
















Wiele projektów AI nie wychodzi poza fazę eksperymentu. Główną przyczyną jest brak systematycznego podejścia do zarządzania modelami uczenia maszynowego w środowisku produkcyjnym. MLOps to odpowiedź na ten problem – zestaw praktyk, który zmienia sposób, w jaki organizacje wdrażają i utrzymują rozwiązania oparte na sztucznej inteligencji.
W tym przewodniku poznasz wszystko, co musisz wiedzieć o machine learning operations: od podstawowych definicji, przez architekturę i wdrożenie, aż po konkretne korzyści biznesowe.
Czym jest MLOps (Machine Learning Operations)
MLOps to angielski skrót od Machine Learning Operations. Rozumiany jest jako zbiór praktyk automatyzujących proces tworzenia, wdrażania i utrzymywania modeli machine learning.
MLOps łączy elementy DevOps, Data Engineering oraz Machine Learning w spójny proces, integrując różnorodne narzędzia i usługi, które wspierają zarządzanie cyklem życia modeli ML na każdym jego etapie. Praktyki i narzędzia MLOps dążą do automatyzacji powtarzalnych zadań w całym procesie uczenia maszynowego, jednocześnie kładąc szczególny nacisk na monitorowanie każdej zmiany wprowadzanej w danych, kodzie oraz modelach.
Najprościej rzecz ujmując: MLOps jest dla modeli ML tym, czym DevOps jest dla klasycznego oprogramowania. Podobnie jak DevOps zrewolucjonizował sposób tworzenia i wdrażania aplikacji, tak MLOps automatyzuje i standaryzuje procesy związane z modelami AI. Kluczowa różnica polega jednak na tym, że w MLOps musimy zarządzać nie tylko kodem, ale również danymi i samymi modelami, które zmieniają się w czasie.
Różnice między MLOps a DevOps
MLOps i DevOps mają wiele wspólnych cech, takich jak automatyzacja procesów, kontrola wersji czy ciągła integracja i dostarczanie (CI/CD). Jednak MLOps skupia się na unikalnych wyzwaniach związanych z wdrażaniem i zarządzaniem modelami uczenia maszynowego w środowisku produkcyjnym. Podczas gdy DevOps koncentruje się głównie na kodzie i aplikacjach, MLOps obejmuje dodatkowo zarządzanie danymi, trening modeli ML oraz ich monitorowanie po wdrożeniu.
Ważnym aspektem MLOps jest również odpowiedzialność i etyka sztucznej inteligencji – praktyki te kładą nacisk na to, aby modele ML działały w sposób sprawiedliwy, transparentny i zgodny z regulacjami. MLOps wymaga wdrożenia mechanizmów zapewniających audytowalność decyzji modeli oraz przeciwdziałanie potencjalnym uprzedzeniom.
Dodatkowo, MLOps musi radzić sobie z dynamicznym charakterem danych wejściowych, które mogą się zmieniać w czasie, co wymaga ciągłego treningu modeli i ich aktualizacji. DevOps natomiast skupia się na stabilności i niezawodności oprogramowania, a MLOps musi łączyć te cele z elastycznością niezbędną do adaptacji modeli ML do zmieniających się warunków.
Podsumowując, MLOps to rozszerzenie praktyk DevOps, dostosowane do specyfiki uczenia maszynowego, które integruje zarządzanie kodem, danymi i modelami, aby zapewnić skuteczne, etyczne i skalowalne wdrażanie rozwiązań AI.
Dlaczego MLOps jest potrzebny w nowoczesnych organizacjach
Po 2020 roku liczba projektów wykorzystujących modele ML w firmach wzrosła wykładniczo. Finanse, e-commerce, produkcja, medycyna – praktycznie każda branża szuka sposobów na wykorzystanie sztucznej inteligencji. Problem w tym, że złożoność utrzymania tych rozwiązań przekracza możliwości tradycyjnych metod pracy.
Problem „modelu w notatniku” to klasyczna bolączka zespołów data science. Model działa świetnie na laptopie, ale przeniesienie go do produkcji okazuje się koszmarem. Ręczne procesy, brak wersjonowania, niemożność odtworzenia eksperymentów, zero monitoringu – to codzienność w organizacjach bez MLOps. Każde wdrożenie to loteria, a każda awaria wymaga żmudnego debugowania.
Skalowanie wymaga automatyzacji. Gdy firma obsługuje rosnące wolumeny danych, przetwarza strumienie danych w czasie rzeczywistym lub zarządza setkami modeli równolegle (jak w przypadku personalizacji w e-commerce), ręczne podejście po prostu się nie skaluje. Przykładowo duży sklep internetowy może mieć tysiące modeli personalizacyjnych – każdy dla innego segmentu użytkowników. MLOps pozwala na efektywne skalowanie uczenia maszynowego w miarę zmieniających się potrzeb organizacji, co jest szczególnie ważne przy rosnących wolumenach danych i złożoności modeli.
Konkretne scenariusze, gdzie brak MLOps zabija projekty:
- Wykrywanie fraudów w banku – oszuści stale zmieniają wzorce działania. Model musi być aktualizowany co tydzień lub częściej, z zachowaniem compliance i audytowalności. Bez automatyzacji to niemożliwe.
- System rekomendacji w sklepie internetowym – preferencje użytkowników zmieniają się sezonowo. Model sprzed trzech miesięcy może dawać gorsze wyniki niż losowe rekomendacje.
- Prognozowanie popytu w łańcuchu dostaw – nieprzewidziane zdarzenia (pandemia, kryzysy) wymagają natychmiastowej aktualizacji modeli. Ręczne wdrożenie trwa tygodnie, automatyczne – godziny.
Czy MLOps jest potrzebny zawsze i kiedy warto go wdrożyć
Odpowiedź wprost: MLOps jest kluczowy wszędzie tam, gdzie modele mają działać długoterminowo w produkcji. Przy małych, eksperymentalnych projektach można zaczynać „lżej”, ale warto od początku myśleć o skalowalności.
Scenariusze, gdzie MLOps jest absolutnie konieczny:
- Duże wolumeny danych – gdy przetwarzasz terabajty danych i musisz regularnie przetrenowywać oraz przeprowadzać aktualizację modeli, ręczne podejście prowadzi do chaosu i błędów.
- Krytyczne decyzje biznesowe – finanse, medycyna, bezpieczeństwo. Gdy model decyduje o przyznaniu kredytu lub diagnozuje chorobę, potrzebujesz pełnej kontroli, monitoringu i możliwości szybkiego rollbacku.
- Wiele zespołów i środowisk – gdy nad modelami pracuje kilka zespołów, a każdy model przechodzi przez środowiska dev/test/prod, bez standaryzacji panuje chaos.
- Restrykcje regulacyjne – branże regulowane wymagają audytowalności, śledzenia pochodzenia danych i dokumentacji decyzji modelu.
Gdzie wystarczą podstawowe praktyki:
- Startup testujący pojedynczy model jako MVP
- Projekty badawcze na małą skalę
- Jednorazowe analizy bez planów wdrożenia produkcyjnego
Nawet w tych przypadkach warto jednak stosować podstawy: wersjonowanie kodu w Git, zapisywanie parametrów eksperymentów, dokumentowanie założeń.
Checklista „Czy to już czas na MLOps?”
Kryterium | Sygnał do wdrożenia MLOps |
|---|---|
Liczba modeli w produkcji | Więcej niż 2-3 |
Częstotliwość aktualizacji | Aktualizację modeli przeprowadzasz co tydzień lub częściej |
Wielkość zespołu | Więcej niż 2 osoby pracujące nad ML |
Krytyczność dla biznesu | Model wpływa na przychody lub decyzje kluczowe |
Wymagania compliance | Branża regulowana |
Wolumen danych | Dane strumieniowe lub szybko rosnące |
Zalety MLOps dla zespołów i biznesu
MLOps upraszcza utrzymanie modeli, przyspiesza wdrożenia i zmniejsza ryzyko błędów wpływających na wyniki biznesowe.
Korzyści techniczne:
- Automatyzacja pipeline’ów – od danych wejściowych przez inżynierię cech, trenowanie, po wdrożenie. Jeden commit uruchamia cały proces.
- Powtarzalność eksperymentów – każdy eksperyment można odtworzyć z identycznymi wynikami. Koniec z „u mnie działało”.
- Kontrola wersji danych, modeli i kodu – pełna historia zmian, możliwość porównania dowolnych wersji.
- Łatwe rollbacki – gdy nowy model zawodzi, powrót do poprzedniej wersji to kwestia minut, nie dni.
- Continuous integration i continuous delivery dla modeli ML – automatyczne testy, walidacja, wdrożenie.
- Automatyzacja powtarzalnych zadań – MLOps automatyzuje rutynowe procesy, co pozwala data scientists skupić się na bardziej strategicznych działaniach i rozwijaniu modeli.
- Tworzenie pętli sprzężenia zwrotnego – umożliwia ciągłe monitorowanie modeli i szybkie reagowanie na spadek ich wydajności, co zapewnia stałą poprawę jakości.
Korzyści biznesowe:
- Szybsze reagowanie na zmiany rynku – gdy zachowania klientów zmieniają się (np. w czasie kryzysu), nowy model można wdrożyć w ciągu godzin.
- Dokładniejsze prognozy i predykcje – regularne retraining na świeżych danych poprawia skuteczność modeli.
- Lepsze wykorzystanie danych – zarówno historycznych, jak i strumieniowych, dzięki standaryzowanym pipeline’om.
- Redukcja kosztów operacyjnych – mniej ręcznej pracy, mniej incydentów produkcyjnych, mniej przestojów, a także eliminacja błędów ludzkich.
- Szybszy time-to-market – od pomysłu do działającego modelu w produkcji w dniach, nie miesiącach.
- Łatwiejsze spełnianie wymogów regulacyjnych – pełna audytowalność decyzji modelu, zgodność z RODO i wytycznymi EU AI Act.
- Lepsze wykorzystanie zasobów – automatyzacja powtarzalnych zadań pozwala data scientists skupić się na bardziej strategicznych działaniach.
Korzyści organizacyjne:
- Lepsza współpraca między data scientists, inżynierami danych i zespołami operacyjnymi – wspólne narzędzia i procesy prowadzą do lepszej komunikacji i usprawnionych przepływów pracy.
- Jasny podział odpowiedzialności – kto odpowiada za dane, kto za model, kto za infrastrukturę.
- Ograniczenie „bus factor” – wiedza jest w systemach, nie tylko w głowach pojedynczych osób.
Zastosowania MLOps w czasie rzeczywistym
MLOps odgrywa kluczową rolę w umożliwianiu organizacjom wdrażania i utrzymania modeli machine learning działających w czasie rzeczywistym, co przekłada się na znaczące usprawnienia procesów biznesowych i operacyjnych. Dzięki automatyzacji, ciągłemu monitorowaniu oraz szybkiemu reagowaniu na zmiany danych, MLOps pozwala na efektywne zarządzanie modelami w dynamicznych środowiskach.
Przykładowo, instytucje finansowe mogą wykorzystać MLOps do usprawnienia procesów onboardingu klientów poprzez automatyzację weryfikacji danych oraz wykrywanie oszustw w czasie rzeczywistym. Takie rozwiązania pozwalają na szybsze i bezpieczniejsze przyjmowanie nowych użytkowników, a także minimalizują ryzyko nieautoryzowanego dostępu i nadużyć.
W sektorze handlu detalicznego MLOps umożliwia optymalizację zarządzania łańcuchem dostaw poprzez przewidywanie popytu na produkty oraz efektywne alokowanie zasobów magazynowych. Modele działające w czasie rzeczywistym pozwalają dostosowywać strategie logistyczne do bieżących warunków rynkowych, co przekłada się na redukcję kosztów i zwiększenie satysfakcji klientów.
W opiece zdrowotnej MLOps wspiera analizę danych pacjentów, identyfikując osoby zagrożone wystąpieniem niekorzystnych zdarzeń zdrowotnych. Dzięki temu możliwe jest wdrażanie działań zapobiegawczych i poprawa wyników leczenia, a modele są stale aktualizowane na podstawie najnowszych danych, co jest kluczowym aspektem zapewnienia wysokiej jakości opieki.
Firmy logistyczne mogą korzystać z MLOps w celu optymalizacji tras dostaw i zarządzania zapasami, wykorzystując modele predykcyjne działające w czasie rzeczywistym. Takie podejście pozwala na szybką adaptację do zmieniających się warunków oraz efektywne planowanie, co wpływa na skrócenie czasu dostawy i obniżenie kosztów operacyjnych.
Podsumowując, MLOps umożliwia organizacjom z różnych branż usprawnienie przepływów pracy związanych z machine learning, poprawę efektywności operacyjnej oraz dostarczanie realnej wartości biznesowej dzięki zastosowaniu modeli działających w czasie rzeczywistym.
Z czego składa się MLOps – kluczowe komponenty, etapy i technologia
MLOps obejmuje zarówno procesy organizacyjne, jak i technologie, które wspólnie umożliwiają efektywne tworzenie, wdrażanie oraz utrzymanie modeli machine learning w środowisku produkcyjnym.
Kluczowe etapy cyklu życia ML w kontekście MLOps:
- Gromadzenie i przygotowanie danych – zbieranie surowych danych z różnych źródeł, ich walidacja, transformacja oraz inżynieria cech (feature engineering). Proces ten może obejmować generowanie danych syntetycznych, które wzbogacają zbiory treningowe i pozwalają na lepsze przygotowanie danych wejściowych do trenowania modeli ML.
- Eksperymenty i trening modeli – testowanie różnych algorytmów uczenia maszynowego, tuning hiperparametrów oraz porównywanie wyników. W ramach MLOps systematycznie rejestruje się wszystkie parametry i metryki, co zapewnia powtarzalność eksperymentów i możliwość odtworzenia dowolnego eksperymentu.
- Walidacja i testy – ocena wydajności modelu na danych testowych, weryfikacja pod kątem biasu, interpretowalności i spełniania wymagań jakościowych. Automatyczne testy gwarantują, że model spełnia wymagania biznesowe i techniczne przed wdrożeniem.
- Wdrożenie modeli – automatyczne, kontrolowane i powtarzalne przeniesienie modeli do środowiska produkcyjnego. Modele mogą być serwowane przez REST API, batch processing lub wdrażane na urządzeniach edge. Zamiast ręcznych interwencji stosuje się pipeline’y automatyzujące testy, walidację i deployment.
- Monitoring – ciągłe śledzenie wydajności modeli w produkcji, wykrywanie dryfu danych i modelu, a także alertowanie o anomaliach. Monitoring w czasie rzeczywistym pozwala na szybkie reagowanie na spadek skuteczności i potencjalne problemy.
- Ponowny trening (Continuous Training) – automatyczne lub półautomatyczne uruchamianie treningu na nowych danych, gdy wydajność modelu spada lub dane się zmieniają. Dzięki temu modele ML są stale aktualizowane i dostosowywane do zmieniającego się środowiska.
Typowe komponenty techniczne MLOps:
- Repozytoria kodu, danych i modeli – systemy kontroli wersji, które umożliwiają pełną audytowalność, powtarzalność eksperymentów oraz efektywne zarządzanie metadanymi. Dzięki nim możliwe jest śledzenie zmian w kodzie, danych i modelach, co jest kluczowe dla utrzymania jakości i przejrzystości procesów.
- Rejestr modeli – centralne miejsce przechowywania wytrenowanych modeli wraz z ich wersjami i metadanymi. Pozwala to na sprawne zarządzanie cyklem życia modeli, szybkie wdrażanie oraz możliwość łatwego cofania zmian w przypadku nieoczekiwanych problemów.
- Orkiestracja pipeline’ów ML – automatyzacja przepływu pracy od przygotowania danych, przez inżynierię cech, trening modeli, aż po ich wdrożenie i monitorowanie. Pipeline’y CI/CD/CT zapewniają ciągłą integrację, dostarczanie i trening modeli w odpowiedzi na zmiany w kodzie, danych lub modelach, co znacząco przyspiesza i ułatwia zarządzanie procesem.
- Platformy do zarządzania eksperymentami – narzędzia umożliwiające rejestrowanie i porównywanie parametrów, metryk oraz artefaktów eksperymentów. Dzięki temu zespoły mogą wybierać najlepsze modele i optymalizować ich wydajność, zachowując pełną kontrolę nad procesem uczenia.
- Monitoring modeli w czasie rzeczywistym – systemy zbierające metryki predykcji, wykrywające anomalie oraz generujące alerty o potencjalnych problemach z wydajnością modeli. To pozwala na szybkie reagowanie na degradację efektywności oraz inicjowanie ponownego treningu, co jest kluczowe dla utrzymania wysokiej jakości rozwiązań.
- Feature Store – centralne repozytorium cech, które zapewnia spójność danych wejściowych podczas treningu i serwowania modeli. Umożliwia współdzielenie cech między zespołami oraz poprawę jakości i powtarzalności modeli ML.
- Mechanizmy zarządzania ryzykiem i zgodnością – narzędzia śledzące pochodzenie danych (data lineage), logujące decyzje modeli oraz dokumentujące procesy treningu i wdrożeń. Są one niezbędne do spełnienia wymagań regulacyjnych, zapewnienia transparentności oraz audytowalności całego procesu.
Dzięki integracji tych komponentów platforma MLOps umożliwia bezpieczne i efektywne zarządzanie modelami AI w środowisku produkcyjnym, minimalizując błędy ludzkie oraz zwiększając skalowalność i wydajność procesów uczenia maszynowego.
Bolączki klasycznego MLOps
Tradycyjne podejście do MLOps często wiąże się z wieloma wyzwaniami i problemami, które znacząco utrudniają sprawne wdrażanie i utrzymanie modeli machine learning w środowisku produkcyjnym. Jednym z głównych problemów jest konieczność korzystania z wielu rozproszonych narzędzi i technologii, które tworzą swoisty patchwork, wymagający dużej wiedzy i zaangażowania zespołu.
W klasycznych środowiskach MLOps często stosuje się różne narzędzia do poszczególnych etapów procesu: do kontroli wersji kodu i danych używa się Git i DVC, do trenowania modeli popularne są frameworki takie jak TensorFlow czy PyTorch, do orkiestracji pipeline’ów wykorzystuje się Apache Airflow lub Kubeflow, a do wdrażania modeli często stosuje się kontenery Docker i platformy Kubernetes. Każdy z tych elementów wymaga osobnej konfiguracji, integracji i utrzymania, co generuje znaczne koszty i ryzyko błędów.
Dodatkowo, architektura oparta na mikroserwisach, choć elastyczna, może prowadzić do problemów z komunikacją między komponentami, zwiększając złożoność systemu i utrudniając monitorowanie oraz debugowanie. Ręczne zarządzanie wdrożeniami modeli, konieczność implementacji własnych mechanizmów automatyzacji CI/CD, a także brak spójnego nadzoru nad całym cyklem życia modeli powodują, że proces jest czasochłonny, podatny na błędy i wymaga zaangażowania wielu specjalistów z różnych dziedzin.
W efekcie zespoły data science często tracą cenny czas na konfigurację i utrzymanie infrastruktury zamiast skupiać się na tworzeniu i optymalizacji modeli. Brak centralizacji i standaryzacji procesów utrudnia skalowanie rozwiązań oraz szybkie reagowanie na zmiany w danych czy wymaganiach biznesowych. Monitoring modeli i szybkie wykrywanie problemów z ich wydajnością staje się wyzwaniem, co może prowadzić do spadku jakości usług i niezadowolenia użytkowników.
Takie bolączki klasycznego MLOps pokazują, jak ważne jest poszukiwanie nowoczesnych, zintegrowanych rozwiązań, które pozwalają uprościć i zautomatyzować cały proces zarządzania modelami ML, minimalizując potrzebę ręcznych interwencji i eliminując fragmentację narzędziową.
Scoring.One – nowoczesna platforma MLOps od Algolytics
Czym jest Scoring.One?
Scoring.One to low-code’owa platforma MLOps, która umożliwia szybkie uruchamianie modeli ML w produkcji bez konieczności korzystania z kontenerów, mikroserwisów czy ręcznego DevOps. W jednym środowisku pozwala zbudować kompletny proces decyzyjny – od pobrania i przygotowania danych, przez uruchamianie modeli, po reguły biznesowe i integracje API – i wystawić go jako gotową usługę.
Dzięki reaktywnej architekturze JVM opartej na Vert.x platforma osiąga bardzo niskie opóźnienia i wysoką przepustowość, obsługując setki równoległych zapytań i tysiące scoringów na sekundę. Lekka architektura i wysoki poziom automatyzacji skracają wdrożenia, obniżają całkowity koszt posiadania (TCO) i ograniczają zapotrzebowanie na zasoby IT oraz Data Science.
Do kogo skierowany jest Scoring.One?
Platforma jest dedykowana dla:
- CDO, Head of Data, Head of Analytics, którzy odpowiadają za strategię danych i AI oraz czas-to-value i TCO platformy ML.
- CTO, VP Engineering, IT Directors szukających łatwiejszej operacjonalizacji i skalowania bez rozbudowy mikroserwisów i silnej warstwy DevOps.
- MLOps i Platform Engineers potrzebujących reaktywnej, wysokowydajnej orkiestracji scenariuszy decyzyjnych, monitoringu, wersjonowania i rolloutów bez przestojów.
- Data Scientists i ML Engineers pragnących „one-click deployment” modeli (Python, R, Java, PMML) oraz uruchamiania wielu modeli równolegle w jednym żądaniu.
- Zespoły ryzyka, fraud, underwriting, marketingu/personalizacji oraz operacji/logistyki, które korzystają z automatycznych decyzji opartych na danych, aby szybciej i spójniej oceniać klientów, transakcje, zgłoszenia, zamówienia i zdarzenia operacyjne.
Scoring.One wykorzystują firmy obsługujące duże wolumeny zdarzeń i decyzji w czasie rzeczywistym, wymagające niskich opóźnień i często zmagające się z ograniczeniami kompetencyjnymi oraz kosztowymi przy budowie środowisk ML.
Jakie problemy rozwiązuje Scoring.One?
Wolne i kosztowne wdrażanie modeli ML
Tradycyjne środowiska oparte na Pythonie, kontenerach i mikroserwisach wymagają wielu ról technicznych, ręcznej integracji i rozbudowanej infrastruktury, co znacznie zwiększa czas i koszty wdrożenia.
Scoring.One automatycznie generuje usługę produkcyjną – modele wdrażasz jednym kliknięciem, a cały proces decyzyjny (dane, transformacje, modele, reguły i integracje) budujesz w low-code, bez mikroserwisów i kontenerów, co skraca wdrożenia nawet pięciokrotnie i radykalnie obniża TCO.
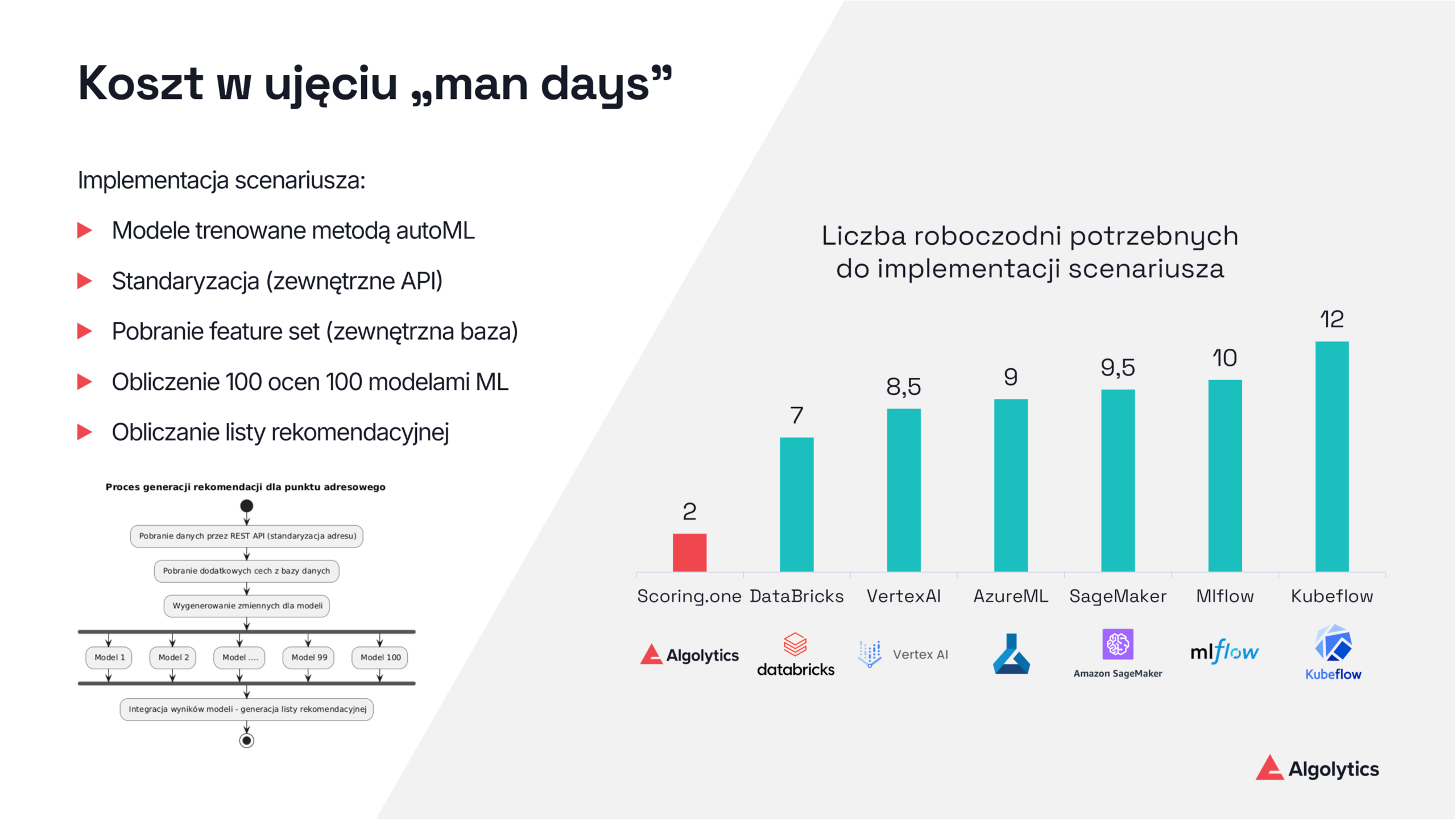
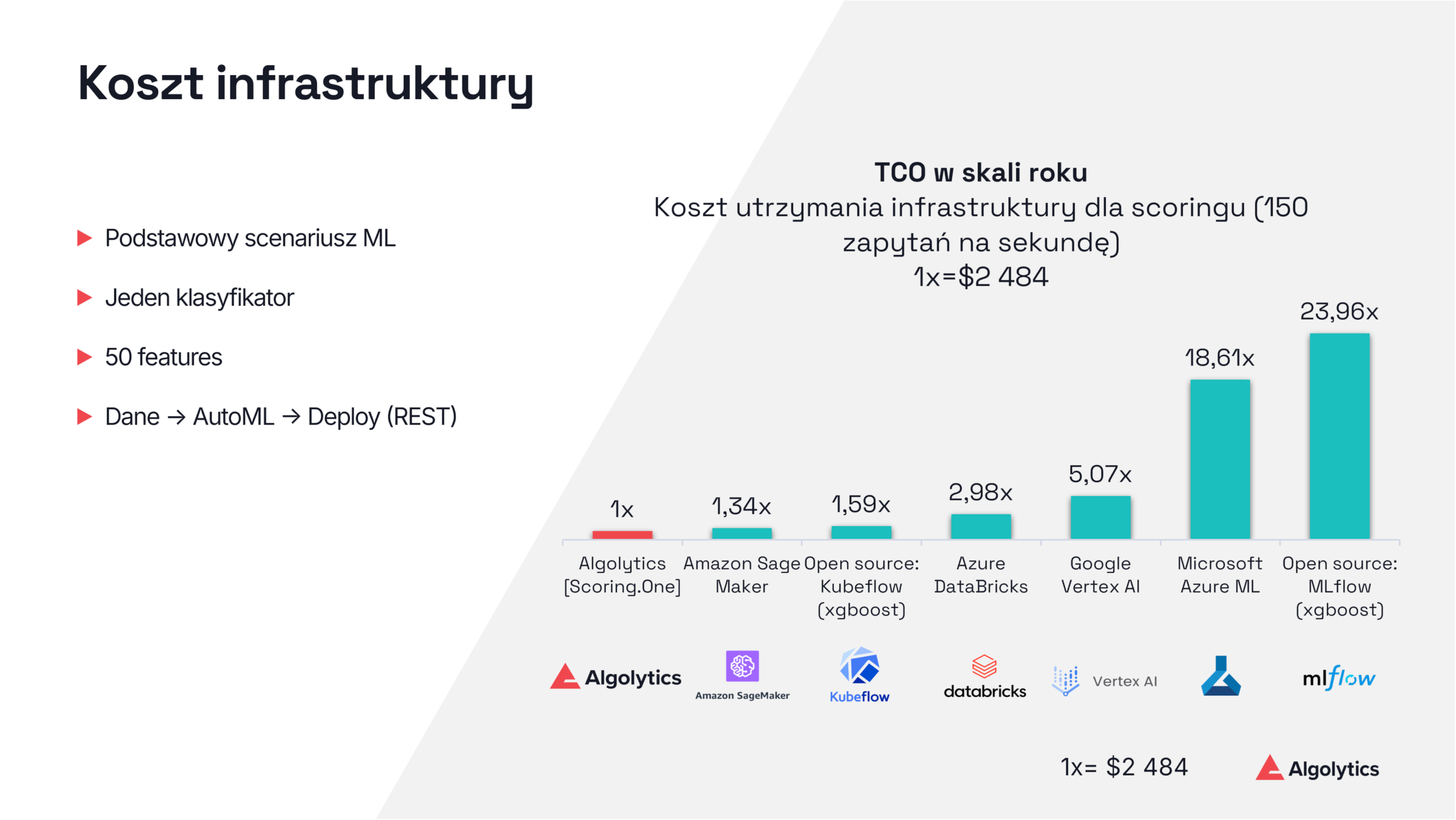
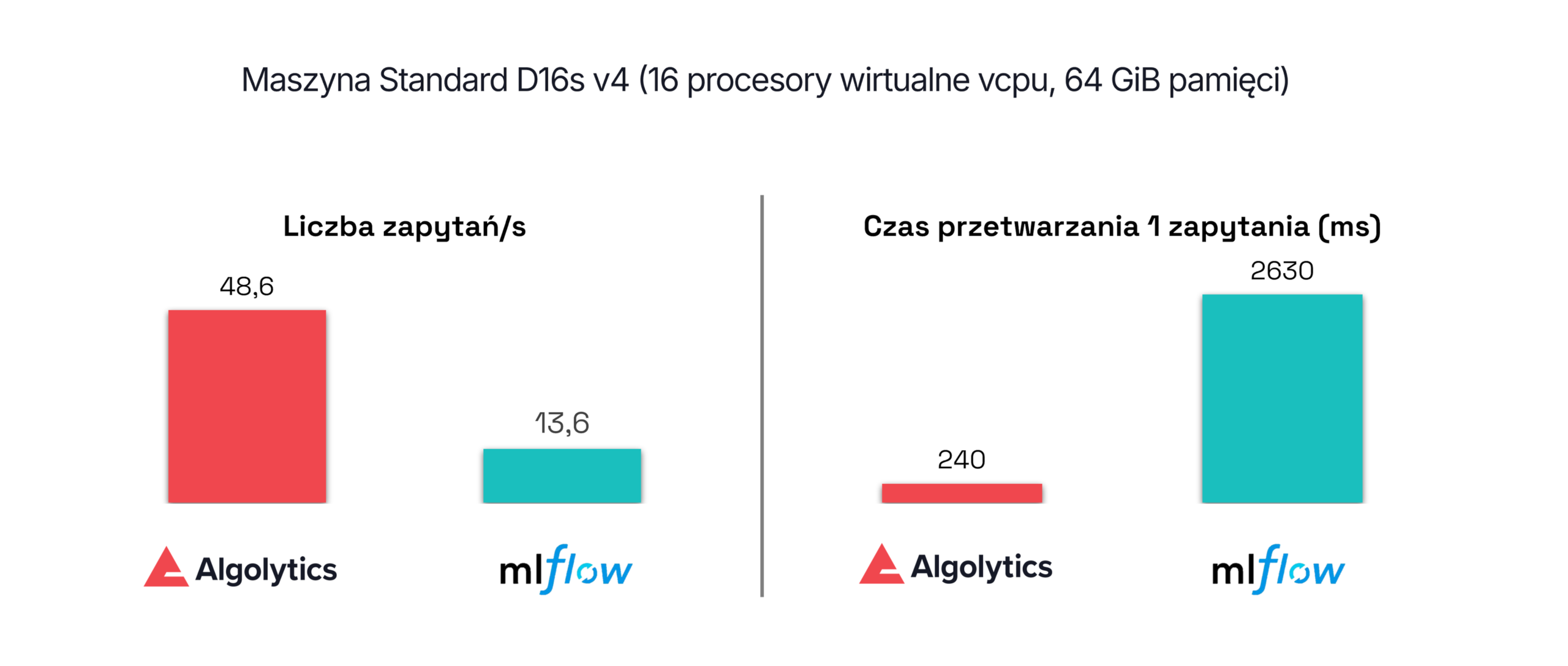
Niska wydajność i wysokie opóźnienia klasycznych stacków ML
Środowiska Pythonowe mają ograniczenia wynikające z GIL, duplikacji bibliotek i komunikacji między usługami, co powoduje niską przepustowość i rosnące opóźnienia.
Scoring.One eliminuje te problemy dzięki reaktywnemu silnikowi JVM opartemu na Vert.x, działającemu asynchronicznie i nieblokująco, obsługującemu setki równoległych zapytań i tysiące scoringów na sekundę bez mnożenia kontenerów. Platforma obsługuje ponad 3,5-krotnie więcej zapytań na sekundę i przetwarza każde z nich ponad dziesięciokrotnie szybciej niż MLflow.
Złożoność integracji danych, modeli i logiki decyzyjnej
Scoring.One oferuje wizualny edytor scenariuszy z gotowymi komponentami do pobierania i przygotowania danych, uruchamiania modeli, stosowania reguł biznesowych, wykonywania operacji równoległych oraz integracji z systemami zewnętrznymi. Cały proces powstaje jako jedna spójna aplikacja, eliminując potrzebę tworzenia wielu mikroserwisów.
Potrzeba dużych zespołów do wdrożenia ML
Platforma automatyzuje elementy wymagające specjalistycznej wiedzy. Deployment modeli, orkiestracja danych, integracje i logika biznesowa powstają w low-code, dzięki czemu jeden Data Scientist może stworzyć i uruchomić kompletny proces ML bez wsparcia wielu innych specjalistów.
Trudności w utrzymaniu i aktualizacji modeli
Scoring.One dostarcza wersjonowanie scenariuszy i modeli, testowanie i debugowanie w UI, wdrażanie zmian bez przestojów, monitoring i logi krok-po-kroku oraz pełną obserwowalność całego procesu, co ułatwia utrzymanie i szybkie aktualizacje.
Konflikty i niestabilność w środowiskach Python
Dzięki izolowanym Python executors i możliwości mieszania technologii (Python, R, Java, PMML) w jednym scenariuszu, platforma eliminuje konflikty bibliotek i problemy ze zgodnością środowisk.
Kluczowe korzyści Scoring.One
- Szybsze wdrażanie modeli i zmian w procesach – wdrażanie w godzinach, nie tygodniach, bez angażowania dużych zespołów IT.
- Stabilne i spójne procesy decyzyjne – eliminacja błędów wynikających z rozproszonej architektury i mikroserwisów.
- Szybkie tworzenie złożonych procesów decyzyjnych – dzięki wizualnemu edytorowi i gotowym komponentom.
- Łatwa integracja z różnymi źródłami danych – predefiniowane konektory do baz, kolejek, API i Feature Store.
- Większa samodzielność zespołów biznesowych i Data Science – wizualny edytor i automatyzacja deploymentu.
- Niższe koszty utrzymania i rozwoju – eliminacja potrzeby rozbudowanej infrastruktury i customowych komponentów.
- Przewidywalne i stabilne wdrożenia – izolowane środowiska wykonawcze eliminujące konflikty.
- Wysoka wydajność i niskie opóźnienia – lekki runtime JVM + Vert.x, zoptymalizowany kod scoringowy.
- Pełna przejrzystość i kontrola – monitoring KPI, testy „what-if”, porównania champion–challenger.
- Real-time scoring i przetwarzanie zdarzeń – integracja z message queue i natywny Feature Store.
- Obsługa wielu technologii ML w jednym scenariuszu – równoległe uruchamianie modeli Python, R, Java, PMML.
- Gotowość do pracy w różnych branżach – bankowość, fintech, ubezpieczenia, e-commerce, logistyka, telekomunikacja.
- Jedna platforma all-in-one – budowa i utrzymanie kompletnego procesu ML w jednym środowisku.
- Automatyzacja pełnego cyklu życia modeli – wersjonowanie, rollout, rollback, testy, monitoring driftu.
Przykłady zastosowań biznesowych
- Bankowość i Fintech: scoring kredytowy online, wykrywanie fraudów, zarządzanie limitami.
- Ubezpieczenia: ocena ryzyka, wykrywanie fraudów, automatyzacja underwriting.
- E-commerce i Marketplaces: personalizacja, rekomendacje, ocena ryzyka transakcji.
- Logistyka i Mobilność: scoring zamówień, planowanie tras, wykrywanie ryzyk operacyjnych.
- Telekomunikacja: personalizacja ofert, wykrywanie fraudów, scoring antyfraudowy.
Wdrożenie Scoring.One
Platforma może być wdrażana on-premise lub w chmurze, dostosowując się do wymagań organizacji i polityk dotyczących danych.
Podsumowanie kluczowych aspektów i korzyści MLOps w zarządzaniu modelami uczenia maszynowego
MLOps (Machine Learning Operations) to zestaw praktyk i narzędzi, które automatyzują proces tworzenia, wdrażania oraz utrzymania modeli uczenia maszynowego w środowisku produkcyjnym. Jego celem jest zapewnienie efektywności, powtarzalności i wysokiej jakości działania modeli ML, a także ułatwienie współpracy między zespołami data science, inżynierii i operacji.
MLOps jest niezbędny tam, gdzie modele ML mają działać długoterminowo, w warunkach dynamicznie zmieniających się danych i wymagań biznesowych. Umożliwia skalowanie procesów, szybkie reagowanie na zmiany, a także spełnianie wymagań regulacyjnych i zapewnienie bezpieczeństwa.
Klasyczne podejście do MLOps wiąże się z wieloma wyzwaniami, takimi jak fragmentacja narzędzi, ręczne zarządzanie wdrożeniami, złożoność integracji danych i modeli, a także trudności w monitorowaniu i utrzymaniu stabilności systemu. Te bolączki powodują opóźnienia, zwiększone koszty i ryzyko błędów.
Nasza platforma Scoring.One rozwiązuje te problemy dzięki niskokodowej architekturze, pełnej automatyzacji procesów, centralizacji zarządzania modelami i danymi oraz wysokiej wydajności działania. Umożliwia szybkie, tanie i stabilne wdrożenia modeli machine learning, eliminując typowe trudności klasycznych rozwiązań i przekładając je na realne korzyści biznesowe.



