
















W kampaniach w Meta i Google lokalizacja jest jednym z najprostszych suwaków do przesunięcia… i jednym z najczęściej marnowanych. Z jednej strony platformy pozwalają wskazać obszar emisji reklam (miasto, region, kod pocztowy, pinezka z promieniem), z drugiej — w praktyce geotargetowanie bywa ustawiane „na oko”: bo tu mamy sklep, bo tu „na pewno” jest nasza grupa, bo tu kiedyś działało. Efekt? Budżet rozlewa się po obszarach, które generują zasięg, ale niekoniecznie sprzedaż.
Scoring lokalizacji na danych 1st‑party: alternatywa dla Lookalike Audience
W tym poradniku pokażemy, jak podejść do lokalizacji bardziej analitycznie: zbudować własny model podobieństwa/propensity na danych 1st-party (adresach zamówień), a potem zastosować go na całej Polsce, aby uzyskać scoring potencjału — czyli ranking miejsc, które najbardziej przypominają lokalizacje historycznych klientów. Warto doprecyzować, że to nie jest „Lookalike Audience” w rozumieniu gotowej funkcji Meta, tylko niezależny model oparty o dane klienta, który ma jeden cel: podpowiedzieć, gdzie warto testować budżet, zanim zaczniemy go optymalizować wyłącznie na sygnałach platformy.
Ponieważ platformy reklamowe nie targetują „adresów” jako takich, tylko obszary, przełożymy scoring na dwa formaty, które da się realnie wdrożyć w kampanii:
- agregację do kodów pocztowych,
- punkty (pinezki) z promieniem — dla precyzyjnych działań lokalnych, z uwzględnieniem minimalnych wielkości audytorium i praktycznych ograniczeń delivery.
Całość oprzemy o powtarzalny w innych zastosowaniach proces: od standaryzacji i geokodowania adresów zamówień (Data Quality), przez wzbogacenie lokalizacji danymi przestrzennymi, po budowę segmentów geo zgodnych z politykami platform reklamowych (szczególnie istotne w kategoriach wrażliwych, gdzie targetowanie lokalizacją bywa dodatkowo ograniczane). Na koniec zrobimy to, co w marketingu rozstrzyga dyskusję: symulację zwrotu z kampanii — porównując scenariusz „bez geo-danych” do scenariusza z segmentacją opartą o scoring Algolytics, żeby pokazać, gdzie i dlaczego pojawia się realny lift w wynikach.
Dlaczego precyzyjne geotargetowanie w Meta i Google zwiększa skuteczność kampanii performance
W wielu organizacjach lokalizacja w kampaniach Meta i Google jest traktowana jak ustawienie techniczne: wybieramy całą Polskę, ewentualnie kilka województw albo promień wokół sklepów. Często wynika to z tego, że geotargetowanie jest łatwe do kliknięcia, ale trudniejsze do zrobienia dobrze. Problem w tym, że „łatwe geo” zwykle nie odpowiada na najważniejsze pytanie: gdzie budżet na kampanię ma największą szansę przełożyć się na sprzedaż, a gdzie będzie tylko finansował zasięg?
Najczęstsze błędy w geotargetowaniu i ich wpływ na wyniki kampanii digital
Z perspektywy digital marketingu „przepalanie” budżetu na poziomie lokalizacji bierze się zwykle z trzech schematów:
- Zbyt szeroki obszar („cała Polska” albo „top miasta”), bo „algorytm i tak zoptymalizuje”. Optymalizuje — ale często wewnątrz zbyt dużego obszaru, w którym mieszają się segmenty o skrajnie różnym potencjale.
- Geo-targetowanie oparte o intuicję (istniejące sklepy stacjonarne, przyzwyczajenia zespołu), bez aktualizacji pod realne zachowania klientów — szczególnie gdy sprzedaż online rośnie i geografia popytu przestaje pokrywać się z mapą sklepów.
- Brak kontroli nad granularnością: zbyt małe obszary mogą nie „dowieźć” emisji (brak stabilności delivery), a zbyt duże rozmywają różnice w potencjale.
W efekcie geo-targetowanie bywa traktowane jak „ramka” na kampanię marketingową, zamiast jak narzędzie do decyzji budżetowej odpowiadające na pytania gdzie zwiększać presję?, gdzie testować?, a gdzie odpuszczać?
Jak Meta i Google definiują lokalizację i jakie ograniczenia wpływają na targetowanie
Targetowanie w platformach Meta i Google odbywa się po obszarach, a dopasowanie reklamy do użytkownika opiera się na sygnałach lokalizacyjnych (różnej jakości i różnej dostępności).
W praktyce oznacza to trzy konsekwencje:
- Wymagane jest pracowanie na jednostkach, które da się ustawić w kampanii: regiony/miasta, kody pocztowe, albo pinezki z promieniem. Nawet jeśli model liczysz na punktach adresowych, finalnie i tak potrzebujesz agregacji do formatu mediowego.
- Istnieją ograniczenia delivery i prywatności: zbyt drobne segmenty (mikro-geo) mogą być niestabilne, niedostępne lub słabo realizowane przez system aukcyjny (zwłaszcza przy małych budżetach).
- Compliance ma znaczenie: w kategoriach wrażliwych (np. kredyty, praca, mieszkalnictwo, zdrowie) targetowanie i personalizacja mogą mieć dodatkowe ograniczenia – w zależności od platformy. Dlatego w profesjonalnym podejściu geo segmentujemy obszary, a nie „ludzi”, i dbamy o bezpieczny poziom agregacji.
W dalszej części poradnika przełożymy scoring potencjału na dwa wdrożeniowe warianty geo-targetowania: kody pocztowe oraz punkty z promieniem.
Jak dane z zamówień online i CRM stają się paliwem dla geo‑scoringu i segmentacji lokalizacji
W przeprowadzonej analizie bazowaliśmy na realnym, bardzo częstym przypadku: klient ma sprzedaż hybrydową (sieć sklepów w całej Polsce + e-commerce), a dane uczące model pochodzą z zamówień internetowych. To świetny punkt startu, bo:
- zamówienia są „twardym” sygnałem konwersji,
- e-commerce daje dużą skalę,
- geografia popytu online często ujawnia obszary, których nie widać przez pryzmat lokalizacji sklepów.
W najprostszej wersji wystarczą:
- adresy dostaw / adresy zamówień (po stronie klienta),
- ich standaryzacja i geokodowanie,
- oraz rozsądne podejście do prywatności: wynik finalnie interpretujemy i wdrażamy na poziomie obszarów, nie jednostkowych punktów.
W realnych zastosowaniach warto jednak pójść krok dalej i wzmocnić sygnał biznesowy. Przykłady danych, które bardzo dobrze mogą zadziałać w takim modelu:
- wartość zamówienia (AOV) lub marża — żeby scoring mówił nie tylko „gdzie jest popyt”, ale „gdzie jest popyt wartościowy”,
- częstotliwość zakupów / CLV (jeśli mamy identyfikator klienta) — wtedy geo-segmenty wspierają strategię „pozyskujemy klientów, którzy zostają”,
- kategorie produktów (np. różne mapy potencjału dla asortymentu sezonowego),
- leady (formularze, telefony, czaty), szczególnie w branżach, gdzie sprzedaż kończy się offline,
- dane o wizytach / footfall (np. z aplikacji, danych analitycznych lub paneli — jeśli są dostępne),
- sygnały z CRM (kwalifikacja leadów, status sprzedaży),
- zwroty / reklamacje jako „negatywny” sygnał jakości sprzedaży w danym obszarze.
Model propensity look‑alike oparty o Location Intelligence - jak przewidywać potencjał zakupowy lokalizacji
Model który zbudowaliśmy jest oparty o realne konwersje – zamówienia online klientów sklepu. Jest to model typu look alike (nie mylić z funkcją Lookalike Audience dostępnej w Meta), który odpowiada na pytanie które lokalizacje w Polsce są najbardziej podobne do lokalizacji, w których historycznie pojawiały się zamówienia online.
W praktyce oznacza to, że:
- uczymy model na realnych konwersjach (zamówieniach online) klienta,
- wynik (scoring) jest niezależny od platformy reklamowej i może być użyty zarówno w Meta, jak i w Google,
- mamy kontrolę nad tym, co oznacza „dobry klient” (w realiach biznesowych można to rozszerzyć np. o wartość zamówienia, marżę czy CLV).
Score porządkuje lokalizacje wg przewidywanego podobieństwa do miejsc, w których historycznie wystąpiła konwersja (zamówienie online). To hipoteza o potencjale, którą potem weryfikujemy testem kampanijnym np. testem geo A/B.
Dane przestrzenne i cechy otoczenia użyte w modelu predykcyjnym geo‑scoringu
Przeprowadzona przez nas analiza dotyczyła klienta prowadzącego sprzedaż hybrydową (sieć sklepów + e-commerce), a nasze dane uczące pochodziły z zamówień internetowych. Każdy adres został opisany zestawem danych Location Intelligence Algolytics, który obecnie obejmuje ponad 850 zmiennych opisujących otoczenie lokalizacji. W praktyce są to m.in. cechy związane ze strukturą i intensywnością zabudowy, „masą” rynku (liczba ludności, ilość gospodarstw domowych, średnie dochody), bliskość generatorów ruchu (liczba i odległość do określonych typów POI), otoczenie i czynniki jakości życia (dostępność terenów zielonych, jakość powietrza, hałas) i wiele innych. Dzięki temu model nie „widzi” tylko lokalizacji (współrzędnych geograficznych) — widzi kontekst, który zwykle ma znaczenie w zachowaniach zakupowych.
Dlaczego odpowiednie tło (negatives) podnosi jakość geo‑scoringu i eliminuje bias miejski
Jednym z najważniejszych elementów tej analizy było zdefiniowanie, czym jest „rynek”, czyli tło, względem którego model uczy się odróżniać lokalizacje zamówień. Ponieważ mówimy o sprzedaży online (zasięg geograficzny obejmuje całą Polskę), jako tło/negatyw zastosowaliśmy losowe adresy z całej Polski, dla których w analizowanym okresie nie wystąpiło zamówienie (target=0). Dodatkowo, aby ograniczyć efekt premiowania lokalizacji z dużych miast, zastosowaliśmy stratyfikację tła po zmiennej dotyczącej liczby mieszkańców w promieniu 500 m od budynku. Bez dobrze dobranego tła model często korzysta z najłatwiejszej reguły – miasto > wieś. Stratyfikacja powoduje, że w danych uczących pojawia się więcej porównań typu miasto vs miasto oraz obszary o podobnym zagęszczeniu, co daje zwykle bardziej użyteczny ranking do realnych decyzji mediowych. Jeśli dostępne są dane o ekspozycji np. sesje na stronie, kliknięcia, leady bez zakupu, dostawy nieudane, itp. można z nich skorzystać jako „tła” dla modelu - „miejsca, w których klienci byli zainteresowani / byli w lejku, ale nie kupili”.
Wyniki modelu propensity: jakość przewidywań, AUC, PR‑AUC i co oznaczają dla kampanii
Finalny zbiór uczący do modelu zawierał ok. 575 tys. rekordów (połączenie obserwacji pozytywnych i tła). Wynikiem modelowania jest prawdopodobieństwo wystąpienia klasy pozytywnej, czyli swego rodzaju scoring, który wykorzystamy do rankingu lokalizacji. Model oceniliśmy na zbiorze testowym za pomocą metryk typowych dla modeli propensity. W tej analizie udało się osiągnąć wyniki na poziomie AUC (ROC) = 0,78 i PR-AUC = 0,80.
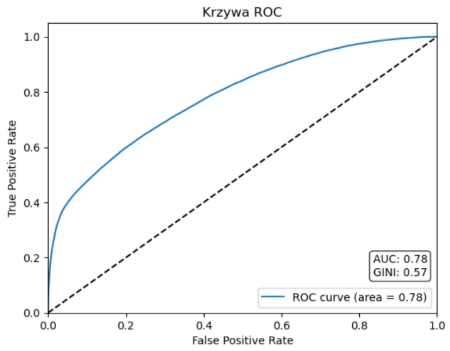
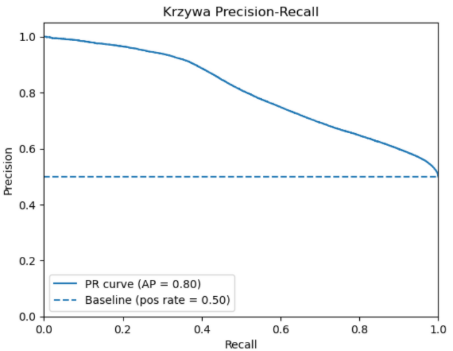
ROC-AUC (~0.78) mówi, że model istotnie lepiej niż losowy klasyfikator rozróżnia lokalizacje podobne do tych „zakupowych” od tła. Metryka PR-AUC (~0.80) jest bardzo użyteczna w marketingu, bo skupia się na tym, co zwykle interesuje kampanię: jaka jest jakość top-wyników (precyzja) przy różnych poziomach pokrycia (recall). Osiągnięty wynik oznacza, że model znacząco lepiej niż losowo układa lokalizacje w ranking: w górnej części listy znajduje się dużo większy odsetek lokalizacji podobnych do zakupowych, i ta przewaga utrzymuje się przy różnych progach odcięcia.
Powyższe metryki oceniają ogólną jakość modelu, ale w reklamie najważniejsze jest pytanie: czy top lokalizacje naprawdę są wyraźnie lepsze od średniej? Do tego świetnie nadaje się lift, wyniki dla top 5%, 10% i 20% lokalizacji przedstawiamy poniżej.
| Procent najlepszych lokalizacji | Positive rate | Lift |
| 5% | 0.9840 | 1.97x |
| 10% | 0.9667 | 1.93x |
| 20% | 0.9124 | 1.82x |
W tej analizie udało się osiągnąć wynik top 10% rate na poziomie 0.9667 oraz lift Top10 - 1.93x. Oznacza to, że w top 10% lokalizacji według scoringu udział pozytywów wynosi ~0.97, czyli niemal wszystkie wskazane lokalizacje należą do klasy „zakupowej” w ujęciu testowym. Z kolei lift 1.93× oznacza, że wybierając top 10% obszarów wg modelu, otrzymujemy prawie 2× większą koncentrację lokalizacji o profilu zakupowym niż w średniej próbie.
To jest dokładnie ten rodzaj wyniku, który da się przełożyć na plan mediowy: zamiast „siać reklamę szeroko”, możemy zbudować segmenty geo (kody pocztowe lub pinezki z promieniem) oparte o najwyższe decyle scoringu i spodziewać się wyższej efektywności budżetu – a następnie potwierdzić to w geo-teście A/B.
Jak agregować geo‑scoring do kodów pocztowych i pinezek z promieniem w kampaniach Meta/Google
Model zwraca scoring na poziomie pojedynczych adresów/punktów, ale Meta i Google nie targetują “adresów” – targetują obszary: m.in. kody pocztowe, miasta/regiony oraz pinezki z promieniem. Dlatego kolejny krok to przełożenie wyniku modelu na format, który da się realnie wgrać do kampanii i przetestować.
W tej analizie przygotowaliśmy dwa równoległe warianty wdrożeniowe:
- Wariant A: agregacja do kodów pocztowych - czytelne, łatwe do raportowania i skalowania,
- Wariant B: pinezki z promieniem - bardziej “lokalny” wariant – dobre do punktów sprzedaży, usług i działań drive-to-store.
Przed agregacją danych do powyższych obszarów za pomocą stworzonego modelu obliczyliśmy scoring dla wszystkich budynków w Polsce. Wykorzystując do tego celu ABM, takie scorowanie, mimo dużego rozmiaru danych wejściowych – tabela ok. 8 mln rekordów i około 800 kolumn, nie było wyzwaniem.
Metody agregacji scoringu do kodów pocztowych: średnia, mediana i top‑quantile
Każdy kod pocztowy obejmuje wiele adresów, więc musimy zredukować zbiór scoringów do jednej wartości opisującej “potencjał” obszaru. Są trzy praktyczne podejścia (każde ma inny sens biznesowy):
- Średnia scoringu (mean) – dobra miara do oceny przeciętnej jakości obszaru, ale wrażliwa na obserwacje odstające np. kilka adresów o bardzo wysokim scoringu
- Mediana scoringu (median) – miara odporna na obserwacje odstające, a więc sytuacje dużego zróżnicowania scoringu w obrębie kodu pocztowego, ale może być niższa gdy mała część adresów charakteryzuje się bardzo wysokim potencjałem
- Top-quantile (np. 90. percentyl lub średnia top 10% adresów w kodzie) – wskazuje czy w danym kodzie pocztowym istnieje wystarczająco duża pula adresów o bardzo wysokim scoringu
Dodatkowo jeśli istnieje możliwość warto uwzględnić wagi populacyjne np. liczba mieszkańców, liczba gospodarstw domowych, tak aby odzwierciedlić również skalę rynku.
W praktyce stosuje się dwie miary równolegle, w naszej analizie zastosowaliśmy:
- quality_score_zip - wartość 90. percentyla scoring w kodzie pocztowym
- volume_zip – liczba ludności w kodzie pocztowym
Scoring można zaprezentować w postaci wizualizacji mapowej w celach poglądowych, a także oceny wizualnej rozkładu przestrzennego.
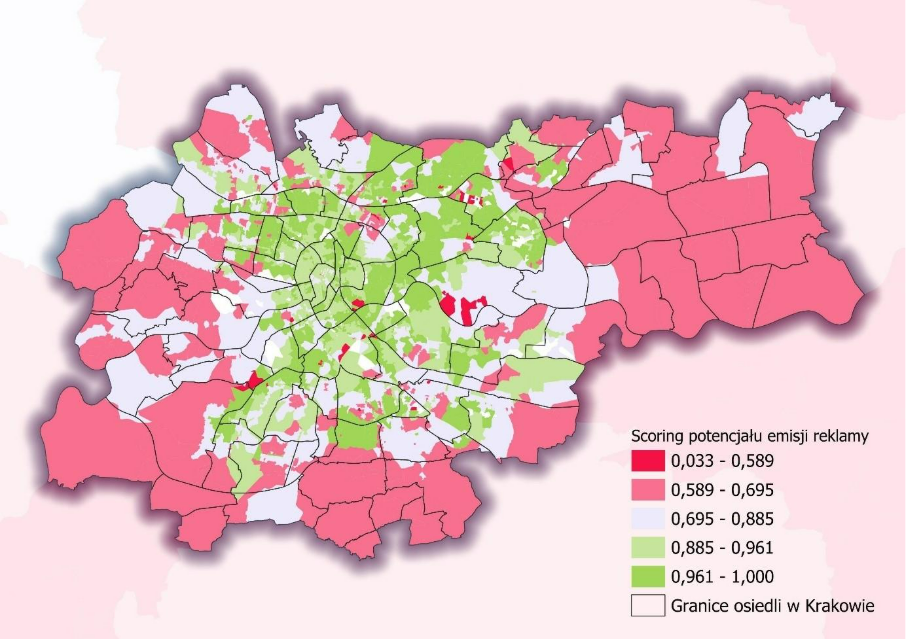
Jak scoring na poziomie kodu jest już policzony kolejnym krokiem jest decyzja, które kody pocztowe powinny trafić do kampanii jako te z wysokim potencjałem. W praktyce najlepiej działają progi kwantylowe:
- Top 5% – najbardziej agresywny, mała lista kodów, najwyższa jakość, zwykle najwyższy lift, ale mniejsza skala.
- Top 10% – złoty środek - wciąż wysoka jakość, a skala pozwala stabilnie “dowieźć” emisję.
- Top 20% – szerzej, bardziej skalowalne, ale z mniejszym liftem.
Symulacja: porównanie losowej emisji vs geotargetowania po top kodach pocztowych (CPA, ROAS, zasięg)
Żeby pokazać biznesową wartość geo-scoringu przygotowaliśmy symulację scenariuszową. Jej cel jest prosty: sprawdzić, jak zmienia się spodziewana efektywność kampanii, gdy mamy do dyspozycji ten sam budżet i tą samą intensywność emisji (liczba wyświetleń, liczba unikalnych oglądających, średnia liczba wyświetleń na osobę) kierujemy:
- w scenariuszu bazowym: szeroko / losowo (cała Polska lub szeroki targeting),
- w scenariuszu geo: tylko do najlepszych kodów pocztowych.
W naszym teście nie wykonujemy pomiaru inkrementalności reklamy (do tego potrzebny jest realny eksperyment z ekspozycją). Symulacja pokazuje, jak zmienia się oczekiwana efektywność, gdy przenosimy emisję na obszary o wyższym “potencjale” wyliczonym przez model ML.
Parametry i założenia symulacji kampanii digital: budżet, CPM, frequency i wielkość audytorium
Symulacja bazuje na standardowych pojęciach z media planu, które przedstawiamy poniżej.
1. Budżet kampanii (Budget)
Kwota, którą planujemy wydać w danym okresie – zakładamy ją na poziomie 50 000 zł.
2. CPM
Koszt tysiąca wyświetleń - może on przyjmować różne wartości w zależności od celu kampanii (sprzedaż vs zasięg), konkurencji w aukcji, sezonowości, jakości kreacji itd. dlatego w naszej analizie przyjęliśmy 3 warianty wartości CPM:
- Wariant „niski” CPM = 15 zł – przy założeniu sprzyjających warunków
- Wariant „bazowy” CPM = 30 zł – poziom realny dla większości kampanii, z bardziej precyzyjnym targetem i przy założeniu udziału kampanii w konkurencyjnej aukcji.
- Wariant „wysoki” CPM = 60 zł – na potrzeby symulacji trudniejszych warunków np. sezon świąteczny, Black Friday, dla wąskiego targetu i z intensywną konkurencją.
Z CPM wyliczamy liczbę wyświetleń (Impressions):
Impressions=BudgetCPM×1000
Zatem przy tym samym budżecie i wyższym CPM mamy mniej wyświetleń, a przy niższym CPM więcej.
3. Frequency
Średnia liczba ekspozycji na 1 osobę w danym okresie, która wynika z relacji między liczbą wyświetleń a wielkością audytorium, które da się w danym segmencie osiągnąć. Dlatego w geo-targetowaniu opartym o scoring warto myśleć o frequency jak o parametrze planistycznym zależnym od szerokości segmentu: im węższy segment (np. Top 5%), tym szybciej rośnie częstotliwość, bo emisja trafia do mniejszej grupy odbiorców. Na potrzeby symulacji przyjmujemy 3 różne wartości frequency dopasowane do wielkości segmentu:
- Top 5% ZIP (najbardziej precyzyjny segment) → Frequency = 5 / tydzień
To segment o najmniejszej skali, więc przy typowych budżetach częstotliwość rośnie najszybciej. Ten wariant jest dobry, gdy celem jest maksymalna koncentracja na najlepszych obszarach (np. krótka promocja, ograniczony asortyment, szybkie domykanie sprzedaży).
- Top 10% ZIP (złoty środek: jakość + stabilność emisji) → Frequency = 3 / tydzień
Segment jest już na tyle szeroki, że kampania może dowozić zasięg bez gwałtownego wzrostu częstotliwości.
- Top 20% ZIP (wariant skalowania) → Frequency = 2 / tydzień
Ten segment jest najszerszy, więc naturalnie pozwala dotrzeć do większej liczby unikalnych osób. Frequency jest niższe, ale kampania zyskuje na zasięgu i mniej budżetu jest poświęconego tej samej grupie osób.
Frequency umożliwia obliczenie zasięgu (Reach) na podstawie liczby wyświetleń:
4. Skala audytorium
Żeby przełożyć plan mediowy (budget → impressions → reach) na realny kontekst geograficzny, potrzebujemy jeszcze jednej zmiennej: ile osób “online” jest w danym obszarze. W naszych danych mamy dla kodu pocztowego zmienną opisującą skalę rynku, a dokładnie liczbę mieszkańców. Żeby oszacować liczbę potencjalnych odbiorców reklamy, przeliczamy ją na liczbę internautów:
gdzie:
- volume_zip – liczba mieszkańców,
- internet_penetration to założony odsetek internautów.
W Polsce odsetek osób regularnie korzystających z internetu jest bardzo wysoki. Według GUS w 2024 r. 87,6% osób w wieku 16–74 korzystało z internetu, co najmniej raz w tygodniu, a prawie codziennie 83,9% osób. Na potrzeby symulacji przyjmiemy więc internet_penetraion na poziomie=0.85 (w naszej liczbie ludności znajdują się również mieszkańcy spoza zakresu wiekowego 17-74 lata).
Dzięki wielkości audytorium możemy już nie tylko liczyć wyświetlenia i zasięg „w próżni”, ale też ocenić, czy dany segment geo jest wystarczająco pojemny, żeby:
- utrzymać zakładaną częstotliwość (bez “przemielenia” tej samej grupy),
- skalować budżet,
- i sensownie porównać efektywność scenariusza “szeroko” vs “high-score”.
Poniżej zestawiliśmy założenia naszej symulacji w postaci tabeli w podziale na 3 segmenty i na 3 wartości CPM.
| Budżet (PLN) | Wariant CPM | CPM (PLN) | Segment geo | Częstotliwość (Frequency) | Wyświetlenia (Impressions) | Szacowane audytorium w segmencie | Planowany zasięg (Reach) | Pokrycie audytorium (%) | Czy segment ogranicza zasięg (cap) | Koszt dotarcia do 1000 osób (PLN) |
| 50000 | niski | 15 | Top 10% ZIP | 3 | 3333333 | 2176413 | 1111111 | 51,1 | NIE | 45 |
| 50000 | niski | 15 | Top 20% ZIP | 2 | 3333333 | 3746994 | 1666667 | 44,5 | NIE | 30 |
| 50000 | niski | 15 | Top 5% ZIP | 5 | 3333333 | 1242407 | 666667 | 53,7 | NIE | 75 |
| 50000 | bazowy | 30 | Top 10% ZIP | 3 | 1666667 | 2176413 | 555556 | 25,5 | NIE | 90 |
| 50000 | bazowy | 30 | Top 20% ZIP | 2 | 1666667 | 3746994 | 833333 | 22,2 | NIE | 60 |
| 50000 | bazowy | 30 | Top 5% ZIP | 5 | 1666667 | 1242407 | 333333 | 26,8 | NIE | 150 |
| 50000 | wysoki | 60 | Top 10% ZIP | 3 | 833333 | 2176413 | 277778 | 12,8 | NIE | 180 |
| 50000 | wysoki | 60 | Top 20% ZIP | 2 | 833333 | 3746994 | 416667 | 11,1 | NIE | 120 |
| 50000 | wysoki | 60 | Top 5% ZIP | 5 | 833333 | 1242407 | 166667 | 13,4 | NIE | 300 |
Z powyższej tabeli wynika, że w naszej konfiguracji geo-targetowania nie wchodzimy w pułapkę “zbyt wąskiego targetowania”. Zbudowane segmenty (Top 5/10/20) mają na tyle dużą pojemność audytorium, że nawet przy różnych wariantach CPM i założonej częstotliwości nie obserwujemy efektu „zatkania”, czyli sytuacji, w której planowany zasięg przekracza dostępne audytorium i częstotliwość zaczyna rosnąć w sposób niekontrolowany. W praktyce oznacza to, że kampania może stabilnie dowozić emisję, a jednocześnie korzystać z precyzyjniejszej alokacji budżetu.
Analiza dwóch scenariuszy: szeroka emisja kontra precyzyjny geotargeting oparty o geo‑scoring
W kolejnym kroku wykorzystujemy powyższy plan mediowy w dwóch wariantach alokacji reklamy:
Scenariusz 1: bazowy – emisja bez geoscroingu
Zakładamy, że reklama jest kierowana szeroko na cały kraj, bez selekcji obszarów na podstawie geoscoringu. W praktyce oznacza to, że budżet „rozlewa się” po lokalizacjach o bardzo różnym potencjale: od miejsc, gdzie profil klientów jest zbliżony do dotychczasowych zamówień, po obszary, w których szansa na konwersję jest relatywnie niska.
Scenariusz 2: geotargeting po segmentach z geoscoringu
Używamy segmentów geo o najwyższym potencjale (Top 5/10/20) na podstawie wyników modelu ML. W praktyce oznacza to, że ten sam budżet i te same założenia mediowe kierujemy do obszarów, które model uznał za najbardziej podobne do lokalizacji „zakupowych”.
Musimy założyć jeszcze tylko wartości:
CTR (Click-Through Rate) – współczynnik klikalności – mówi o tym jaki odsetek wyświetleń kończy się kliknięciem, u nas CTR=0.012
CVR (Conversion Rate) – współczynnik konwersji – jaki procent kliknięć kończy się konwersją np. zamówieniem/zalupem, u nas CVR=0.02
AOV (Average Order Value) - średnia wartość zamówienia (PLN) , u nas AOV=250
Dla scenariusza bazowego przyjmujemy założoną wartość CVR, dla scenariusza z wykorzystaniem geoscoringu zakładamy wzrost efektywności proporcjonalny do liftu. Natomiast lift z modelu dotyczył pojedynczych adresów, podczas gdy kampanie wdrażamy na poziomie obszarów (kody pocztowe). Sprawdziliśmy więc jak „jakość” selekcji przenosi się po agregacji do kodów pocztowych. W tym celu policzyliśmy proxy-lift jako relację średniego score ważonego populacją adresów położonych w segmentach kodów pocztowych top 5/10/20% do średniego score w całej populacji adresów. Dodatkowo policzyliśmy miarę „rozmycia” jako stosunek średniego score do 90. percentyla w segmencie. Wyniki zestawiliśmy w tabeli:
| Segment | Średni score ważony populacją | Proxy-lift | Miara rozmycia |
| 5% | 0.9767 | 1.714x | 0.888 |
| 10% | 0.9650 | 1.693x | 0.870 |
| 20% | 0.9413 | 1.652x | 0.845 |
Wyniki pokazują, że nawet po agregacji geo zyskujemy wyraźną przewagę nad szeroką emisją: Top 5% ZIP daje ~1.714×, Top 10% ~1.693×, a Top 20% ~1.652× wyższy oczekiwany potencjał (proxy) względem baseline (0.5). Wartości rozmycia potwierdzają, że agregacja do obszarów naturalnie miesza lepsze i słabsze punkty, ale mimo tego segmenty pozostają silnie selektywne.
Wyniki symulacji geotargetowania: wpływ segmentów Top 5/10/20% na konwersje, CPA i ROAS
W przeprowadzonej przez nas symulacji staraliśmy się odpowiedzieć na pytanie - czy alokacja budżetu do obszarów wybranych przez geoscoring może dać lepszy wynik niż losowa emisja reklamy po całej Polsce – przy tym samym budżecie? W tym celu policzyliśmy na podstawie wcześniejszych założeń:
Liczbę kliknięć:
Liczbę konwersji:
Dla scenariuszy z geo-targetowaniem jako CVR przyjmujemy
Przychód:
CPA (Cost Per Action):
Zwrot wydatków na reklamę:
Wyniki dla różnych scenariuszy przedstawiliśmy w poniższej tabeli:
| Scenariusz (Scenario) | CPM [PLN] | Kliknięcia (Clicks) | CVR | Konwersje (Conversions) | CPA [PLN] | Przychód [PLN] (Revenue) | ROAS | ROI na przychodzie |
| RANDOM_ALL | 15 | 40000 | 0,02 | 800 | 62,5 | 200000 | 4 | 3 |
| Top 10% ZIP | 15 | 40000 | 0,03386 | 1354 | 36,92 | 338600 | 6,77 | 5,77 |
| Top 20% ZIP | 15 | 40000 | 0,03304 | 1322 | 37,83 | 330400 | 6,61 | 5,61 |
| Top 5% ZIP | 15 | 40000 | 0,03428 | 1371 | 36,46 | 342800 | 6,86 | 5,86 |
| RANDOM_ALL | 30 | 20000 | 0,02 | 400 | 125 | 100000 | 2 | 1 |
| Top 10% ZIP | 30 | 20000 | 0,03386 | 677 | 73,83 | 169300 | 3,39 | 2,39 |
| Top 20% ZIP | 30 | 20000 | 0,03304 | 661 | 75,67 | 165200 | 3,3 | 2,3 |
| Top 5% ZIP | 30 | 20000 | 0,03428 | 686 | 72,93 | 171400 | 3,43 | 2,43 |
| RANDOM_ALL | 60 | 10000 | 0,02 | 200 | 250 | 50000 | 1 | 0 |
| Top 10% ZIP | 60 | 10000 | 0,03386 | 339 | 147,67 | 84650 | 1,69 | 0,69 |
| Top 20% ZIP | 60 | 10000 | 0,03304 | 330 | 151,33 | 82600 | 1,65 | 0,65 |
| Top 5% ZIP | 60 | 10000 | 0,03428 | 343 | 145,86 | 85700 | 1,71 | 0,71 |
Wyniki symulacji jednoznacznie wskazują, że kierowanie tej samej intensywności reklamy w obszary geograficzne z większym scoringiem mogą realnie zmienić ekonomię kampanii (CPA i ROAS). Dla agencji marketingowych jest to o tyle ważne, że geo-scoring i geo-targetowanie stają się dodatkową dźwignią optymalizacji kampanii digital. W praktyce marketerzy bardzo często optymalizują kreacje i targety behawioralne, a geografia zostaje „na domyślnych ustawieniach”. Nasza symulacja pokazuje, że sama alokacja geograficzna może przełożyć się na ponad półtorakrotną różnicę w liczbie konwersji.
Przy tym samym budżecie geotargeting ROAS rośnie z 2,00 do 3.43. Przejście z szerokiej emisji na Top 10% kodów pocztowych zwiększa liczbę konwersji z 400 do 686 (czyli +71,5%), a jednocześnie obniża CPA z 125 zł do 72,93 zł.
Gdy CPM jest wysoki geotargeting działa jak „zabezpieczenie”, scenariusz losowy wychodzi w zasadzie na 0 (ROAS=1), a wszystkie segmenty geo pozwalają na poprawę tego wyniku. Wniosek jest jednoznaczny - bardziej opłaca się precyzyjniej alokować droższe wyświetlenia w obszary o wyższym potencjale.
Tworzenie segmentów geo opartych na pinezkach i promieniach oraz kontrola overlapu
Posiadając informacje o scoringu lokalizacji na poziomie punktu adresowego możemy wychwycić bardzo lokalne „wsypy” wysokich wartości, co pozwala na jeszcze bardziej precyzyjne targetowanie. Ma to szczególnie znaczenie w regionach geograficznych, gdzie kody pocztowe obejmują duże powierzchniowo obszary i lokalna zmienność „rozmywa się”. Można to zaobserwować na poniższej wizualizacji, gdzie zaprezentowaliśmy porównanie wielkości kodów pocztowych na obszarze Warszawy i sąsiednich gmin. Można na niej również zaobserwować bardzo szczegółowy podział kodowy na obszarze Warszawy – gdzie jeden kod pocztowy obejmuje kilka, a w skrajnych przypadkach zaledwie jeden budynek. W praktyce oznacza to, że chcąc targować po kodzie pocztowym i chcąc objąć zasięgiem większą część miasta musimy ich przekazać listę zawierającą setki kodów pocztowych.
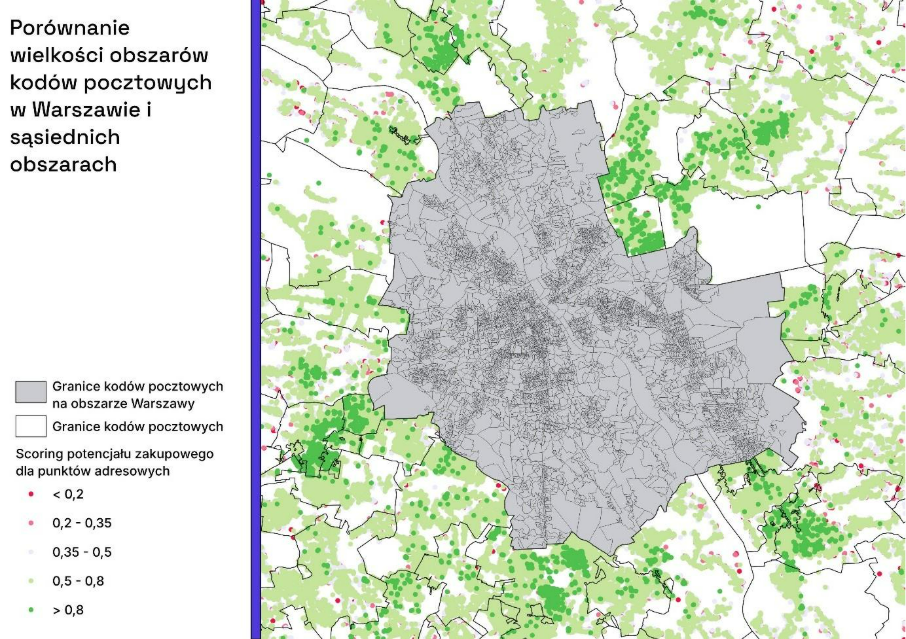
Jak wcześniej wspominaliśmy w praktyce platformy reklamowe nie pozwalają targetować pojedynczych adresów. Natomiast kody pocztowe są mało heterogeniczne pod względem wielkości obszaru na którym obowiązują, co może być uciążliwe w momencie tworzenia kampanii marketingowej. Istnieje jednak inny sposób na precyzyjne geo-targetowanie - obszary wyznaczone na podstawie listy pinezek (punktów) z promieniem. W praktyce z wykorzystaniem scoringu potencjału zakupowego będzie to zestaw okręgów, które łącznie mają pokrywać najlepsze pod względem potencjału lokalizację, ale bez dublowania emisji w tych samych miejscach.
Punktem wyjścia wyznaczenia takich obszarów jest tabela ze scoringiem dla punktów adresowych oraz dodatkowymi atrybutami skali, które pozwalają oszacować wielkość audytorium. Dzięki zasobom danych przestrzennych, które posiadamy mogliśmy do tego celu wykorzystać liczbę mieszkańców przypisaną do punktu adresowego. Dzięki tym informacjom mogliśmy policzyć spodziewany potencjał konwersyjny w każdym punkcie adresowym.
Zależało nam na tym, żeby analogicznie do scenariusza z wyborem kodów pocztowych zbudować trzy poziomy koncentracji budżetu:
- Top 5% – najbardziej precyzyjny zestaw obszarów (najwyższy potencjał w małej liczbie lokalizacji),
- Top 10% – „złoty środek” (jakość + stabilność),
- Top 20% – wariant skalowania.
W przypadku pinezek definiujemy te segmenty w sposób mass-based: dokładamy kolejne okręgi tak długo, aż suma „pokrytego” potencjału (expected_conv) osiągnie 5%, 10% i 20% całkowitej wartości w danych.
Kluczowym problemem w geotargetingu punktowym jest overlap: jeżeli okręgi mocno na siebie nachodzą, reklamowo płacimy za emisję w tych samych obszarach wielokrotnie. Dlatego w algorytmie wprowadziliśmy twardą kontrolę nakładania się okręgów . Dzięki temu lista pinezek jest krótsza i bardziej „czysta” mediowo, a budżet pracuje na nowe geografie zamiast kręcić się w kółko na tych samych użytkownikach.
Algorytm który opracowaliśmy maksymalizuje sumę potencjału konwersji i działa w kilku krokach:
- Kandydaci na centra: w każdej iteracji rozważamy pewną pulę punktów o wysokim potencjale konwersji jako potencjalne środki okręgów
- Test promieni: dla każdego kandydata sprawdzamy kilka promieni z dopuszczalnego zakresu (platformy reklamowe mogą mieć ograniczenia na wielkość promienia). Dla każdego promienia liczymy:
- jaki dodatkowy potencjał pokryjemy,
- jaką dodatkową skalę audytorium obejmiemy,
- jaka jest jakość obszaru – jako miarę przyjęliśmy 90 percentyl potencjału punktów adresowych znajdujących się w obszarze
- Wybór najlepszego okręgu: wybieramy kombinację (centrum + promień), która maksymalizuje jakość p90, a jednocześnie nie pokrywa zbyt dużego obszaru co sprzyja „rozmyciu” potencjału. Dodatkowo odrzucamy okręgi, które nie spełniają minimalnych warunków skali (np. zbyt małe audytorium) lub zbyt mocno nachodzą na już wybrane okręgi.
- Aktualizacja pokrycia: wszystkie punkty, które znalazły się w nowym okręgu, oznaczamy jako pokryte i przechodzimy do kolejnej iteracji.
W efekcie otrzymaliśmy listę okręgów i promieni, gotową do uploadu do platform reklamowych. W naszej analizie w sumie utworzone zostały 64 obszary, gdzie każdy kolejny segment jest rozszerzeniem poprzedniego. Do pokrycia 5% potencjału wystarczyło zaledwie 9 punktów, 10% - 22 punkty, a do pokrycia 20% potencjału konwersji – 64 punkty. Utworzone pinezki przedstawia poniższa wizualizacja. Warto zwrócić uwagę, że wyznaczone w ten sposób obszary są wolne od sztucznych podziałów administracyjnych (np. granice gmin, miast) czy pocztowych, co pozwala na bardziej „szczegółowe” dotarcie (przykład: obszar na południu wizualizacji położony jest na styku 4 różnych gmin).
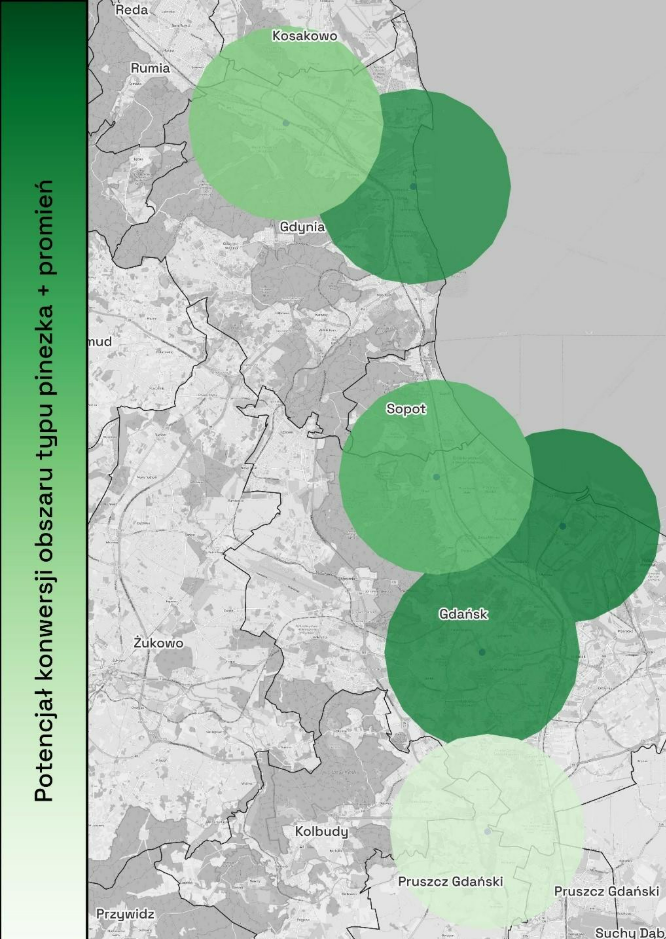
Symulacja wyników kampanii dla segmentów opartych na pinezkach - wpływ na konwersje i ROAS
Po wyznaczeniu najbardziej optymalnych obszarów mogliśmy przejść do symulacji. Założenia były identyczne jak w podejściu geo-targetowania po kodzie pocztowym. To co się różniło to proxy-lift w wyznaczonych segmentach, czyli wartość mówiąca o tym ile razy lepszy jest „potencjał konwersyjny” w wybranym segmencie geo względem emisji losowej. Wyniki zestawiliśmy w tabeli:
| Segment | Średni score ważony populacją korzystającą z Internetu | Proxy-lift | Miara rozmycia |
| 5% | 0.902 | 1.582x | 0.909 |
| 10% | 0.875 | 1.535x | 0.883 |
| 20% | 0.832 | 1.461x | 0.842 |
Wynik jest bardzo czytelny – segmenty z obszarów typu pinezka promień mają istotnie wyższy potencjał niż emisja losowa. Chcąc być precyzyjnym geotargeting na pinezkach powinien pozwolić osiągnąć ok. +46–58% lepszy wynik na etapie konwersji – przy tej samej liczbie kliknięć.
Symulację przeprowadziliśmy w dwóch scenariuszach analogicznych do tych zastosowanych w wariancie geo-targetingu po kodzie pocztowym:
Scenariusz RANDOM_ALL - losowe sianie reklamy
Zakładamy, że emitujemy reklamę szeroko w całym kraju (bez wykorzystania geo-scoringu). W tym podejściu przyjmujemy bazowy poziom konwersji (CVR).
Scenariusz GEO - geotargeting na pinezkach
Budżet i media-plan są takie same, ale emisję ograniczamy do obszarów wybranych algorytmem „pinezka + promień” dla segmentów Top 5/10/20%. Jedyna zmiana w mechanice wyniku to to, że CVR rośnie proporcjonalnie do proxy-liftu.
W scenariuszu geo audytorium segmentu nie wynika z liczby adresów w obszarze, tylko z sumy liczby użytkowników internetu. To ważne, bo pozwala policzyć, czy kampania „nie zatyka się” na zbyt małym audytorium.
W naszych wariantach zasięg (reach) jest w pełni dostarczalny (pokrycie audytorium < 100%), natomiast w wąskim segmencie Top 5% widać większe nasycenie:
- przy CPM=15 planowane pokrycie audytorium to ok. 65% - czyli intensywna kampania w małej grupie u=osób,
- segmenty Top 10% / Top 20% są wyraźnie „bezpieczniejsze” (niższe pokrycie audytorium) i lepiej nadają się do stabilnej emisji.
Poniżej znajdują się wyniki symulacji:
| Scenariusz (Scenario) | CPM [PLN] | Kliknięcia (Clicks) | CVR | Konwersje (Conversions) | CPA [PLN] | Przychód [PLN] (Revenue) | ROAS | ROI na przychodzie | Pokrycie audytorium [%] |
| RANDOM_ALL | 15 | 40000 | 0,02 | 800 | 62,5 | 200000 | 4 | 3 | 5,4 |
| Top 10% PINS | 15 | 40000 | 0,0307 | 1228 | 40,73 | 306913 | 6,14 | 5,14 | 54 |
| Top 20% PINS | 15 | 40000 | 0,0292 | 1168 | 42,79 | 292124 | 5,84 | 4,84 | 39,1 |
| Top 5% PINS | 15 | 40000 | 0,0316 | 1266 | 39,5 | 316418 | 6,33 | 5,33 | 65,3 |
| RANDOM_ALL | 30 | 20000 | 0,02 | 400 | 125 | 100000 | 2 | 1 | 2,7 |
| Top 10% PINS | 30 | 20000 | 0,0307 | 614 | 81,46 | 153456 | 3,07 | 2,07 | 27 |
| Top 20% PINS | 30 | 20000 | 0,0292 | 584 | 85,58 | 146062 | 2,92 | 1,92 | 19,5 |
| Top 5% PINS | 30 | 20000 | 0,0316 | 633 | 79,01 | 158209 | 3,16 | 2,16 | 32,7 |
| RANDOM_ALL | 60 | 10000 | 0,02 | 200 | 250 | 50000 | 1 | 0 | 1,3 |
| Top 10% PINS | 60 | 10000 | 0,0307 | 307 | 162,91 | 76728 | 1,53 | 0,53 | 13,5 |
| Top 20% PINS | 60 | 10000 | 0,0292 | 292 | 171,16 | 73031 | 1,46 | 0,46 | 9,8 |
| Top 5% PINS | 60 | 10000 | 0,0316 | 316 | 158,02 | 79104 | 1,58 | 0,58 | 16,3 |
Geotargeting poprawia wynik kampanii bez zwiększania budżetu – przy tej samej liczbie kliknięć rośnie liczba konwersji, spada CPA i rośnie ROAS/ROI.
W wariancie sprzyjających warunków i niskim CPM = 15 zł geotargeting daje +~90–116 tys. PLN dodatkowego przychodu (Top 10–5%), a koszt pozyskania spada o ~20+ PLN na konwersję. W wariancie bazowym czyli CPM = 30 zł realną wartością dodaną jest zmniejszenie CPA o 35-37%. Dla agencji oznacza to większą przestrzeń na skalowanie. W trudnych warunkach aukcyjnych czyli wysokim CPM = 60zł geotargeting pozwala osiągnąć dodatni ROI podczas gdy losowa emisja reklamy wychodzi na zero.
Wnioski dla agencji: jak geo‑scoring zwiększa konwersje, obniża CPA i wspiera skalowanie kampanii
W digital marketingu łatwo mówi się o „lepszym targetowaniu”, trudniej pokazać ile to realnie daje w kampanii sprzedażowej. Dlatego w tej analizie zrobiliśmy symulację wprost na KPI, które są wspólnym językiem agencji i klienta: konwersje, CPA, ROAS/ROI. Najważniejsze wnioski są następujące:
- Geotargetowanie to „dźwignia wyników”, a nie kosmetyka targetowania
Przy tym samym budżecie i tej samej liczbie kliknięć nasza symulacja wskazuje na wzrost konwersji na poziomie +48% aż do +71%. To łatwy argument w rozmowie z klientem, który przemawia sam za siebie, bez potrzeby tłumaczenia wyników modelowania.
- CPA spada, więc rośnie przestrzeń do skalowania
Geo-segmenty pozwalają na obniżenie CPA od ok.31% do 46%, a więc dają miejsce na skalowanie lub na utrzymanie KPI w trudniejszych warunkach (np. trudny sezon).
- Segmenty geo są wdrożeniowe i testowalne
Korzystając z wyników szczegółowych – scoring na poziomie punktu adresowego, tworzymy segmenty geo które są gotowe do wdrożenia w kampaniach marketingowych – lista kodów pocztowych lub lista pinezek z promieniami. Segmenty takie Agencja reklamowa może wykorzystać do testowania różnych podejść np. wybierając top 5% segmentów do krótkich akcji sprzedażowych.
Dlaczego wdrożenie geo‑scoringu i segmentów geo jest łatwe z Algolytics (dane, modele, MLOps)
To, co w kampanii wygląda jak „lista obszarów”, w rzeczywistości wymaga spójnego pipeline’u danych i modeli. Ważna jest też powtarzalność i możliwości odtwarzania scenariusza przy różnych założeniach, klientach i podejściach. Tu właśnie jest przewaga rozwiązań Algolytics:
- Dane przestrzenne na poziomie punktu adresowego
Bogaty i szczegółowy zbiór danych przestrzennych zawierający informacje o cechach otoczenia, demografii, dostępności POI itd. dla pojedynczych punktów adresowych jest podstawą do utworzenia modelu wysokiej jakości.
- Model predykcyjny propensity + scoring w całej Polsce (ABM)
Automatic Bussiness Modeler pozwala na utworzenie modelu typu look alike w oparciu o dane o zamówieniach/leadach i dane przestrzenne, a potem oscorować tym modelem wszystkie adresy w Polsce, co jest podstawą do wyznaczenia geo-segmentów.
- Analityka przestrzenna do tworzenia segmentów geo
Na podstawie geo-scoringu wyznaczonego dla punktów adresowych zastosowanie agregacji do kodów pocztowych (np. z wykorzystaniem mapy kodów pocztowych) i technologii analiz przestrzennych pozwala na wyznaczenie segmentów geograficznych z niezbędną kontrolą jakości (np. overlapu).
- Zamknięcie całości w procesie MLOps (ScoringOne)
Cały proces można szybko wdrożyć z wykorzystaniem ScoringOne co zapewnia powtarzalne uruchomienia, wersjonowanie, eksportowanie gotowych danych do kampanii. Dzięki temu uruchomienie produkcyjnej usługi dla wielu klientów agencji skraca się do 3-5 tygodni.
Warto zwrócić uwagę na fakt, że cały proces ma minimalne wymagania jeśli chodzi dane wejściowe – wystarczą adresy zamówień/leadów z ostatniego okresu np. 3/6 miesięcy. Pozostałe elementy procesu realizuje platforma Algolytics, co można prześledzić na poniższych schemacie.
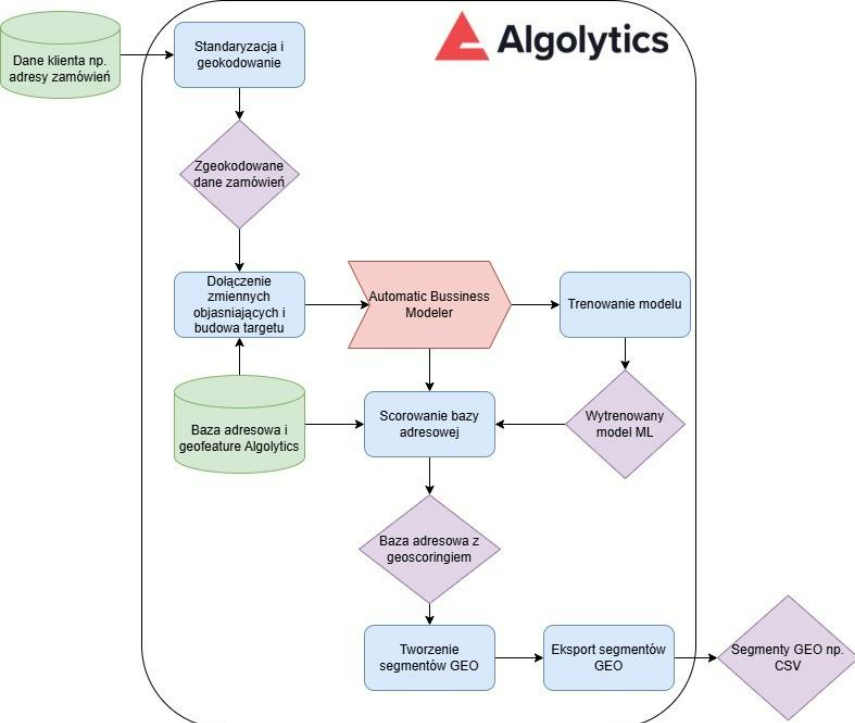
Kolejne kroki: wdrożenie segmentów geo, testy A/B i cykliczne odświeżanie scoringu
Na koniec warto podkreślić, że przejście od geo-scoringu do realnej kampanii to już nie „kolejna analiza”, tylko prosty proces wdrożeniowy. Lista kroków jest następująca:
- Wybranie wariantu wdrożeniowego i segmentu startowego: zwykle zaczyna się od Top 10% jako kompromisu „jakość + skala”, a Top 5% i Top 20% traktuje jako warianty testowe (precyzja vs skalowanie).
- Wgranie segmentów geo na platformę reklamową:
- w Meta najczęściej w praktyce wdraża się pinezki + promień,
- w Google Ads można stosować zarówno punkty i promienie, jak i – tam gdzie jest to dostępne – kody pocztowe.
- Sprawdzenie deliverability: należy upewnić się, że segmenty nie są zbyt wąskie (ryzyko „zatkania” i zbyt wysokiej częstotliwości).
- Mierzenie wyników na KPI sprzedażowych: konwersje, CPA, ROAS/ROI. Segmenty Top 5/10/20 należy traktować jako gotową oś decyzyjną „precyzja vs skala”.
Ustalenie cyklu odświeżania segmentów: największą przewagę daje powtarzalny proces – np. co miesiąc/kwartał odświeżamy model na nowych danych, przeliczamy scoring i eksportujemy nowe segmenty do kampanii, co można łatwo zrobić z wykorzystaniem platformy Algolytics.
Rozważasz zastosowanie geo‑scoringu w swoich kampaniach Meta lub Google? Zapraszamy do kontaktu.
Na podstawie posiadanych danych przygotujemy adekwatny scenariusz przetwarzania i udostępnimy gotowe API, które pozwoli samodzielnie odświeżać segmenty zgodnie z potrzebami Twojego zespołu marketingowego.



