
















Wraz z rosnącą popularnością uczenia maszynowego przedsiębiorstwa coraz częściej dostrzegają, że największą barierą nie jest tworzenie i trenowanie modeli, ale ich realne wdrażanie i utrzymanie w środowiskach produkcyjnych.
W wielu firmach projekty AI zaczynają się z dużym entuzjazmem: zespół znajduje sensowny pomysł na zastosowanie technologii, buduje model o wysokiej jakości i pokazuje, że takie rozwiązanie może realnie wesprzeć biznes.
Gdy jednak przychodzi moment przejścia od prototypu do produkcji, zespół zderza się z wielowarstwową architekturą IT, rozproszonymi źródłami danych i trudnościami integracyjnymi - na tym etapie wiele inicjatyw zaczyna się załamywać.
Co więcej, nawet jeśli zespołowi uda się doprowadzić projekt do wdrożenia, sama obsługa i utrzymanie rozwiązania okazują się równie problematyczne. Zmiana jednej funkcji, korekta parametru modelu czy dodanie kolejnego elementu pipeline’u wymagają ponownego przejścia przez cały cykl wdrożeniowy. W praktyce oznacza to, że nawet drobna modyfikacja może stać się kosztownym, wieloetapowym procesem, który spowalnia rozwój.
W tym artykule dowiesz się, jak uprościć i przyspieszyć wdrażanie modeli ML.
Rzeczywiste potrzeby i ograniczenia organizacji
Z badania “Dojrzałość polskich firm w obszarze danych i AI” przeprowadzonego przez Algolytics we współpracy z agencją SW Research wynika, że jedynie niewielka część firm realnie wykorzystuje uczenie maszynowe produkcyjnie. Nie jest to wynikiem braku motywacji - większość organizacji widzi potencjał AI. Problem tkwi w barierach kompetencyjnych i niedostatecznych budżetach.
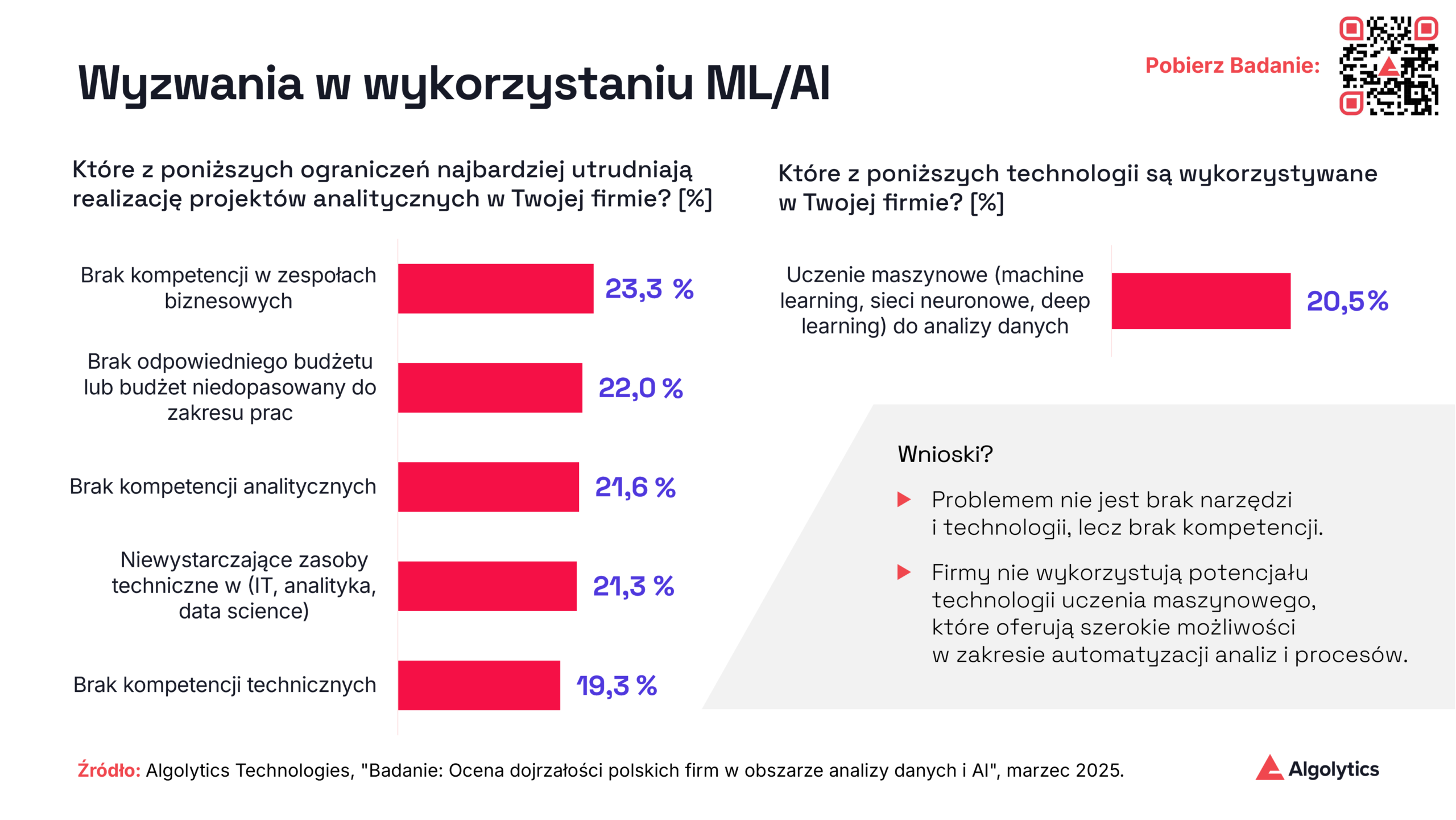
Sytuację dodatkowo komplikuje to, że w tradycyjnym podejściu do wdrażania modeli ML udział bierze wiele ról: od data scientistów, przez inżynierów danych, po specjalistów DevOps i architektów systemowych. Każda z tych grup odpowiada za inny etap prac i wymaga specjalistycznych kompetencji, przez co konieczne staje się budowanie dużych, wielodyscyplinarnych zespołów.
Do wyzwań organizacyjnych dochodzą także istotne bariery techniczne, które w praktyce sprawiają, że wdrożenia ML są trudniejsze i bardziej czasochłonne, niż mogą zakładać zespoły na etapie prototypowania:
- Duże rozmiary danych treningowych - przetwarzanie ogromnych zbiorów danych wymaga dużej mocy obliczeniowej i ogranicza tempo eksperymentowania.
- Złożone integracje ze źródłami danych - łączenie wielu, często heterogenicznych i rozproszonych systemów jest czasochłonne, kosztowne i podatne na błędy.
- Niska jakość danych i brak skutecznych mechanizmów walidacji - błędne lub niekompletne dane obniżają skuteczność modeli i zwiększają ryzyko błędnych decyzji biznesowych.
- Zbyt długi czas odpowiedzi systemu lub długie przetwarzanie batchowe - wysokie opóźnienia utrudniają wykorzystanie modeli w czasie rzeczywistym, szczególnie w procesach wymagających natychmiastowych decyzji.
- Duża pracochłonność implementacji zmian - każda modyfikacja modelu, funkcji czy pipeline’u wymaga szerokiej koordynacji i ponownego przejścia przez etap wdrożeniowy, co spowalnia iteracje.
- Utrudniona ewaluacja i monitoring - brak centralnych narzędzi do monitorowania jakości modeli powoduje, że wykrywanie degradacji modeli jest opóźnione i często manualne.
Na to wszystko nakładają się dodatkowo ograniczenia technologiczne środowisk obliczeniowych. Najpopularniejsze środowisko w ekosystemie ML - Python - mimo swojej elastyczności posiada fundamentalne bariery skalowalności. Global Interpreter Lock* uniemożliwia prawdziwe równoległe przetwarzanie w jednym procesie, a skalowanie wymaga powielania całego środowiska, co generuje większe zużycie pamięci i zwiększa opóźnienia. W efekcie organizacje często muszą utrzymywać wiele instancji aplikacji tylko po to, by ominąć te techniczne ograniczenia.
* Global Interpreter Lock (GIL) to muteks w CPythonie (standardowym interpreterze Pythona), który zapewnia, że w danym momencie tylko jeden wątek wykonuje bajtkod Pythona - nawet na procesorach wielordzeniowych - aby chronić mechanizmy zarządzania pamięcią. Choć upraszcza to zarządzanie pamięcią i poprawia wydajność w trybie jednowątkowym, tworzy wąskie gardło dla zadań obciążających CPU wykonywanych wielowątkowo, uniemożliwiając rzeczywiste, równoległe wykonywanie kodu Pythona.
Od złożonego zestawu narzędzi do jednolitego środowiska wykonawczego
Klucz do przełamania tych barier leży nie w dokładaniu kolejnych usług czy mechanizmów, lecz w uproszczeniu. Największy wzrost efektywności można osiągnąć, tworząc środowisko, które wykonuje pełny proces scoringowy wewnątrz jednej, spójnej aplikacji. Zamiast budować dziesiątki mikroserwisów, warto postawić na monolityczny silnik wykonawczy wyposażony w lekkie, modularne procesory obsługujące poszczególne kroki: pobieranie danych, transformacje, uruchamianie modeli, obliczenia reguł i logikę decyzyjną.
Zastosowanie architektury opartej na asynchronicznym przetwarzaniu zdarzeń umożliwia obsługę wielu instancji pipeline’u jednocześnie, bez wzajemnego blokowania się zadań. Dane trafiają do silnika i przepływają przez kolejne procesory jak przez strumień zdarzeń, a każdy element reaguje w momencie, gdy jest potrzebny. Dzięki temu system może równolegle pobierać dane z baz i API, wykonywać transformacje, uruchamiać modele i agregować wyniki, w pełni wykorzystując zasoby infrastruktury.
Takie podejście otwiera drogę do wdrażania nawet bardzo złożonych aplikacji analitycznych - od prostych modeli klasyfikacyjnych, przez rekomendatory wykorzystujące setki równolegle działających modeli, po inteligentne agentowe rozwiązania łączące modele językowe, scraping danych z internetu oraz analizę ofert w czasie zbliżonym do rzeczywistego.
Wydajność, która robi różnicę
Jednym z kluczowych czynników determinujących koszty i skalowalność systemów ML jest czas obliczeń. W architekturze opartej na lekkich, kompilowanych implementacjach modeli zamiast klasycznych bibliotek Python możliwe jest uzyskanie znaczących oszczędności zasobów. Kiedy model jest reprezentowany jako kod bezpośrednio wykonywalny, np. w Javie, eliminowane są kosztowne operacje interpretacji i konieczność wczytywania zestawów zależności. Taki model wykonuje szybkie operacje arytmetyczne bez zbędnego narzutu.
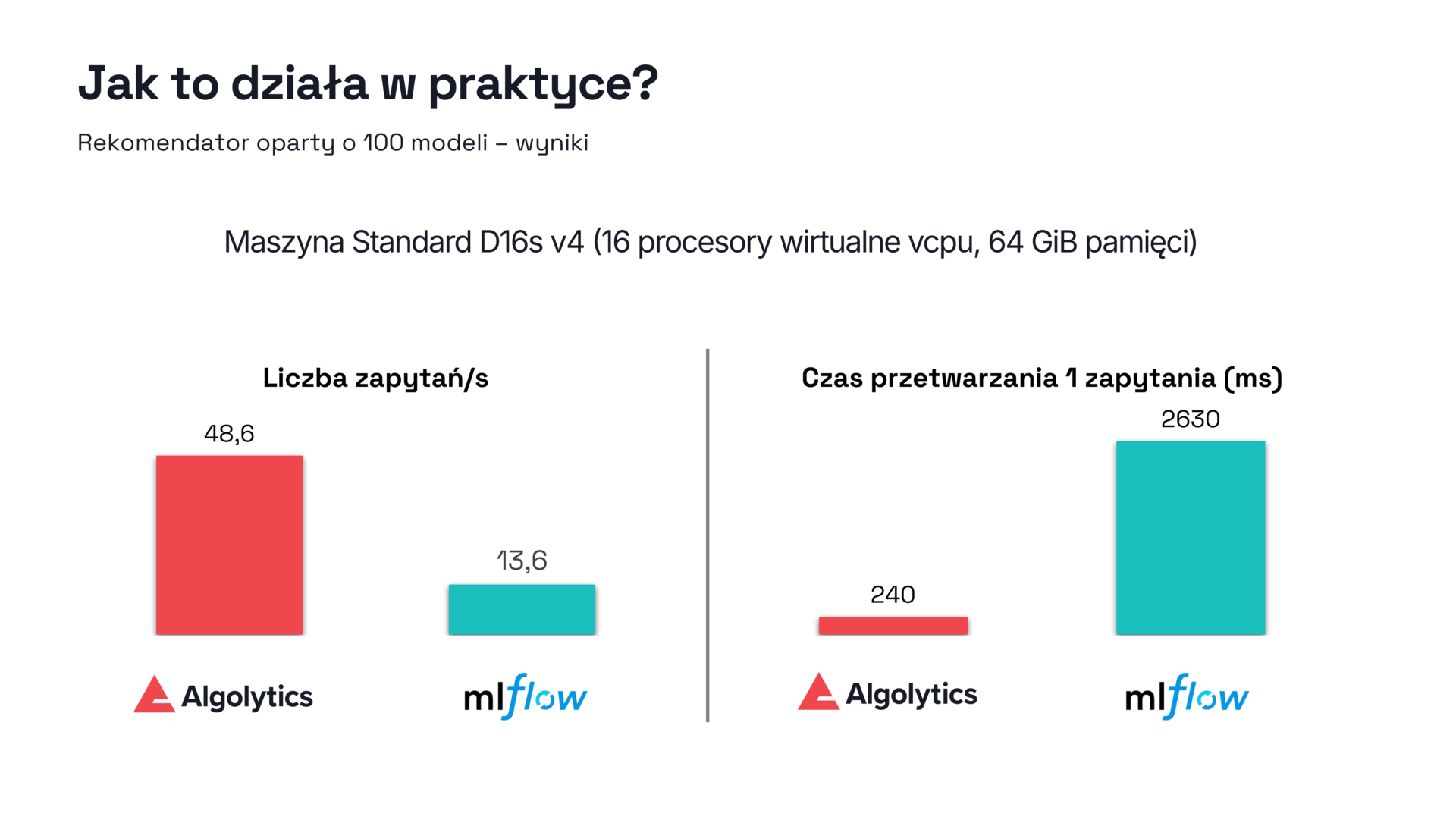
W testach porównawczych różnice w kosztach operacyjnych okazały się być znaczące. Popularne narzędzia open‑source i rozwiązania chmurowe wykazywały koszty utrzymania wyższe nawet 23-krotnie w porównaniu z platformą MLOps od Algolytics. Różnica ta wynika nie z samego modelu, ale z całego ekosystemu wykonywania: eliminacji zbędnych kontenerów, bibliotek, zależności, overheadu komunikacyjnego i braku precyzyjnego wykorzystania zasobów sprzętowych.
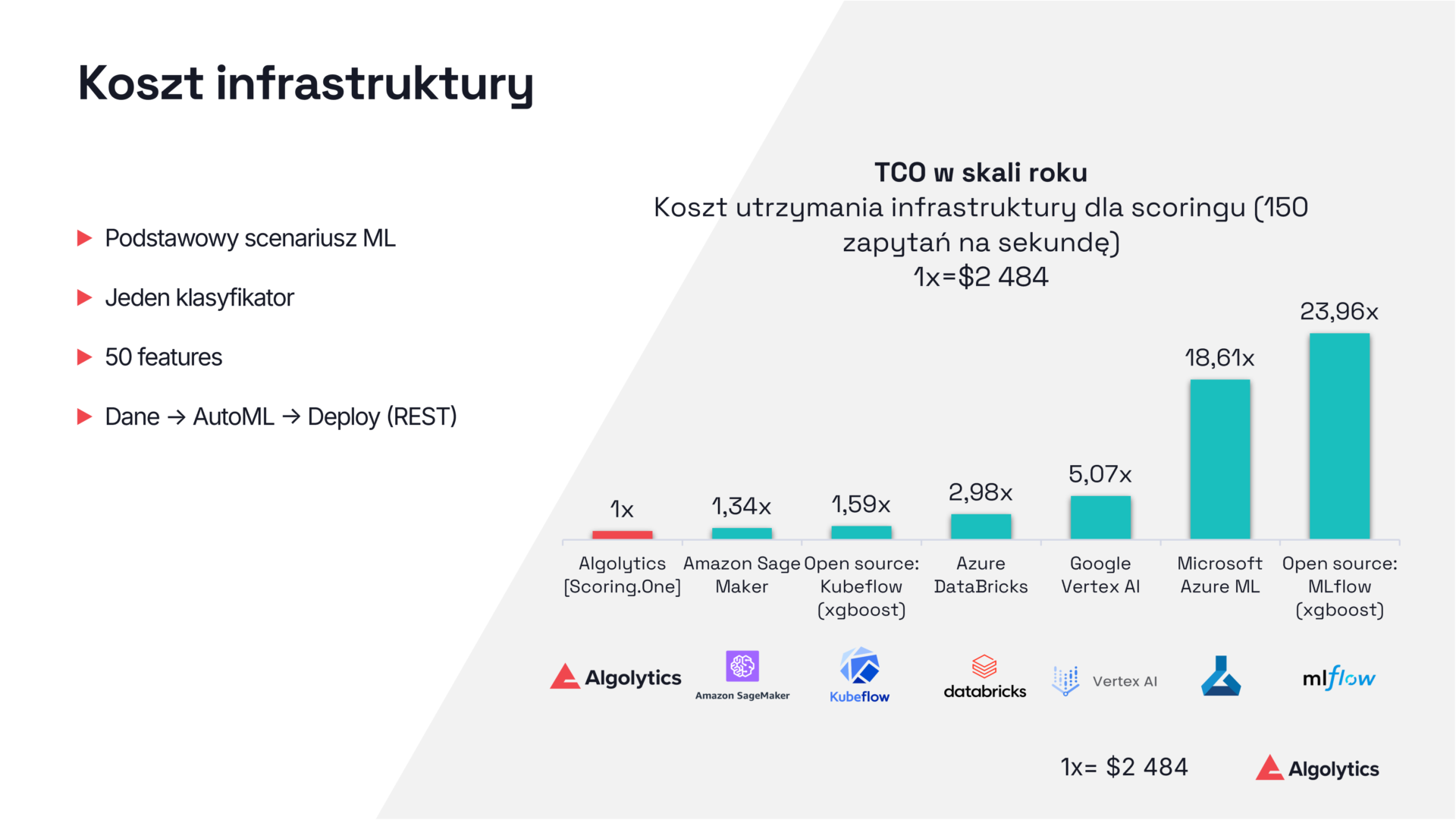
Równie istotne jest podejście do automatycznego budowania modeli. W klasycznych systemach AutoML powstają złożone konstrukcje z wieloma warstwami i ensemble’ami, które mogą być trudne do wdrożenia na dużą skalę. Zastosowanie heurystyk promujących prostsze modele prowadzi do sytuacji, w której wydajność jest znacznie wyższa przy minimalnej utracie jakości predykcji. Skupienie się na czasie inferencji zamiast maksymalnej dokładności daje realną przewagę w systemach działających pod dużym obciążeniem. Tego rodzaju podejście zastosowaliśmy w naszym rozwiązaniu AutoML.
Modelowanie złożonych aplikacji ML bez kodu
Innym istotnym elementem jest dostępność środowiska pracy, które pozwala na tworzenie, debugowanie i wdrażanie złożonych aplikacji ML bez konieczności pisania rozbudowanego kodu. Interfejsy projektowe umożliwiające wizualne budowanie pipeline’ów, integrację danych, testowanie krok po kroku oraz kontrolę wersji pozwalają pojedynczej osobie przygotować w krótkim czasie aplikację, która w klasycznym podejściu wymagałaby tygodni pracy całego zespołu.
Projektant scenariuszy z modułami pobierania danych, transformacji, uruchamiania modeli, integracji z zewnętrznymi systemami czy obsługi błędów pozwala budować złożone przepływy w sposób intuicyjny. Nawet zadania wymagające kodu można wykonywać w lekkich skryptach, bez potrzeby budowania osobnych mikroserwisów czy środowisk. Debugowanie odbywa się w czasie rzeczywistym, pozwalając analizować wyniki na każdym etapie i natychmiast korygować błędy.
Dzięki temu proces wdrażania staje się iteracyjny i szybki. Wersjonowanie pipeline’ów, możliwość przeprowadzania walidacji i natychmiastowe publikowanie modeli sprawiają, że cykl wdrożeniowy rozwiązania ML staje się znacznie krótszy, co umożliwia szybszą reakcję na zmiany w danych i potrzebach biznesowych.
Skalowanie w praktyce
Najbardziej wymiernym dowodem skuteczności uproszczonej architektury jest jej zachowanie pod dużym obciążeniem. W oparciu o platformę Algolytics jesteśmy w stanie utrzymywać na jednej instancji aplikacji Scoring.One kilka tysięcy modeli i scenariuszy, działających w czasie zbliżonym do rzeczywistego, bez widocznego spadku wydajności.
Dzięki temu firmy mogą odchodzić od kosztownych farm serwerów i skomplikowanych mechanizmów autoskalowania. Wydajna jednostka obliczeniowa okazuje się wystarczająca do obsługi ruchu o natężeniu kilku tysięcy zapytań na sekundę. Zamiast rozbudowywać infrastrukturę, organizacja zyskuje środowisko, które jest zoptymalizowane do pracy w wysokim reżimie przepustowości.
Podsumowanie: przyszłość MLOps to uproszczona złożoność
Uczenie maszynowe przestaje być niszową technologią i staje się krytycznym elementem nowoczesnych systemów informatycznych. Aby jednak mogło być wdrażane powszechnie, niezbędne jest odejście od wielowarstwowych, trudnych w utrzymaniu ekosystemów narzędzi. Największą wartością jest dziś nie mnogość komponentów, lecz spójne i efektywne środowisko.
Architektura monolitycznego, asynchronicznego silnika wykonawczego, lekkie modele kompilowane, prostota AutoML, elastyczne narzędzia projektowania i debugowania, a także możliwość równoległego uruchamiania setek modeli bez konieczności rozbudowy infrastruktury - to fundamenty nowoczesnego MLOps.
To podejście pozwala organizacjom z ograniczonymi zasobami wejść na poziom zaawansowanej analityki predykcyjnej i budować wielkoskalowe aplikacje AI szybciej, taniej i pewniej. Skuteczność takich rozwiązań nie wynika z surowej, kosztownej mocy obliczeniowej, lecz z przemyślanej architektury i świadomego ograniczania złożoności tam, gdzie nie wnosi ona wartości.
Dowiedz się więcej na temat skutecznego wdrażania uczenia maszynowego w organizacji:



