















Wyzwanie przetwarzania zdarzeń w czasie rzeczywistym
Współczesne systemy generują ogromne liczby zdarzeń online (kliknięć, transakcji, sygnałów IoT itp.) w ciągu każdej sekundy. Dla wielu zastosowań biznesowych kluczowa jest natychmiastowa analiza takich strumieni danych i reakcja w czasie rzeczywistym – mierzona często w milisekundach. Tradycyjne podejścia batch (przetwarzanie wsadowe) zawodzą przy takich wymaganiach, gdyż operują na minutowych lub godzinnych interwałach, podczas gdy stream processing dostarcza wyniki w ułamkach sekund. Aby agregować cechy (features) z milionów napływających zdarzeń w czasie rzeczywistym, potrzebne są wyspecjalizowane architektury i narzędzia stream processing.
Od wykrywania oszustw po personalizację treści: uczenie maszynowe w czasie rzeczywistym w praktyce
Dobrym przykładem jest personalizacja treści lub wykrywanie nadużyć finansowych, gdzie decyzje muszą zapadać tu i teraz na podstawie najświeższych danych. Firmy takie jak Netflix czy UPS przetwarzają strumieniowo miliony zdarzeń na sekundę, aby generować rekomendacje w czasie rzeczywistym i usprawniać operacje. Tak ogromna skala i wymóg niskich opóźnień (rzędu ms) wykluczają wykorzystanie klasycznych baz danych lub hurtowni do bieżącej agregacji – potrzebne jest dedykowane narzędzie feature store dla danych strumieniowych.
Scoring w czasie rzeczywistym wymaga specjalistycznej architektury
Algolytics Event Engine został zaprojektowany właśnie z myślą o takich wyzwaniach. Umożliwia przetwarzanie strumieni danych z opóźnieniem poniżej 5 ms (łącznie z wyliczeniem wyniku modelu), zachowując jednocześnie skalowalność do tysięcy zdarzeń na sekundę. W testach osiąga przepustowość rzędu 20 000 zdarzeń na sekundę na jeden węzeł systemu. Tego rzędu wydajność – połączona z natychmiastowym udostępnieniem aktualnego profilu cech – wymaga specjalizowanego rozwiązania, którego nie zapewni klasyczny silnik bazodanowy ani standardowe frameworki big data.
Obliczanie cech bez kodowania i integracja z narzędziem AutoML
Co wyróżnia Algolytics Event Engine na tle innych rozwiązań, to nie tylko szybkość przetwarzania, lecz także głęboka automatyzacja procesu budowy cech (features) oraz pełna integracja z platformą AutoML (Automatic Business Modeler). Dzięki rozbudowanemu systemowi metadanych użytkownik może konfigurować sposób obliczania cech (np. liczniki, średnie, okna czasowe, wartości skrajne) bez konieczności programowania – system automatycznie generuje nawet tysiące agregatów na podstawie definicji struktury zdarzeń.
Automatyczne generowanie danych treningowych i wdrażanie modeli
Co więcej, Event Engine potrafi nie tylko utrzymywać aktualny profil cech w czasie rzeczywistym, ale również historycznie zrekonstruować wartości cech dla danego momentu w czasie, wyliczyć zmienną celu oraz trigger decydujący o uwzględnieniu danego przypadku w zbiorze treningowym. W efekcie może w pełni automatycznie przygotować dane treningowe i uruchomić proces budowy modeli predykcyjnych, które po walidacji są natychmiast wdrażane do produkcji.
Ta pełna automatyzacja trudnego i kosztownego procesu featuryzacji oraz modelowania na danych strumieniowych stanowi jedną z najistotniejszych przewag Event Engine na tle innych narzędzi stream processingowych i ML.
Zastosowania danych strumieniowych: marketing, wykrywanie oszustw, RTB i telekomunikacja
Real-time feature store taki jak Event Engine znajduje zastosowanie wszędzie tam, gdzie liczy się bieżąca analiza zdarzeń i utrzymanie aktualnego profilu użytkownika lub obiektu. Poniżej kilka przykładów inspirowanych wdrożeniami Algolytics:
Marketing automation i DMP (np. walled garden)
W środowiskach walled garden (zamknięty ekosystem danych, np. własna strona lub aplikacja bez dostępu zewnętrznych trackerów) Event Engine umożliwia zbieranie i analizę zachowań użytkowników w czasie rzeczywistym. Przykładowo duży portal e-commerce może dzięki niemu budować profil każdego odwiedzającego na podstawie kliknięć, oglądanych produktów, czasu spędzonego na stronach itp. Zdarzenia te są natychmiast agregowane do cech (np. liczba obejrzanych artykułów danej kategorii w ciągu 5 min, ostatni czas logowania, itp.), co pozwala silnikowi rekomendacyjnemu lub systemowi DMP (Data Management Platform) reagować w ułamku sekundy – np. wyświetlić spersonalizowaną ofertę lub dodać użytkownika do segmentu marketing automation. Wszystko to odbywa się w ekosystemie własnym firmy (prywatność danych zachowana), a szybkość rzędu milisekund zapewnia interaktywność doświadczenia klienta.
Wykrywanie fraudów online (biometria behawioralna)
W nowoczesnych systemach antyfraudowych na stronach WWW analizuje się cechy behawioralne użytkownika (dynamikę pisania na klawiaturze, ruchy myszą, szybkość przewijania, kolejność kliknięć). Event Engine świetnie pasuje do takiego scenariusza – każdy ruch czy naciśnięcie klawisza generuje zdarzenie, które można w locie przekształcić w metryki behawioralne i porównać z profilem historycznym użytkownika. Feature store utrzymuje profil (tzw. odcisk behawioralny) obejmujący np. średnią szybkość pisania, typowe wzorce poruszania kursorem itp. Gdy bieżące zachowanie odbiega od normy (np. nietypowo szybkie wpisanie hasła sugerujące bot/script), Event Engine może natychmiast wyliczyć ryzyko fraudu i zwrócić wynik modelu wykrywającego oszustwo. Tego rodzaju system musi działać w czasie rzeczywistym, aby zablokować podejrzaną sesję zanim dojdzie do nadużycia.
Real-Time Bidding (RTB)
Platformy SSP (Supply Side Platform) i DSP (Demand Side Platform) w reklamie programatycznej muszą przetwarzać zdarzenia związane z emisją reklam i reakcjami użytkowników w ułamku sekundy. Event Engine może pełnić rolę wewnętrznego DMP dla wydawcy lub reklamodawcy, gromadząc strumień zdarzeń reklamowych (wyświetlenia, kliknięcia, konwersje) i utrzymując profil użytkownika lub urządzenia w czasie rzeczywistym. Gdy nadchodzi żądanie bidowania (aukcja RTB trwająca np. 50 ms), system DSP może poprzez Event Engine błyskawicznie pobrać aktualne cechy użytkownika (np. liczba reklam klikniętych w ostatniej godzinie, historia konwersji, zainteresowania) i wykorzystać je w swoim modelu do decyzji o stawce. Po stronie SSP podobny mechanizm może oceniać jakość ruchu – np. wykrywać podejrzane wzorce (fraudulentne kliknięcia) i w czasie rzeczywistym odfiltrowywać niepożądany ruch przed wystawieniem go na aukcję. Niskie opóźnienie Event Engine (<5 ms) jest tu krytyczne, bo mieści się w budżecie czasu na całą aukcję. Algolytics przygotował generyczny zestaw metadanych dla protokołu OpenRTB co czyni wdrożenie jeszcze bardziej łatwym.
Analiza danych z systemów CRM/ERP
Duże organizacje, jak operatorzy telekomunikacyjni czy instytucje finansowe, gromadzą potężne ilości danych zdarzeniowych – od logów sieciowych po interakcje klientów w call center. Event Engine pozwala zbudować w czasie rzeczywistym profil 360° klienta na podstawie strumienia takich danych. Przykładowo, dla każdego numeru telefonu można utrzymywać agregaty typu: liczba połączeń wykonanych i odebranych w ciągu ostatnich 10 minut, łączna ilość przesłanych danych w bieżącym dniu, odchylenie od średniej aktywności itp. Taki profil może zasilać modele churn prediction (wykrywanie zamiaru odejścia klienta), systemy rekomendujące pakiety lub wykrywające fraudy (np. klonowanie karty SIM, nietypowe użycie roamingu). Ponieważ skala w telekomunikacji to miliony zdarzeń na godzinę, system musi zapewniać zarówno skalowalność, jak i checkpointing stanu użytkowników. Event Engine został przetestowany w takich warunkach – potrafi przetwarzać dziesiątki tysięcy zdarzeń na sekundę, dynamicznie przenosić nieaktywnych użytkowników do pamięci trwałej i odtwarzać ich profil na żądanie, a dzięki integracji z modułem kampanijnym pozwala uruchamiać akcje marketingowe natychmiast po spełnieniu określonych warunków na profilu.
Ukryty potencjał streaming feature store
Oprócz powyższych przykładów, architektura streaming feature store sprawdza się w wielu innych domenach wymagających analizy danych w locie:
Utrzymanie predykcyjne (predictive maintenance)
Fabryki i zakłady przemysłowe coraz częściej monitorują pracę maszyn za pomocą czujników IoT, generujących ciągłe strumienie danych (temperatury, wibracje, ciśnienia). Analiza tych sygnałów w czasie rzeczywistym pozwala przewidywać awarie zanim do nich dojdzie. Typowy system predictive maintenance musi scalać dane z setek czy tysięcy sensorów i w czasie rzeczywistym wyliczać wskaźniki zdrowia urządzeń. Według AWS są to często strumienie danych o wysokiej częstotliwości, łączone z wielu źródeł IoT (setek, a nawet milionów), wymagające dedykowanej infrastruktury do niskolatencyjnego przetwarzania. Event Engine może tu pełnić rolę agregatora – liczyć na bieżąco np. średnie wibracji z ostatnich 5 minut dla każdej maszyny, odchylenia od typowych wartości, częstość przekraczania progów alarmowych itp. i udostępniać te cechy modułowi AI wykrywającemu anomalie. Gdy model przewidzi awarię (na podstawie tych cech), system może natychmiast wysłać alert. Rozwiązanie oparte o streaming zapewnia, że nic nie „prześlizgnie się między cyklami batch” – każda anomalia jest widoczna w sekundach, a nie godzinach.
Antyfraud w systemach płatniczych
Transakcje finansowe (np. płatności kartą kredytową) to klasyczny obszar wymagający detekcji oszustw w czasie rzeczywistym. Każde użycie karty generuje zdarzenie, które powinno zostać ocenione pod kątem ryzyka zanim transakcja zostanie autoryzowana. Modele wykrywające fraudy często opierają się na cechach agregowanych, np. liczba transakcji klienta w ostatniej godzinie, łączna kwota płatności w ciągu dnia, liczba różnych krajów, w których użyto karty w ciągu 24h itp. Event Engine pozwala wyliczać takie feature’y agregacyjne w locie i udostępniać je modułowi scoringowemu przed podjęciem decyzji o akceptacji transakcji. Dzięki temu system może wychwycić np. nietypową intensywność użycia karty i natychmiast zareagować (odmową lub dodatkową weryfikacją). Kluczowe jest tu zapewnienie dokładnie takich samych cech w trakcie skoringu online, jak i podczas trenowania modeli offline – Event Engine gwarantuje tę spójność, ponieważ profile cech budowane są centralnie i współdzielone między fazami treningu i działania.
Jak działa system Event Engine od Algolytics: obsługa zdarzeń online i offline
Algolytics Event Engine przetwarza zdarzenia dwutorowo: w trybie online (ciągłe aktualizowanie profilów i natychmiastowe scoringi) oraz offline (cykliczne budowanie zbiorów treningowych i modeli). Architektura systemu została zaprojektowana pod kątem wydajnej agregacji w pamięci oraz trwałego utrwalania danych do późniejszej analizy. Poniżej opisujemy poszczególne aspekty działania:
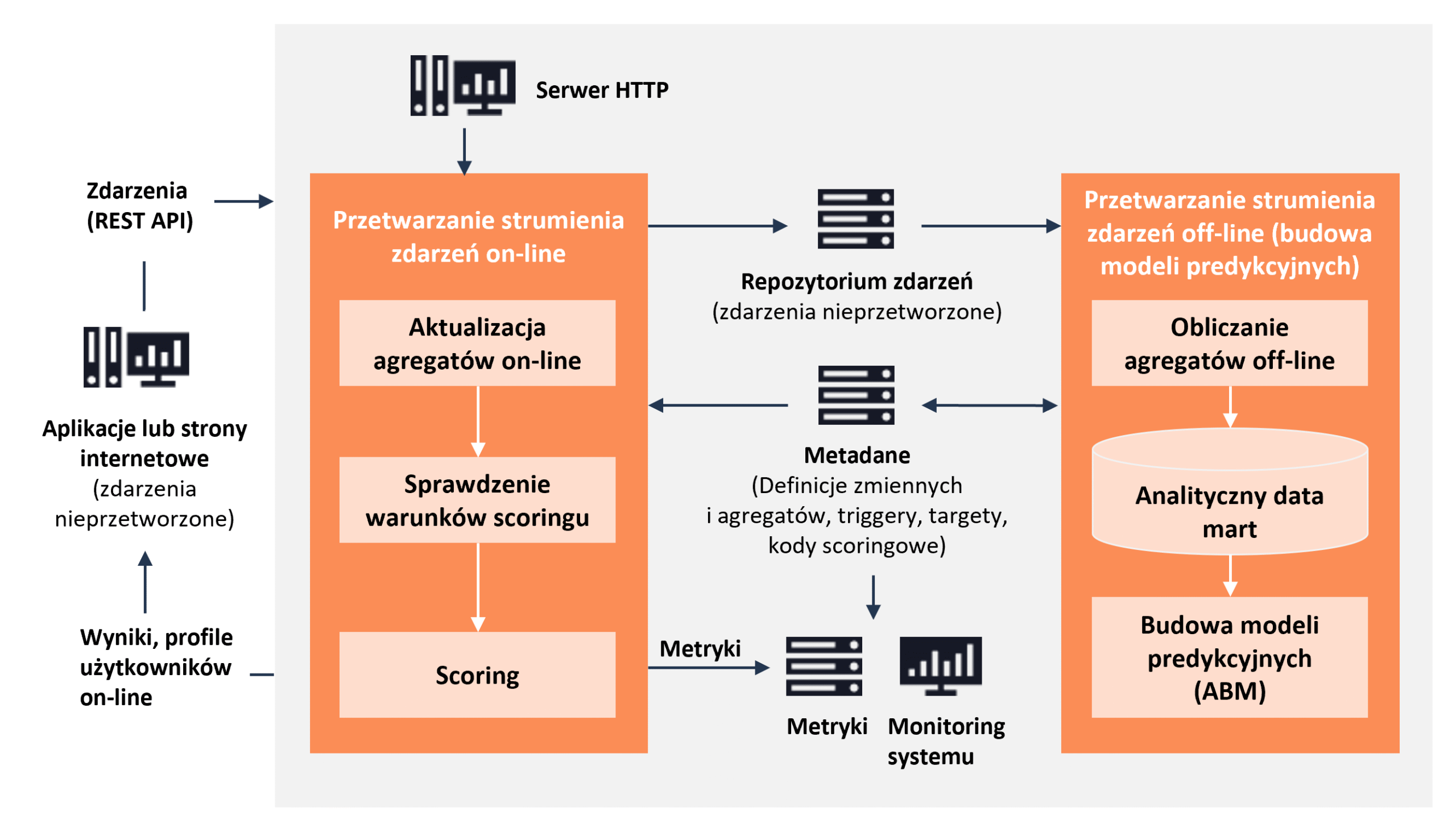
Przetwarzanie online
Zdarzenia od systemów źródłowych (np. aplikacji web) przesyłane są do Event Engine w formacie JSON przez API REST. Silnik wykorzystuje wewnętrznie kolejkę (Apache Kafka) do buforowania napływających zdarzeń. Każde zdarzenie podlega natychmiastowej transformacji – ekstrakcja zadeklarowanych zmiennych z JSON (np. poprzez wyrażenia JSONPath lub funkcje transformujące) – a następnie aktualizacji odpowiednich agregatów online powiązanych z danym obiektem (np. użytkownikiem). Aktualizacja obejmuje m.in. inkrementację liczników, dodanie wartości do okien czasowych itp., zgodnie z definicjami cech.
Po odświeżeniu profilu, silnik sprawdza warunki wyzwalające (triggery) dla modeli predykcyjnych – są to reguły decydujące, czy dane zdarzenie (i zaktualizowany profil) wymagają obliczenia predykcji modelu. Jeśli warunek dla modelu jest spełniony, Event Engine przygotowuje wektor cech dla tego użytkownika (wektor danych zawierająca wszystkie wymagane agregaty) i dokonuje scoringu – wylicza wynik modelu lub decyzję, korzystając z wbudowanego kodu modelu (wytrenowanego wcześniej przez ABM). Wynik (np. prawdopodobieństwo zdarzenia, rekomendowana akcja) zostaje zwrócony natychmiast w odpowiedzi API. Cały ten cykl – od nadejścia zdarzenia do zwrotu wyniku – zajmuje zazwyczaj pojedyncze milisekundy.
Jednocześnie zdarzenie zostaje zapisane trwale w repozytorium zdarzeń (bazie danych), co umożliwia późniejsze przeliczenie agregatów w trybie offline.
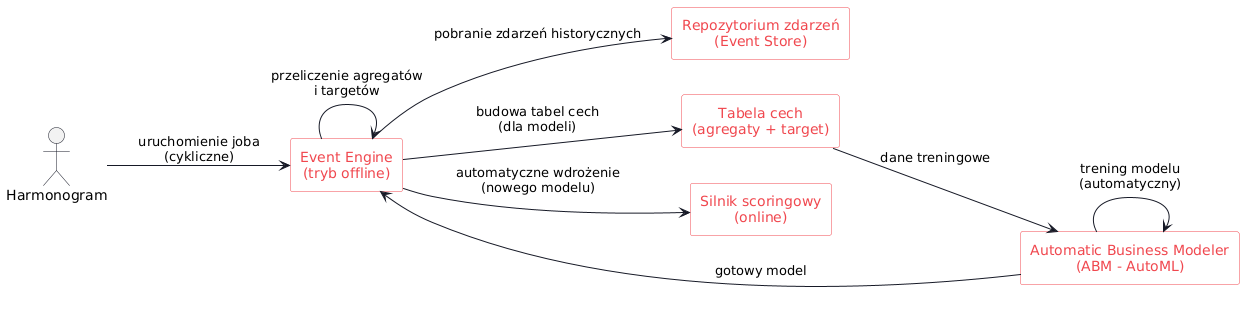
Przetwarzanie offline
Tryb offline to automatyczny proces uruchamiany w zaplanowanych odstępach (np. co noc lub co godzinę). Jego zadaniem jest historyczne przeliczenie agregatów i przygotowanie danych treningowych dla nowych modeli. Event Engine sięga do pełnego repozytorium zdarzeń i dla każdego zdefiniowanego modelu oblicza wartości wszystkich agregatów w zdefiniowanym oknie czasowym przed zdarzeniem docelowym (tzw. target window). Na tej podstawie budowana jest tabela analityczna – wiersze reprezentują obiekty (np. użytkowników), kolumny odpowiadają cechom agregowanym, a dodatkowo dołączana jest zmienna docelowa (czy nastąpiło zdarzenie targetowe, np. konwersja). Dla każdego modelu powstaje odrębna tabela, obejmująca tych użytkowników, którzy spełnili warunki ujęcia do treningu (np. wystąpienie zdarzenia triggerującego w oknie obserwacji).
Automatyczne trenowanie i wdrażanie modeli
Następnie Event Engine automatycznie inicjuje proces trenowania modeli w module Automatic Business Modeler (ABM) – przekazując mu utworzone tabele cech. ABM buduje model predykcyjny (np. za pomocą automatycznego doboru cech i algorytmów), po czym Event Engine automatycznie wdraża nowy model do trybu online.
Wdrożony model staje się aktywny w silniku scoringowym, zastępując ewentualnie poprzednią wersję (chyba że postanowiono utrzymywać wiele modeli jednocześnie). Cały pipeline – od zdarzeń, przez agregaty, po model – jest więc zautomatyzowany. Możliwe jest także zaplanowanie cyklicznego re-trenowania modeli: Event Engine może np. co tydzień uaktualniać modele, jeśli zgromadzono dostateczną ilość nowych danych i jakość modelu spełnia kryteria.
Okna czasowe i przetwarzanie w pamięci operacyjnej
Event Engine został zoptymalizowany pod kątem przetwarzania w pamięci i równoległości obliczeń. Aktualizacje agregatów wykonywane są w locie, bez konieczności odpytywania bazy – bieżące wartości cech utrzymywane są w strukturach w pamięci RAM dla aktywnych obiektów.
System obsługuje klasyczne typy okien czasowych i zdarzeniowych, znane ze stream processing:
- okna tumbling (np. 5-minutowe niepokrywające się),
- okna sliding/przesuwne (np. 1-godzinne przesuwane co 5 minut),
- okna zliczające stałą liczbę zdarzeń itp.
- Ponadto unikatową funkcją jest tzw. okno bieżące (real-time window), odpowiadające typowi WINDOW_CURRENT_TIME. Okno to odzwierciedla agregat liczony od „teraz” wstecz o zadany interwał, aktualizowany w sposób ciągły (tj. jego wartość zmienia się wraz z każdym nowym zdarzeniem, bez czekania na domknięcie okna).
Przykład: standardowe okno 1-minutowe tumbling zaktualizuje wartość agregatu raz na minutę, podczas gdy okno bieżące 60-sekundowe będzie odświeżać wartość po każdym zdarzeniu, zawsze biorąc pod uwagę ostatnie 60 sekund danych. Zapewnia to maksymalną świeżość cechy kosztem większego obciążenia obliczeniami. Zaleca się używać okien bieżących tylko tam, gdzie to niezbędne, ze względu na ich wysoką złożoność obliczeniową i pamięciową – niemniej możliwość taka istnieje (większość silników, jak Flink, domyślnie operuje na oknach dyskretnych).
Inteligentne zarządzanie pamięcią: checkpointing
Event Engine oferuje też mechanizmy checkpointingu stanu – rzadko używane lub nieaktywne profile użytkowników mogą być automatycznie przenoszone do pamięci trwałej (na dysk) i odtworzone przy kolejnym zdarzeniu tego użytkownika. Dzięki temu system efektywnie zarządza pamięcią, utrzymując bardzo dużą liczbę profili (rzędu milionów) bez degradacji wydajności.
Wizualizacje różnych algorytmów obliczania agregatów okienkowych:
- Tumbling window - zdarzenia są podsumowywane w stałych, niezmiennych przedziałach czasowych. Wartość zmienia się po zamknięciu okna.

- Sliding window - zdarzenia są podsumowywane w stałych przedziałach czasowych, jednak w tym przypadku okna nakładają się na siebie, dzięki czemu uzyskujemy częstsze aktualizacje wartości niż w przypadku tumbling window.

- Real time window – Wartości agregatów są obliczane w czasie rzeczywistym.

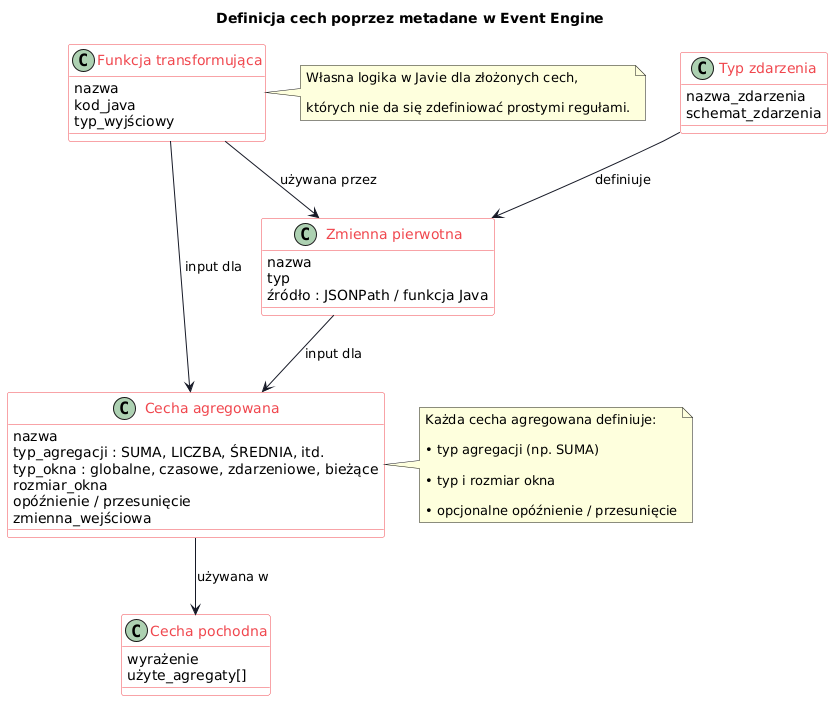
Definiowanie zmiennych pierwotnych i agregatów
Konfiguracja Event Engine odbywa się poprzez metadane opisujące strukturę zdarzeń i sposób wyliczania cech. Wszystkie definicje są przechowywane w centralnej bazie, co zapewnia spójność między środowiskami i łatwość zarządzania wersjami cech.
Analityk definiuje najpierw zbiór zmiennych pierwotnych (variables) wyciąganych ze zdarzeń – np. dla zdarzenia typu PageView mogą to być: url strony, timeOnPage, browser itp. Każda taka zmienna może być zdefiniowana przez wyrażenie JSONPath odnoszące się do pola w strukturze zdarzenia lub przez formułę (w Javie) przekształcającą wartości.
Następnie na zmiennych (oraz na wcześniej zdefiniowanych agregatach) buduje się agregaty – czyli cechy wynikowe, które będą utrzymywane w profilu. Definiując agregat, wskazujemy m.in. typ agregacji (np. SUMA, LICZBA, ŚREDNIA, MAX, MIN itp. – Event Engine dostarcza kilkanaście wbudowanych funkcji), typ okna (globalne, czasowe, zdarzeniowe, bieżące), rozmiar okna (np. 100 zdarzeń lub 7 dni) oraz ewentualne przesunięcie okna i opóźnienie (lag). Można także definiować agregaty pochodne (derived aggregates) jako wyrażenia łączące inne agregaty – np. ratio dwóch sum lub różnicę między bieżącą a historyczną wartością cechy.
Generowanie agregatów oparte na wzorcach
Co istotne, Event Engine upraszcza tworzenie dużej liczby cech: wiele agregatów można wygenerować automatycznie na podstawie wzorca. Przykładowo, mając zdarzenie z 10 polami liczbowymi, można jednym poleceniem wygenerować dla każdego z nich zestaw agregatów (licznik, suma, średnia w 3 oknach czasowych itp.). Ta możliwość automatycznej generacji tysięcy agregatów znacząco przyspiesza przygotowanie danych treningowych.
Niestandardowe cechy i elastyczność systemu metadanych
Dodatkowo, elastyczność zapewnia opcja definiowania własnych transformacji w Javie – jeśli potrzebna cecha nie daje się wyrazić prostą agregacją, można napisać funkcję, która na bieżąco przetworzy surowe zdarzenie w wartość cechy (np. wyznaczy odległość geograficzną na podstawie współrzędnych GPS). Takie niestandardowe cechy również mogą być agregowane w oknach.
System metadanych sprawia, że zmiana definicji cechy nie wymaga zmian w kodzie – wystarczy aktualizacja wpisu w metadanych i przeładowanie konfiguracji silnika. Ułatwia to iteracyjne ulepszanie modelu przez data scientistów.
Integracja ze Scoring.One (MLOps od Algolytics)
Algolytics Event Engine można wykorzystywać samodzielnie (odbiera zdarzenia i zwraca wyniki scoringu poprzez swoje API), ale pełnię możliwości osiąga w połączeniu z modułem Scoring.One – silnikiem decyzyjnym MLOps, który odpowiada za wdrażanie i orkiestrację modeli predykcyjnych.
Scoring.One jest stateless (bezstanowy) – każdorazowe żądanie scoringu traktuje niezależnie, nie przechowując kontekstu użytkownika między wywołaniami. Rolę „pamięci” pełni właśnie Event Engine, który utrzymuje stan profili użytkowników. Architektura integracji wygląda następująco (kolejne kroki w procesie scoringu dla pojedynczego zdarzenia):
Proces — od zapytania do wyniku scoringu
- Request (żądanie) – Aplikacja kliencka wysyła zapytanie decyzjne/scoringowe. Może to być np. wywołanie API Scoring.One w momencie, gdy użytkownik wykonał określoną akcję (np. logowanie, transakcję) wymagającą decyzji w oparciu o model ML.
- Transformacja danych – Dane z żądania są wstępnie przetwarzane i mapowane na wymagany format. Na tym etapie typowo wykonywane są operacje ETL w skali pojedynczego zdarzenia: np. uzupełnienie brakujących pól, zmapowanie nazw atrybutów na schemat oczekiwany przez Event Engine, proste wyliczenia (część z nich może być zdefiniowana w metadanych Event Engine jako transformacje JSON→zmienne).
- Zapis zdarzenia – Uformowane zdarzenie przekazywane jest do Event Engine, który zapisuje je w swoim repozytorium (dzięki temu budowana jest historia zdarzeń do celów trenowania modeli i długoterminowych agregacji). Operacja zapisu jest zazwyczaj asynchroniczna (poprzez kolejkę Kafka) i bardzo szybka, nie blokuje dalszego przetwarzania.
- Aktualizacja profilu cech – Event Engine aktualizuje w pamięci profil cech odpowiadający danemu obiektowi (np. profil użytkownika o danym userID). Wszystkie zdefiniowane agregaty zostają przeliczone na podstawie nowego zdarzenia – np. zwiększa się licznik zdarzeń, przesuwają okna czasowe, odnotowywana jest ostatnia wartość określonego pola itp. Dzięki temu profil natychmiast odzwierciedla skutki nowej aktywności.
- Odczyt profilu – Następnie Scoring.One (bądź inny komponent orkiestrujący) pobiera z Event Engine aktualny wektor cech tego obiektu. Może to nastąpić poprzez wywołanie API Event Engine (np. endpoint /profile?userid=X zwracający wszystkie agregaty danego użytkownika), ewentualnie – w przypadku silnej integracji – poprzez bezpośredni dostęp w pamięci. Uzyskany profil to kompletny zestaw feature’ów, na podstawie których model podejmie decyzję.
- Scoring (obliczenie wyniku) – Scoring.One stosuje załadowany wcześniej model predykcyjny (np. model uczenia maszynowego w postaci reguły skoringowej lub sieci neuronowej) do wektora cech otrzymanego z Event Engine. Wynik modelu (np. prawdopodobieństwo fraudu, rekomendacja produktu, decyzja kredytowa) jest następnie zwracany do systemu wywołującego. Całość przebiega w czasie rzeczywistym – od momentu wystąpienia zdarzenia do uzyskania wyniku mija zwykle kilkanaście milisekund, z czego większość to ewentualne opóźnienia sieciowe między komponentami.
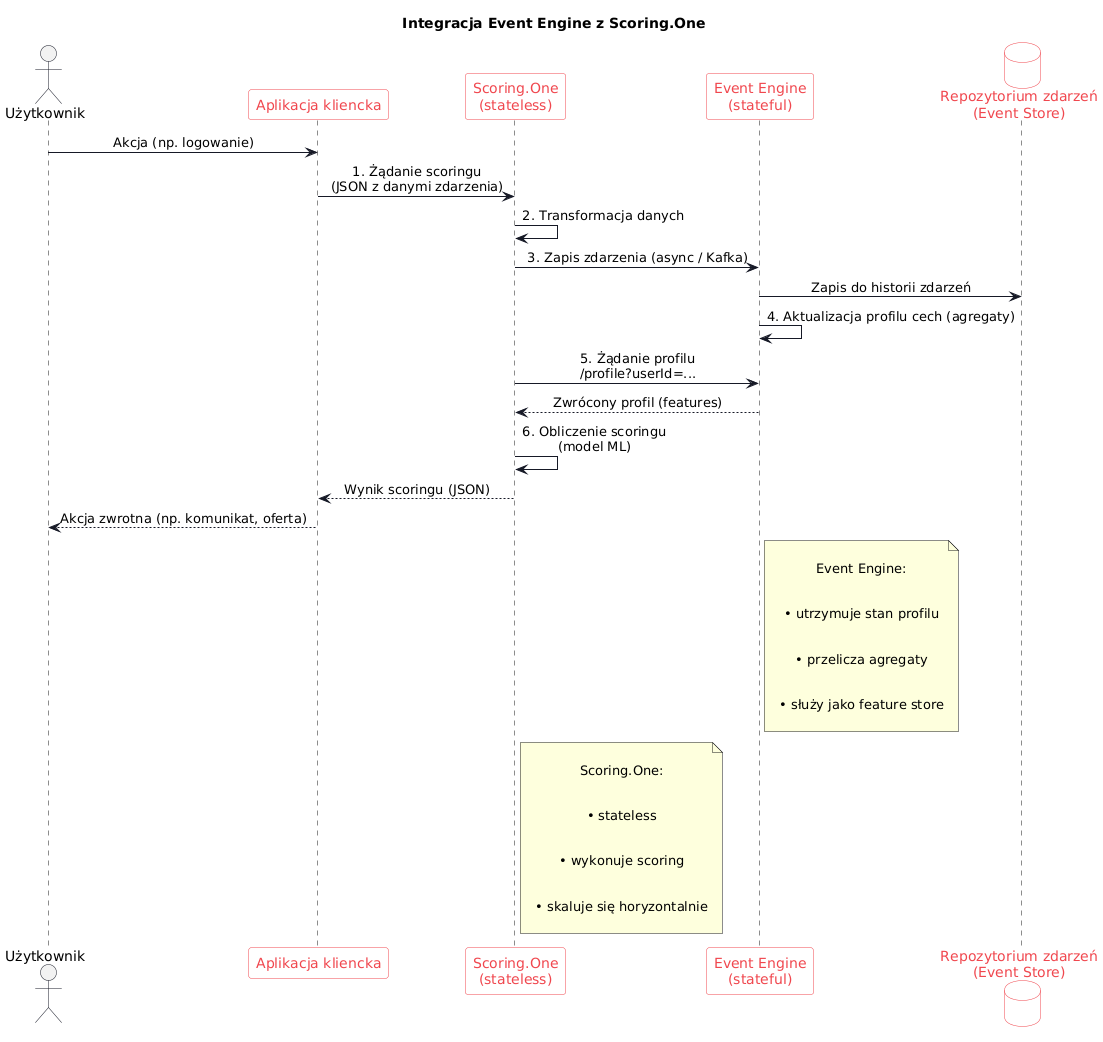
Korzyści architektury i skalowalność
Taka integracja łączy zalety obu modułów: Event Engine dba o stan i cechy historyczne (trudne do utrzymania w rozproszonym środowisku bez spadku wydajności), a Scoring.One zapewnia skalowalną obsługę logiki decyzyjnej i modeli w formie usług.
Skalowanie horyzontalne odbywa się głównie po stronie stateless (Scoring.One), co jest łatwe – można uruchomić wiele instancji silnika scoringowego bez potrzeby replikacji stanu.
Z kolei Event Engine można skalować poprzez partycjonowanie strumienia zdarzeń (np. shardowanie po użytkownikach) lub integrację z infrastrukturą big data, jak wspomniano wcześniej. Co istotne, taka architektura zapobiega niespójnością pomiędzy procesem trenowania a inferencji – cechy są liczone przez ten sam mechanizm zarówno offline (do trenowania modeli), jak i online (do scoringu), więc model zawsze otrzymuje cechy o tej samej definicji. Inżynierowie ds. danych nie muszą ręcznie odtwarzać logiki agregacji w dwóch miejscach, co eliminuje częsty problem niespójności danych (training-serving skew).
Ostatecznie połączenie Event Engine i Scoring.One przekłada się na elastyczność i szybkość budowania systemów ML/AI w środowisku produkcyjnym. Data scientist może zdefiniować nowe cechy i model w interfejsie Event Engine/ABM, a gotowy model automatycznie zacznie korzystać z tych cech w Scoring.One w czasie rzeczywistym. Takie rozwiązanie umożliwia podejmowanie decyzji na podstawie strumienia danych z zachowaniem pełnej automatyzacji i wysokiej wydajności – od surowych zdarzeń, przez feature store, aż po scoring i akcję zwrotną – wszystko w ciągu milisekund.
Porównanie Event Engine z konkurencyjnymi narzędziami
Na rynku dostępne są popularne platformy do przetwarzania strumieniowego, takie jak Apache Flink, Apache Spark Streaming, Apache Storm czy komercyjny SAS Event Stream Processing (ESP). W przeciwieństwie do Algolytics Event Engine, który dostarcza gotowy feature store wraz z automatyzacją treningu modeli i ich wdrażania, narzędzia te są ogólnymi frameworkami. Wymagają samodzielnego zaimplementowania logiki agregacji, zarządzania stanem i integracji z uczeniem maszynowym. Poniżej przedstawiono kluczowe różnice:
Apache Flink
Jest to wydajny silnik strumieniowy o dokładnych gwarancjach stanu, jednak pozostaje platformą programistyczną, a nie gotową aplikacją. Aby zbudować funkcjonalność feature store w Flinku, konieczne jest samodzielne opracowanie logiki agregacji, zarządzania stanem (np. ustawianie TTL dla nieaktualnych profili) oraz integracji pipeline'ów. Flink wspiera checkpointy przyrostowe (z backendem RocksDB), ale w wielu wdrożeniach stosuje się pełne checkpointy statyczne, co wpływa na obciążenie systemu. Flink nie posiada natywnej funkcji automatycznego wygaszania stanu użytkowników po okresie braku aktywności – trzeba to zaimplementować ręcznie. Również skalowanie nie jest trywialne: dodanie nowych węzłów wymaga wykonania savepointów i restartu zadań. Reactive Mode (dostępny od wersji 1.13) umożliwia półautomatyczne skalowanie poprzez restartowanie zadań na nowej liczbie zasobów, jednak pełne skalowanie bez przestojów nie jest jeszcze możliwe.
Apache Spark Streaming
Spark (w trybie Structured Streaming) wykorzystuje tzw. mikropartycje zamiast czysto zdarzeniowego przetwarzania, co wprowadza ograniczenia w obsłudze bardzo niskich opóźnień oraz precyzyjnej analizy ciągłych zdarzeń w czasie. W przypadkach wymagających reakcji w ciągu kilku milisekund podejście mikropartii jest zbyt wolne (Spark oferuje opóźnienia rzędu sekund). Dodatkowo, Spark Streaming – podobnie jak Flink – jest jedynie frameworkiem: deweloper musi od podstaw zaprogramować logikę agregacji (np. okna czasowe, liczniki zdarzeń) oraz zadbać o integrację generowanych cech z procesem trenowania modeli. Event Engine dostarcza te elementy w gotowej formie.
Apache Storm
Storm został zaprojektowany do ultra-niskich opóźnień – przetwarza zdarzenia pojedynczo, dzięki czemu jest jednym z najszybszych rozwiązań do prawdziwego przetwarzania w czasie rzeczywistym (true real-time). Jednak domyślnie Storm jest bezstanowy – nie przechowuje kontekstu między zdarzeniami. Użytkownik musi samodzielnie zaimplementować przechowywanie i odzyskiwanie stanu (np. w zewnętrznej bazie danych lub za pomocą mechanizmów Trident) w celu agregacji historycznych cech. Co więcej, Storm nie oferuje wbudowanego zestawu operatorów agregujących – wszystkie złożone metryki (liczniki, okna czasowe itp.) wymagają implementacji w kodzie. Trident, będący stanową warstwą Storm, wprowadza częściowe mikropartycje, co łagodzi brak stanu, ale nadal nie jest to tak kompletne rozwiązanie jak dedykowany feature store. Natomiast Event Engine automatycznie zarządza stanem użytkowników i dostarcza gotowe funkcje agregujące „od ręki”.
SAS Event Stream Processing
SAS Event Stream Processing to zaawansowana komercyjna platforma do analityki strumieniowej i inferencji ML w czasie rzeczywistym. Nie zapewnia jednak pełnej automatyzacji procesu trenowania i wdrażania modeli predykcyjnych – zbudowanie kompletnego pipeline’u (od pobierania danych, przez agregację, aż po wdrożenie modelu) zwykle wymaga ręcznej konfiguracji i integracji z innymi komponentami ekosystemu SAS Viya. Definicje agregatów są zwykle tworzone w środowisku graficznym (ESP Studio) lub poprzez skrypty XML/DS2. Definiowanie dużej liczby cech (dziesiątki lub setki) może być czasochłonne i utrudnia skalowanie. W przeciwieństwie do tego, Event Engine potrafi automatycznie wygenerować tysiące agregatów na podstawie metadanych zdarzeń, znacznie upraszczając skalowanie i zmniejszając nakład ręcznej pracy.
Event Engine od Algolytics
Algolytics Event Engine wyróżnia się tym, że jest gotowym rozwiązaniem (plug-and-play) do strumieniowego feature store z automatyzacją ML. Zapewnia wbudowane mechanizmy agregacji, zarządzania stanem i integracji z modułem AutoML, podczas gdy konkurencyjne narzędzia wymagają dopracowania tych aspektów przez zespół inżynierów. W razie potrzeby Event Engine może także współpracować z wymienionymi frameworkami big data – np. wpiąć się w ekosystem Apache Kafka/Flink/Storm, aby wykorzystać ich skalowalność horyzontalną, jednocześnie oferując wyższy poziom automatyzacji przetwarzania zdarzeń.
Inne dostępne rozwiązania z kategorii feature store i narzędzi strumieniowych z ML, które można porównać do EventEngine:
Feast
Popularny open-source’owy feature store zaprojektowany przez Gojek i rozwijany przez Tecton.ai. Umożliwia przechowywanie i udostępnianie cech w trybie batch i online (np. przez Redis), jednak nie oferuje automatycznej agregacji strumieni ani pełnej integracji z pipeline'ami modelowania. Konfiguracja cech i synchronizacja między środowiskiem treningowym i produkcyjnym wymaga ręcznego przygotowania danych i kodu.
Hopsworks
Platforma MLOps z własnym feature store, oferująca spójność między offline i online, zarządzanie wersjami cech i integrację ze Spark. Umożliwia trenowanie modeli na historycznych danych, ale podobnie jak Feast, wymaga implementacji logiki agregacji strumieniowej poza systemem (np. w Spark Structured Streaming).
Databricks Feature Store
Część komercyjnej platformy Databricks, oparta o Spark. Umożliwia wersjonowanie cech i ich wykorzystywanie w modelach ML, ale bazuje na batch’owym lub mikropartycjonowanym przetwarzaniu, co ogranicza zastosowania o bardzo niskim opóźnieniu. Nie posiada natywnego wsparcia dla automatycznej agregacji cech w czasie rzeczywistym.
Tecton
Komercyjny feature store z zaawansowanym wsparciem zarówno dla batch, jak i stream. Zapewnia deklaratywne definicje cech, automatyczne harmonogramy aktualizacji i infrastrukturę servingową. Wyróżnia się wysokim poziomem automatyzacji, ale wymaga pełnego wdrożenia infrastruktury chmurowej (np. AWS, Snowflake, DynamoDB, Redis) i programistycznej konfiguracji.
Vertex AI Feature Store (Google Cloud)
Rozwiązanie feature store oferowane przez Google, w pełni zintegrowane z ekosystemem Vertex AI. Obsługuje wersjonowanie i automatyczne serwowanie cech w czasie rzeczywistym, ale działa tylko w środowisku GCP i nie posiada narzędzi do elastycznego definiowania agregacji w czasie rzeczywistym.
Qwak
Komercyjna platforma end-to-end do wdrażania modeli ML, posiadająca własny feature store. Obsługuje batch + real-time, automatyczne pipelines i inferencję online. Bardzo dobrze nadaje się do środowisk produkcyjnych z wymaganiami CI/CD modeli, ale jest platformą zamkniętą i zorientowaną głównie na rynek międzynarodowy.
Nussknacker
Open-source’owy i enterprise-ready silnik decyzyjny z interfejsem low-code do projektowania procesów opartych o dane strumieniowe. Pozwala projektować przepływy z ML i agregacjami w formie wizualnej, bez programowania. Nie posiada jednak własnego feature store ani integracji AutoML – może natomiast zostać połączony z Algolytics Event Engine jako warstwa decyzyjna i orkiestracyjna.
Podsumowując, Event Engine wyróżnia się na tle konkurencji połączeniem wydajnego stream feature store’u, automatycznej agregacji cech, integracji z AutoML i scoringu w czasie rzeczywistym w ramach jednego produktu. Podczas gdy większość innych rozwiązań koncentruje się na przechowywaniu cech i obsłudze pipeline’ów offline/online, Event Engine zapewnia pełną automatyzację – od surowych zdarzeń po działający model scoringowy, bez konieczności samodzielnego budowania architektury do agregacji, synchronizacji i orkiestracji. Dzięki temu może stanowić alternatywę nie tylko dla narzędzi programistycznych klasy Flink/Spark, ale również dla rozwiązań enterprise feature store, wymagających znacznych zasobów do wdrożenia i utrzymania.
| Narzędzie | Gotowe do produkcji | Streaming Feature Store | Automatyzacja agregacji | Integracja z AutoML | Online scoring (ms) | Użytkownik docelowy |
| Algolytics Event Engine | ✔️ Tak | ✔️ Tak | ✔️ Pełna (metadane, okna) | ✔️ ABM | ✔️ < 5 ms | Data Scientist, ML Engineer |
| Apache Flink | ❌brak | – Możliwa (samodzielnie) | ❌brak | ❌brak | ✔️ (z kodem) | Data Engineer, Developer |
| Apache Spark Streaming | ❌brak | – Batch + micro-batch | ❌brak | ❌brak | brak | Data Engineer |
| Apache Storm | ❌brak | – Tak, ale bez stanu | ❌brak | ❌brak | ✔️ (bardzo niskie) | Developer (real-time, IoT) |
| SAS ESP | ✔️ Tak | ✔️ Tak (GUI) | – Ograniczona (ręczna) | ❌brak | ✔️ (średnie opóźnienie) | Analityk, Zespół SAS |
| Feast | ✔️ Tak | ✔️ Tak | ❌brak | ❌brak | ✔️ (z Redis) | Data Engineer (ML Platform) |
| Hopsworks | ✔️ Tak | ✔️ Tak | ❌brak | – Integracja ręczna | ✔️ | ML Engineer, AI Team |
| Databricks Feature Store | ✔️ Tak | – Spark Streaming | ❌brak | ✔️ (MLflow) | – (sekundy) | ML Engineer, DevOps |
| Tecton | ✔️ Tak | ✔️ Tak | ✔️ Tak | ✔️ Tak | ✔️ (Redis, DynamoDB) | ML Platform Engineer |
| Vertex AI FS (GCP) | ✔️ Tak | ✔️ Tak | ❌brak | ✔️ (Vertex AI) | ✔️ | Zespół ML (Google Cloud) |
| Qwak | ✔️ Tak | ✔️ Tak | ✔️ Tak | ✔️ Tak | ✔️ | Zespół ML, MLOps |
| Nussknacker | ✔️ Tak | – Możliwe z integracją | – W UI (ograniczone) | ❌brak | – (poprzez REST) | Analityk Biznesowy, Architekt decyzji |
Event Engine od Algolytics – feature store przetwarzający zdarzenia w czasie rzeczywistym dla nowoczesnych, data-driven firm
Algolytics Event Engine to zaawansowany feature store działający w czasie rzeczywistym, zaprojektowana z myślą o wymagających potrzebach nowoczesnych firm opartych na danych. Łącząc przetwarzanie strumieniowe, profilowanie użytkowników oraz płynną integrację z AutoML, umożliwia w pełni zautomatyzowane, kompleksowe procesy uczenia maszynowego — od pozyskiwania zdarzeń aż po wdrożenie modeli. W przeciwieństwie do ogólnych frameworków, Event Engine zapewnia niskie opóźnienia, wbudowaną logikę agregacji oraz skalowalną architekturę dostosowaną do personalizacji w czasie rzeczywistym, wykrywania oszustw i podejmowania skutecznych decyzji biznesowych.
Materiały:
O produkcie: https://algolytics.com/pl/produkt/event-engine-feature-store/
Dokumentacja produktu: https://algolytics-technologies.gitbook.io/algolytics/event-engine-user



