
















W Scoring.One wprowadziliśmy funkcjonalność, która znacząco zmienia sposób pracy z modelami i skryptami Python. Nowa architektura środowisk umożliwia uruchamianie kodu w wielu niezależnych wersjach Pythona z różnymi bibliotekami i konfiguracjami. Oznacza to większą elastyczność, bezpieczeństwo i przewidywalność wdrożeń modeli Machine Learning w produkcji.
To rozwiązanie powstało jako odpowiedź na rosnące potrzeby organizacji, które rozwijają coraz bardziej złożone procesy scoringowe i wymagają stabilności, skalowalności oraz pełnej kontroli nad środowiskiem wykonawczym.
Jak w Scoring.one łączymy w jednym procesie przetwarzania danych różne technologie i języki skryptowe
Jednym z podstawowych wyróżników Scoring.One jest możliwość wdrażania i używania modeli ML i algorytmów wytworzonych w różnych technologiach. Obecnie Scoring.One obsługuje modele zbudowane w:
- Platformie Algolytics (kod scoringowy implementowany jako klasa Java)
- Python
- R
- PMML
W edytorze scenariuszy istnieje możliwość wykorzystania wszystkich powyższych elementów i fragmentów kodu przygotowanego w Groovy/Java, Python czy R. Co ważne w jednym scenariuszu można wykorzystać dowolną liczbę modeli i elementów skryptowych przygotowanych w różnych technologach.
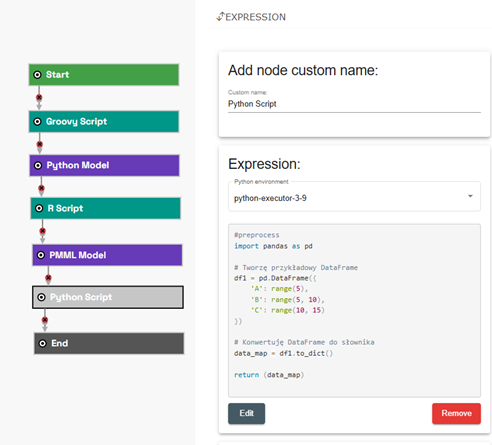
Czym są nowe środowiska Python w Scoring.One?
Nowe Python executors to niezależne kontenery odpowiedzialne za uruchamianie skryptów i modeli Python w odseparowanych środowiskach. Każdy worker posiada:
- własną wersję Pythona (np. 3.7, 3.9, 3.12),
- indywidualny zestaw bibliotek,
- własną konfigurację uruchomieniową,
- mechanizm automatycznej rejestracji w Scoring.One.
Dzięki temu można utrzymywać równolegle wiele środowisk, bez obawy o konflikty bibliotek czy problemy z różnicami między środowiskiem trenowania a produkcją.
Dla kogo i dlaczego to ważne?
Nowe środowiska Python mają szczególne znaczenie dla organizacji, które pracują z wieloma modelami ML równolegle oraz rozwijają je w różnych stosach technologicznych. Najwięcej korzyści zauważą:
Bankowość i finanse
Wiele modeli scoringowych i antyfraudowych działa równolegle, a każdy może wymagać innych zależności.
Telco i branża subskrypcyjna
Modele churn, propensity i rekomendacyjne często wykorzystują różne biblioteki ML, które trudno utrzymać w jednym środowisku.
E‑commerce i marketing
Dynamiczne testowanie nowych wariantów modeli predykcyjnych wymaga pełnej izolacji środowisk.
Sektor publiczny
Stabilność i transparentność działania modeli jest kluczowa - izolacja środowisk minimalizuje ryzyko.
Dzięki workerom Python zespoły otrzymują:
- pełną elastyczność wyboru technologii,
- przewidywalność wdrożeń,
- wyższe bezpieczeństwo modeli,
- brak konfliktów bibliotek między projektami.
Jak działa architektura workerów Python?
Aby zapewnić pełną kontrolę nad środowiskiem uruchomieniowym, Scoring.One wykorzystuje osobne jednostki wykonawcze.
Workery komunikują się z platformą poprzez zestaw endpointów:
- /register – rejestracja nowego środowiska,
- /compute – uruchamianie modeli Python,
- /compute/python – uruchamianie skryptów Python,
- /health – monitoring stanu usługi.
Silnik Scoring.One automatycznie wybiera właściwe środowisko dla danego modelu na podstawie jego konfiguracji. Dzięki temu cały proces jest skalowalny i przewidywalny.
Wybór środowiska Python
Nowy parametr środowiska jest dostępny:
- w GUI – przy wdrażaniu modelu i konfiguracji węzła expression,
- w API – poprzez pobranie listy dostępnych środowisk:
GET /api/python/environment
To pozwala na tworzenie modeli w jednym środowisku, a uruchamianie ich w innym lub równoległe testowanie wielu wariantów.
Wdrażanie modeli Python w praktyce
Proces wdrażania modeli Python pozostaje prosty, ale zyskuje dzięki możliwości wyboru środowiska wykonawczego. Paczka ZIP z modelem powinna zawierać:
- skrypt Python z logiką uruchamiającą model/algorytm,
- plik z metadanymi wejść,
- plik pickle/dill z modelem ML.
Przy wdrożeniu użytkownik wskazuje środowisko, w którym model ma być wykonany. To gwarantuje powtarzalność i zgodność z fazą trenowania.
Obsługa danych i serializacja
Workery Python obsługują szeroki zakres typów danych używanych w data science:
- obiekty Pandas,
- tablice NumPy,
- macierze rzadkie SciPy,
- typy datowe i numeryczne Pythona,
- standardowy JSON.
Konwersja jest realizowana automatycznie, nie trzeba tworzyć własnych serializerów.
Obsługa błędów
System prezentuje pełne tracebacks, miejsce wystąpienia błędu oraz kontekst wykonania. Ułatwia to diagnozę problemów i skraca czas napraw.
Skalowanie środowisk – on‑premise, cloud i hybryda
Dzięki modularności workerów można uruchamiać je w dowolnej infrastrukturze:
On‑premise
Pełna kontrola nad infrastrukturą, szczególnie w organizacjach regulowanych.
Cloud
Elastyczne skalowanie środowisk, szybkie wdrożenia i możliwość automatyzacji.
Hybryda
Połączenie zalet obu podejść: modele krytyczne lokalnie, eksperymentalne – w chmurze.
Jak wdrożyć nowe środowiska Python – krok po kroku
Aby szybko rozpocząć pracę z nową architekturą, warto przejść przez krótką listę kroków:
- Zdefiniuj wymagania środowiskowe (wersja Python + biblioteki).
- Przygotuj obraz kontenera.
- Przetestuj model lokalnie.
- Uruchom worker w środowisku docelowym.
- Poczekaj na jego automatyczną rejestrację w Scoring.One.
- Wybierz środowisko podczas wdrażania modelu.
- Przeprowadź finalne testy integracyjne.
To podejście jest szybkie, bezpieczne i skalowalne.
FAQ - najczęściej zadawane pytania
Czy mogę mieszać modele działające w różnych wersjach Pythona?
Tak - każdy element scenariusza może działać w innym środowisku Python.
Jak sprawdzić listę dostępnych środowisk?
Przez GUI lub API (GET /api/python/environment).
Czy worker może działać na innym serwerze?
Tak - pod warunkiem, że ma dostęp do Scoring.One.
Jakie typy danych są obsługiwane?
Pandas, NumPy, SciPy, datetime, JSON i wiele innych.
Podsumowanie
Nowe środowiska Python w Scoring.One zapewniają pełną elastyczność i kontrolę nad procesem wykonywania modeli Machine Learning. Pozwalają budować i utrzymywać złożone procesy scoringowe bez obaw o konflikty bibliotek, stabilność środowiska czy skalowalność infrastruktury. Dzięki temu praca z modelami ML staje się prostsza, szybsza i bardziej przewidywalna - niezależnie od liczby wdrożonych modeli i ich złożoności.
Chcesz lepiej zrozumieć, jak Scoring.One wspiera budowę, wdrażanie i skalowanie modeli Machine Learning? Poznaj wszystkie możliwości platformy oraz architekturę działania.



