- Liczba kobiet w wieku 40-50 lat oraz powyżej 65 roku życia
Do oceny wpływu zmiennych na predykcję wykorzystaliśmy miarę SHAP (SHapley Additive exPlanations), która rozkłada prognozę modelu na wkłady poszczególnych zmiennych. SHAP value to lokalny wkład danej cechy do wyniku dla pojedynczego rekordu względem punktu odniesienia. Znak mówi o kierunku wpływu: wartości dodatnie podnoszą wynik , a wartości ujemne – obniżają go. W przypadku modelu binarnego oznacza to odpowiednio wzrost lub spadek prawdopodobieństwa przypisania rekordu do klasy pozytywnej (np. klasy 1). Wartość pokazuje siłę wpływu.
Na wykresie zależności (SHAP dependence) oś X to wartość cechy w danych, a oś Y to jej SHAP value. Chmura punktów pokazuje, jak zmienia się wpływ cechy w całej populacji.; Ttrend (np. rosnący) ujawnia kierunek oddziaływania, nasycenie – progi i efekty malejących przyrostów, a rozrzut pionowy – interakcje z innymi cechami (ta sama wartość cechy może mieć różny wpływ w różnych kontekstach). Poniżej przedstawiamy wykres dla najważniejszej zmiennej w modelu, czyli liczby mieszkań w budynku.
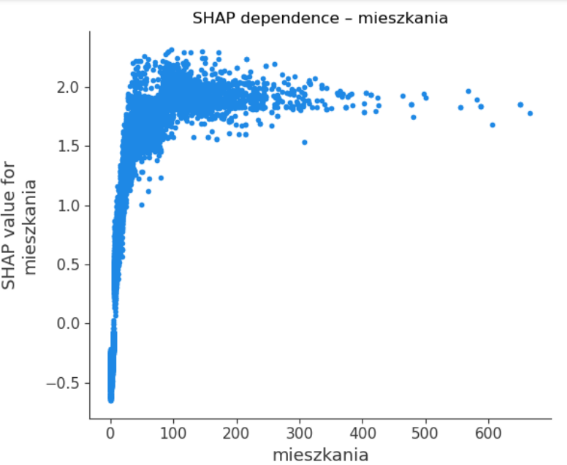
Zależność jest jednoznacznie dodatnia. Przy bardzo małej liczbie lokali wpływ na wynik bywa neutralny lub ujemny, natomiast już od kilkunastu–kilkudziesięciu mieszkań wkład gwałtownie rośnie i utrzymuje się na wysokim poziomie. Wynika z tego, że typowy klient firmy mieszka w budynku wielorodzinnym, posiadającym co najmniej kilkanaście mieszkań.
Podobną analizę przeprowadziliśmy dla kolejnych szczególnie istotnych cech. Wynika z niej, że typowi klienci firmy mieszkają w budynkach, w których zameldowanych jest dużo kobiet, w szczególności w wieku 40-50 lat, co prawdopodobnie jest wynikiem oferty sklepu – w głównej mierze jest to odzież damska. Często są to budynki o dużej kubaturze, w których zarejestrowane są działalności gospodarcze i firmy, co wskazuje na adresy posiadające np. lokale usługowe na parterze budynku.
Tak utworzony profil perspektywicznych adresów pozwala na filtrowanie pełnej bazy adresowej budynków i zrealizowanie targetowanej masowej wysyłki marketingowej. Może to przynieść oczekiwane efekty, jeśli pojedynczy koszt jest niski (np. ulotki). Jeśli natomiast mamy do czynienia z wyższymi kosztami dystrybucji, jakimi charakteryzują się np. gazetki produktowe, lepszym rozwiązaniem jest selekcja adresów. Do tego celu z powodzeniem można wykorzystać model machine learning analogiczny do tego, który stworzyliśmy na potrzeby tego case study.
Dwa tryby pracy: sterowanie progiem lub ustalenie stałej liczby top-K
Model taki pozwala na selekcję i skierowanie materiałów marketingowych do adresów o najwyższym prawdopodobieństwie odpowiedzi, uzyskując wyższą skuteczność przy tym samym budżecie, albo porównywalny efekt przy mniejszej skali operacji. W praktyce dostępne są dwa tryby pracy.
- Po pierwsze, sterowanie progiem: obniżenie progu zwiększa zasięg (więcej true positive, ale także więcej false positive), co ma sens przy tańszej dystrybucji lub priorytecie maksymalnego dotarcia. Z drugiej strony podniesienie progu daje „czystszą” listę adresów (mniej błędów false positive), kosztem mniejszego pokrycia adresów perspektywicznych (więcej false negative).
- Po drugie, ranking top-K: zamiast ustalać próg, wybiera się stałą liczbę najlepszych adresów wynikającą z budżetu (np. dostępnej liczby ulotek i mocy doręczeniowej). Taki tryb jest zwykle najbardziej intuicyjny dla planowania operacji i pozwala raportować lift@K – ile razy gęstszy w „trafienia” jest wybrany segment niż losowy.
Nasz model przy progu 0,5 zapewnia rozsądny kompromis między „czystością” listy a pokryciem adresów wartościowych, co już teraz przekłada się na realne oszczędności i wyższy zwrot w porównaniu przypadkową selekcją adresów do wysyłki. Natomiast jeżeli celem kampanii jest maksymalizacja efektu (np. nowa kolekcja, krótki horyzont), warto obniżyć próg lub zwiększyć top-K, aby odzyskać część utraconych okazji. Jeżeli priorytetem jest minimalizacja kosztu jednostkowego, należy podnieść próg i utrzymać wąską, wysoko precyzyjną listę.
Selekcja adresów metodą top-K i ocena skuteczności segmentu
W praktyce planowania wysyłek najbardziej naturalnym trybem pracy z modelem jest selekcja top-K. Każdy adres otrzymuje w wyniku modelowania score równy przewidywanemu prawdopodobieństwu bycia „klienckim”. Adresy są sortowane malejąco po tym wyniku, a następnie wybierana jest stała liczba najlepszych rekordów – dokładnie tyle, na ile pozwala budżet i logistyka (np. 5%, 10% lub 20% puli).
Skuteczność tak wybranego segmentu ocenia się m.in. przez:
- precision@k - jaki odsetek wytypowanych adresów to faktyczne trafienia,
- recall@k - jaki odsetek wszystkich trafień z całej próby mieści się w top-K,
- base rate - udział trafień w całej populacji,
- lift@k - ile razy segment top-K jest gęstszy w trafienia niż wybór losowy tej samej wielkości
W naszym case study na danych walidacyjnych base rate wynosi ok. 39,1%, co oznacza, że losowe wskazanie 10% adresów dawałoby średnio ~39% trafień. Jednak stworzony przez nas model znacząco poprawia ten wynik:
- Dla top 5% (5% adresów z najwyższym scorem) uzyskano precision ≈ 97,9%, recall ≈ 12,5% i lift ≈ 2,50 – bardzo „czysty” segment, w którym niemal każdy doręczony egzemplarz trafia pod właściwy adres, przy ograniczonym wolumenie.
- Dla top 10% precyzja wynosi ~95,5%, recall ~24,4%, a lift ~2,44 – podwajamy zasięg niemal podwajając skalę trafień przy niewielkim spadku trafności.
- Przy top 20% otrzymujemy precision ≈ 87,3%, recall ≈ 44,6% i lift ≈ 2,23: wolumen rośnie czterokrotnie względem 5%, a liczba trafień ok. 3,6-krotnie, nadal ponad dwukrotnie lepiej niż losowo.
Widoczny jest efekt malejących korzyści – im głębiej schodzimy w ranking, tym „czystość” segmentu stopniowo spada – jednak nawet przy 20% przewaga nad losowaniem pozostaje wyraźna.
Z punktu widzenia decyzji operacyjnych wybór K należy powiązać z jednostkowym kosztem doręczenia i oczekiwaną marżą. Przy wysokim koszcie (np. gazetki premium) warto celować w 5–10% – precyzja bliska 96–98% zwykle łatwo przekracza próg opłacalności definiowany relacją koszt / marża. Gdy celem jest maksymalizacja zasięgu lub budowa bazy, można zwiększać K, świadomie akceptując niższy precision w zamian za wyraźnie wyższy recall.
Symulacja zwrotu z kampanii marketingowej
Zasymulujmy jaki byłby zwrot z kampanii marketingowej przeprowadzonej z wykorzystaniem modelu. W tym celu przyjmujemy następujące założenia:
- koszt jednostkowy wysyłki gazetki: c = 5 PLN/szt.
- średnia marża kontrybucyjna z pojedynczego zamówienia: m = 10 PLN
- selekcja adresów metodą top-K (K = 5%, 10% i 20% puli), z wykorzystaniem wcześniej przedstawionych wyników modelu
Przy powyższych założeniach dla zbioru testowego liczącego 65 707 adresów otrzymujemy następujące wyniki:
| K | Precyzja | Liczba oczekiwanych zamówień | Koszt wysyłki | Marża | Zysk | ROI | Średni koszt pozyskania klienta |
| 5% | 97,9% | 3208 | 16430 zł | 32080 zł | 15650 zł | 95% | 5,12 zł |
| 10% | 95,5% | 6286 | 32855 zł | 62860 zł | 30005zł | 91% | 5,23 zł |
| 20% | 87,3% | 11485 | 65710 zł | 114850 zł | 49140zł | 75% | 5,72 zł |
Opłacalność wysyłki można ująć prostą regułą progu rentowności: segment jest na plusie wtedy, gdy jego precision (udział trafień wśród wytypowanych adresów) przekracza stosunek kosztu jednostkowego do marży jednostkowej. Innymi słowy, warunek rentowności ma postać precision > koszt/marża. Dla przykładu, przy koszcie doręczenia 5 PLN i marży 10 PLN próg wynosi 0,50. Wszystkie analizowane segmenty top-K (precyzja 0,87 -0,98) znajdują się wyraźnie powyżej tej granicy, co przekłada się na wysoką rentowność kampanii.
Analiza wrażliwości potwierdza stabilność tego wniosku. Nawet gdy koszt wzrośnie do 7 PLN (próg opłacalności 0,70), segmenty top 5–20% pozostają rentowne, ponieważ ich precyzja nie spada poniżej 0,874. Z kolei spadek kosztu do 3 PLN przy marży 8 PLN dodatkowo poprawia wynik finansowy – dla top 10% oznacza to wzrost ROI rzędu ~160%. W praktyce dobór skali wysyłki powinien więc odnosić się do relacji koszt/marża oraz obserwowanej precyzji w wybranym segmencie rankingu.
Podsumowanie: stworzony model look-alike pozwala skutecznie zidentyfikować adresy z wysokim potencjałem zakupowym
Przedstawiony model typu look-alike pozwala w praktyczny sposób uporządkować wszystkie adresy w Polsce pod kątem potencjału odpowiedzi na wysyłkę materiałów drukowanych i zastąpić dobór losowy selekcją opartą na danych. Weryfikacja na zbiorze testowym potwierdziła wysoką jakość predykcji (AUC = 0,83; Gini = 0,66), co bezpośrednio przekłada się na korzyści operacyjne:
- mniejszą liczbę niepotrzebnych wysyłek,
- większą koncentrację budżetu na adresach perspektywicznych,
- wyższy zwrot z kampanii przy tej samej skali lub porównywalny efekt przy mniejszych nakładach.
Dwa tryby działania - sterowanie progiem oraz ranking top-K - umożliwiają dopasowanie strategii do ograniczeń budżetowych: od scenariuszy „zasięgowych” po scenariusze „rentownościowe”. Dodatkowo analizy SHAP dają czytelny, biznesowy opis cech lokalizacji sprzyjających konwersji, co ułatwia planowanie dystrybucji.
Istotne jest, że cały wynik osiągnięto wyłącznie na bazie cech przestrzennych adresu, bez jakichkolwiek danych osobowych czy transakcyjnych. Otwiera to drogę do dalszej poprawy skuteczności: włączenie danych behawioralnych (aktywność www), historycznych reakcji na kampanie, sezonowości, a także danych asortymentowych czy cenowych powinno dodatkowo podnieść precyzję i stabilność prognoz. W efekcie model może stać się centralnym komponentem procesu planowania wysyłek - od profilowania obszarów, przez symulację ROI, po taktyczne sterowanie skalą i częstotliwością kampanii.
Technologiczne fundamenty rozwiązania
Całość rozwiązania opisanego w tym case study została zbudowana z wykorzystaniem modułu Location Intelligence od Algolytics, który integruje kilka kluczowych komponentów:
- Moduł standaryzacji i geokodowania adresów, który przypisuje współrzędne geograficzne do danych adresowych, umożliwiając ich dalszą analizę przestrzenną.
- Bogata baza danych przestrzennych – zawierająca setki cech lokalizacyjnych na poziomie pojedynczych budynków, takich jak struktura demograficzna, dostępność usług, infrastruktura, ryzyka środowiskowe czy jakość życia.
- AutoML: Automatic Business Modeler – narzędzie do automatycznego tworzenia modeli predykcyjnych, które pozwala szybko testować różne algorytmy i konfiguracje.
Stworzone modele mogą zostać zaimplementowane w procesach biznesowych w oparciu o:
- MLOps: Scoring.one – platforma do wdrażania modeli i udostępniania ich wyników w środowisku produkcyjnym, umożliwiająca integrację z systemami klienta i bieżące monitorowanie skuteczności.
Dzięki tej architekturze możliwe jest płynne przejście od surowych danych adresowych, przez ich wzbogacenie o kontekst lokalizacyjny, aż po wdrożenie modeli predykcyjnych wspierających decyzje operacyjne i marketingowe. To właśnie ta infrastruktura pozwala firmom osiągać wysoką precyzję kampanii bez wykorzystywania danych osobowych.



