Wyzwania identyfikacji użytkownika w modelach cookiebased
W analityce internetowej jak również w wielu specyficznych zastosowaniach (np. identyfikacja nadużyć) kluczowe jest poprawne rozpoznawanie unikalnych użytkowników odwiedzających serwis. W praktyce jednak ten sam człowiek często korzysta z wielu urządzeń – na przykład smartfona, tabletu i komputera – które z punktu widzenia systemów analitycznych wyglądają jak odrębni użytkownicy. Bez dodatkowych mechanizmów każda przeglądarka lub urządzenie otrzymuje własny identyfikator (tzw. cookie), co oznacza, że ta sama osoba na różnych urządzeniach jest liczona wielokrotnie. Powoduje to zawyżenie statystyk odwiedzin i zniekształcenie danych o zachowaniu klientów – np. jedna osoba korzystająca z telefonu i laptopa byłaby traktowana jak dwaj różni użytkownicy.
Dodatkowym wyzwaniem jest czyszczenie plików cookie lub korzystanie z trybu prywatnego. Wielu internautów regularnie usuwa ciasteczka albo blokuje je z powodów prywatności. W efekcie po wyczyszczeniu danych przeglądarki wracający użytkownik otrzymuje nowy identyfikator i znów jest widziany jak „nowy” odwiedzający.
Unifikacja tożsamości jako warunek poprawnych analiz i modeli AI
Z perspektywy biznesowej zaburza to analizy kohort, śledzenie ścieżek konwersji oraz modele atrybucji – np. trudno ocenić faktyczną liczbę powracających klientów czy przypisać wpływ poszczególnych kanałów marketingowych na jedną osobę.
Dane wejściowe do modeli machine learning również tracą jakość, bo zachowanie jednego użytkownika jest rozproszone pomiędzy wiele sztucznie utworzonych tożsamości. Potrzebne jest zatem rozwiązanie, które mimo tych utrudnień pozwoli jednoznacznie identyfikować użytkownika (lub gospodarstwo domowe) w świecie wielourządzeniowym i pomimo kasowania cookies – tak, aby statystyki użytkowników były rzetelne, a modele predykcyjne oraz kampanie marketingowe operowały na dokładnych danych.
Czym jest Identity Graph?
Rozwiązaniem wspomnianych problemów jest koncepcja Identity Graph (grafu tożsamości). W uproszczeniu jest to grafowa baza danych przechowująca powiązania między różnymi identyfikatorami, które mogą reprezentować tego samego użytkownika. Węzłami (nodami) w grafie są różnego typu identyfikatory związane z interakcjami online, m.in.:
- unikalne identyfikatory urządzeń lub przeglądarek (np. pliki cookie przypisane przez serwis),
- device fingerprinty (cyfrowe „odciski palca” urządzeń),
- adresy IP,
- identyfikatory logowania (np. UUID przypisany zalogowanemu użytkownikowi czy adres e-mail).
Graf tożsamości budowany przez Algolytics integruje powyższe elementy. Każdy węzeł reprezentuje konkretny identyfikator, a krawędzie grafu odzwierciedlają zaobserwowane relacje między nimi – na przykład fakt, że dany cookie pojawił się z konkretnego adresu IP albo że pewien fingerprint urządzenia był powiązany z kilkoma różnymi cookies.
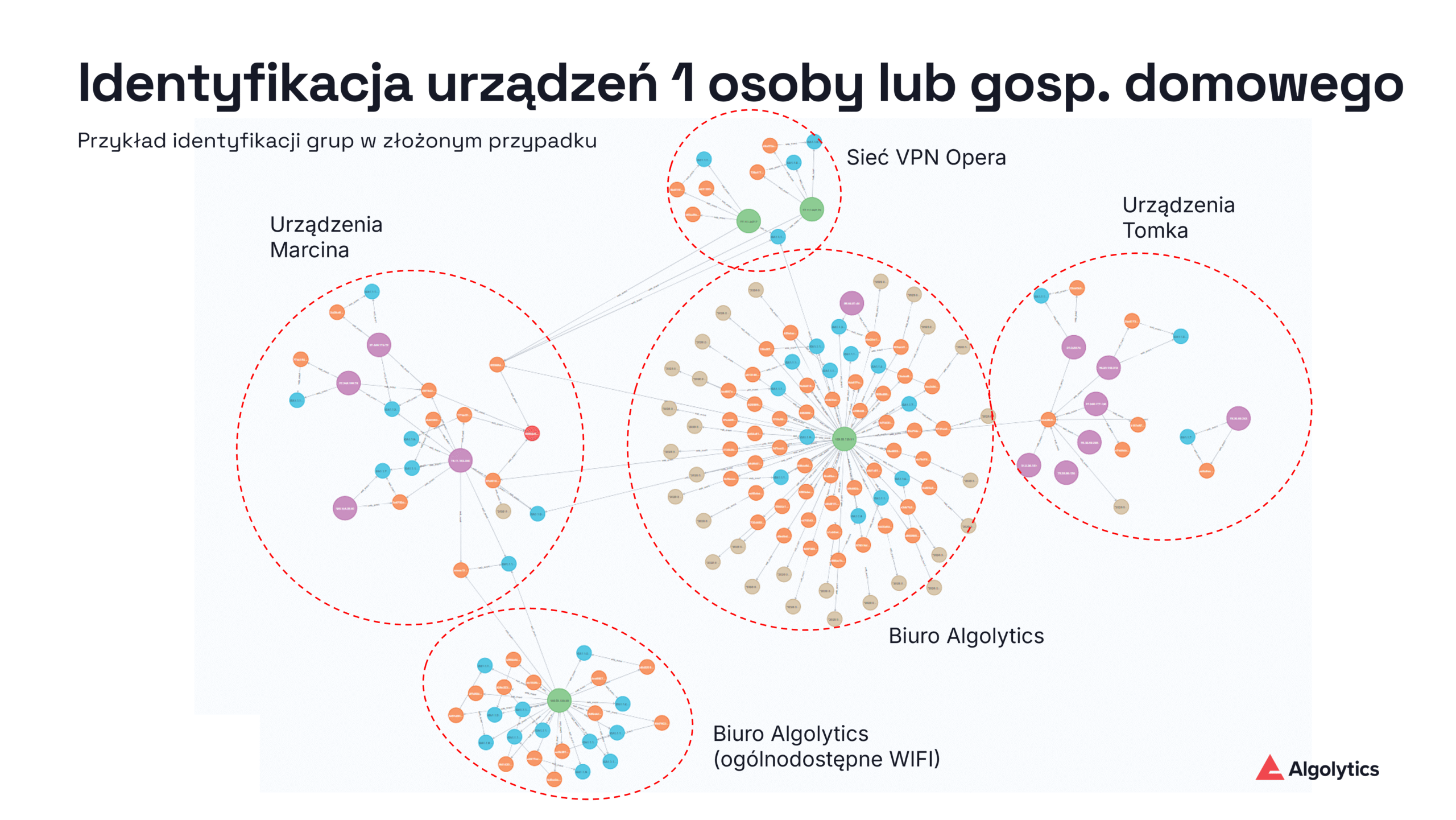
Struktura grafowa umożliwia odnajdywanie połączeń nawet między pozornie odrębnymi identyfikatorami. Przykładowo, jeśli użytkownik A najpierw odwiedził stronę na telefonie (cookie X, fingerprint F1, IP1), a potem na laptopie (cookie Y, fingerprint F2, IP1), to graf ujmie wspólny adres IP1 i być może inne cechy jako łącznik, sugerując że X i Y to ta sama osoba. Innym przykładem jest sytuacja, gdy użytkownik loguje się na jednym urządzeniu – wtedy jego identyfikator konta zostaje powiązany z cookie oraz fingerprintem z tej sesji, co w grafie doda krawędzie między tymi identyfikatorami. Z czasem graf tożsamości rozrasta się, grupując identyfikatory w komponenty odpowiadające realnym jednostkom (osobie lub gospodarstwu domowemu).
Mechanizm crossuid – konsolidacja tożsamości użytkownika w analizach
Powiązane identyfikatory otrzymują wspólny identyfikator grupowy – w rozwiązaniu Algolytics nazywany crossuid (można go rozumieć jako anonimowy identyfikator użytkownika lub gospodarstwa domowego). To właśnie crossuid jest docelowym kluczem używanym dalej w analizach zamiast pojedynczych cookie czy urządzeń. Dzięki temu, zamiast trzech osobnych rekordów dla użytkownika na telefonie, użytkownika na laptopie i użytkownika na tablecie, otrzymujemy jeden scalony profil (crossuid), do którego przypisane są wszystkie działania tego użytkownika.
Graf tożsamości jako mapa powiązań użytkowników
Graf tożsamości pełni więc rolę mapy powiązań – jego węzły (cookie, loginy, fingerprinty, IP itp.) połączone krawędziami tworzą sieci odpowiadające unikalnym użytkownikom. Gdy graf zostanie zasilony dostateczną ilością danych, umożliwia on skuteczne łączenie i konsolidację fragmentarycznych informacji o użytkownikach z różnych źródeł, zapewniając spójny obraz klienta we wszystkich kanałach online. To podejście jest coraz szerzej wykorzystywane w marketingu i analityce – od platform klasy CDP po rozwiązania antifraudowe – teraz dostępne również jako gotowy komponent platformy Scoring.one.
Fingerprinting urządzeń
Jednym z istotnych elementów grafu tożsamości jest device fingerprinting, czyli technika identyfikacji urządzenia na podstawie jego charakterystycznych cech. Fingerprint przeglądarki to w praktyce unikalny skrót (hash) obliczany przez skrypt w oparciu o szereg informacji ujawnianych przez przeglądarkę. Pod uwagę brane są m.in. nagłówek User-Agent (zawierający wersję przeglądarki i systemu operacyjnego), rozdzielczość ekranu, lista zainstalowanych czcionek, strefa czasowa, język, a nawet tak niszowe parametry jak wynik testu Canvas API czy AudioContext. Wiele z tych parametrów w pojedynczej kombinacji jest unikatowych dla danego urządzenia, dzięki czemu powstały fingerprint działa jak cyfrowy „odcisk palca”.
Co ważne, identyfikator fingerprint nie jest przechowywany po stronie użytkownika, więc nie podlega prostemu czyszczeniu jak ciasteczka – za każdym razem może zostać na nowo wyliczony z bieżących właściwości przeglądarki.
Fingerprinting jako metoda identyfikacji mimo kasowania cookies / zmiany IP
Dzięki fingerprintingowi możemy rozpoznać użytkownika nawet wtedy, gdy zmieni adres IP czy wyczyści cookies. Przykładowo, jeśli internauta regularnie usuwa ciasteczka, to przy kolejnych wizytach dostaje nowe cookie – jednak charakterystyka jego przeglądarki i urządzenia (np. ten sam zestaw wtyczek, rozdzielczość ekranu, czcionki, itp.) zazwyczaj pozostaje stała. System generujący fingerprint zauważy, że nowy cookie ma identyczny „odcisk” urządzenia co wcześniej obserwowany użytkownik, co sugeruje tę samą osobę. W grafie tożsamości zostanie wtedy utworzony węzeł fingerprint powiązany krawędziami z zarówno starym, jak i nowym węzłem cookie – łącząc te dwie sesje w jedną tożsamość.
Wykorzystanie fingerprintingu w marketingu i cyberbezpieczeństwie
Podobnie, fingerprint pomaga łączyć aktywność z różnych przeglądarek na tym samym urządzeniu – choć tu skuteczność bywa niższa, bo nie wszystkie cechy (np. lista wtyczek) są współdzielone między różnymi przeglądarkami. Niemniej jednak fingerprinting stanowi potężne uzupełnienie klasycznych metod identyfikacji, zwiększając odporność systemu na typowe zabiegi śledzące (jak tryb incognito czy blokery reklam). Warto dodać, że podejście to jest wykorzystywane nie tylko w analityce marketingowej, ale i w bezpieczeństwie – np. banki internetowe stosują fingerprint urządzenia do wykrywania nietypowych logowań (inny komputer niż zwykle) celem uwierzytelnienia wieloskładnikowego.
Scoring.One - orkiestracja całego procesu
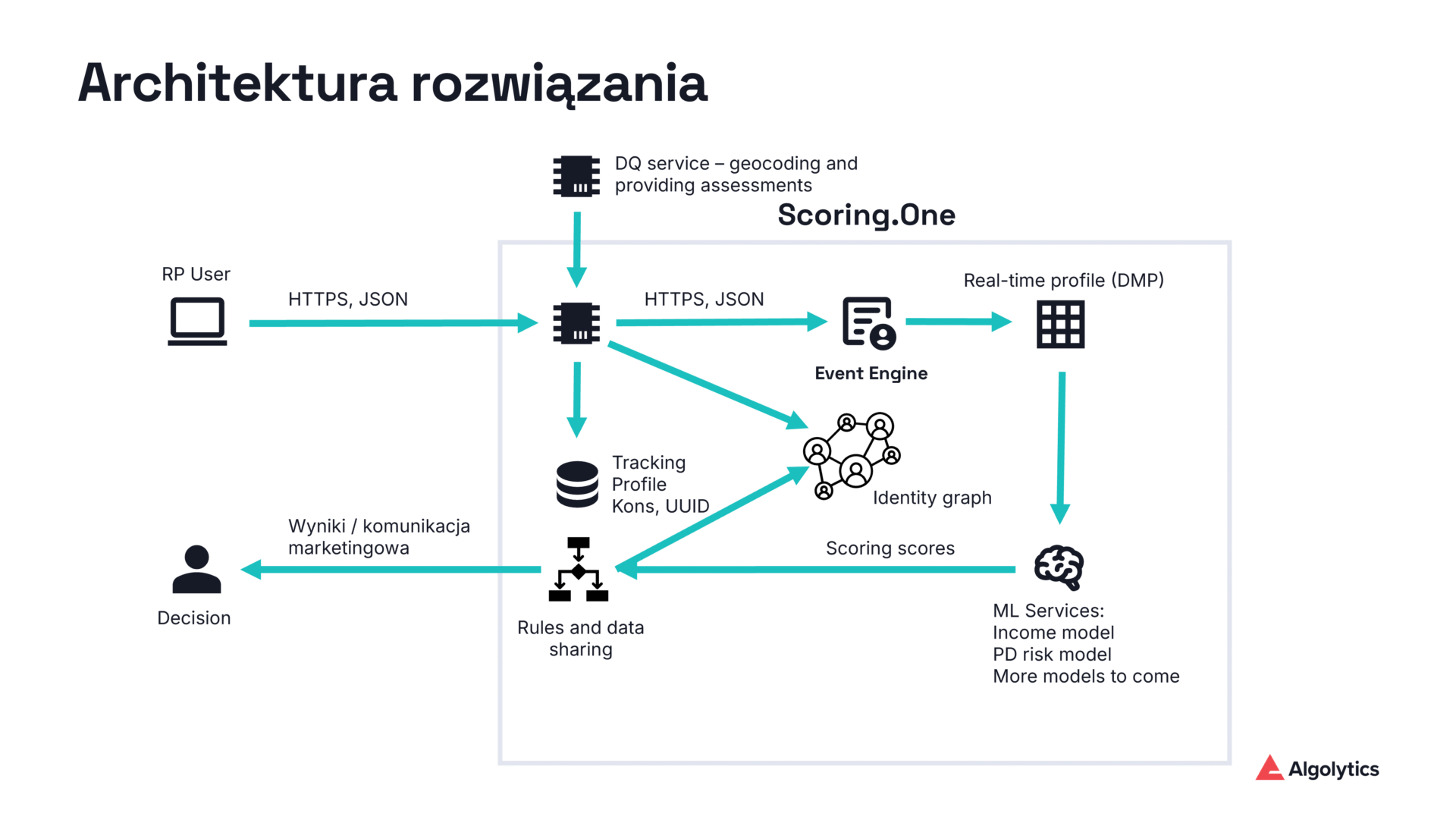
Opisywany graf tożsamości został zaimplementowany w ramach platformy Algolytics Scoring.One – uniwersalnego silnika do przetwarzania danych i zdarzeń w czasie rzeczywistym. Scoring.One to zintegrowane środowisko MLOps, łączące w jednym systemie mechanizmy strumieniowego przetwarzania danych, scoringu i analityki predykcyjnej.
Platforma pozwala wdrażać modele i złożone scenariusze decyzyjne w ciągu kilku dni zamiast miesięcy, przetwarzając tysiące zapytań na sekundę dla dziesiątek jednocześnie działających reguł i modeli. Innymi słowy, Scoring.One może w czasie rzeczywistym odbierać wydarzenia (np. zdarzenia z witryny WWW, transakcje, logi systemowe), obliczać na ich podstawie zdefiniowane cechy, oceny lub decyzje biznesowe, a także podejmować działania zwrotne (np. zwrócić odpowiedź przez API czy zaktualizować pewne dane w bazie).
Real-time identity graph: architektura i działanie Scoring.One
Schemat działania algorytmu jest następujący: z każdą interakcją użytkownika (np. odsłoną strony internetowej) Scoring.One rejestruje zdarzenie i uruchamia scenariusz analityczny (tzw. scoring scenario). Scenariusz ten w locie wzbogaca dane zdarzenia o dodatkowe informacje (np. dane geolokalizacyjne i sieciowe na podstawie IP użytkownika) oraz aktualizuje graf w bazie danych grafowej. Platforma umożliwia definiowanie skomplikowanych reguł, dzięki którym każda kolejna obserwacja (wejście na stronę, kliknięcie itp.) natychmiast wpływa na stan grafu tożsamości.
Co więcej, Scoring.One udostępnia API do zadawania zapytań w czasie rzeczywistym – np. można przesłać zapytanie z identyfikatorem cookie, a system zwróci przypisany mu identyfikator crossuid, wyszukany na podstawie aktualnego stanu grafu. Wszystkie te operacje są silnie zoptymalizowane pod kątem wydajności, dzięki czemu możliwe jest interaktywne łączenie danych o użytkownikach w ułamku sekundy nawet przy ruchu rzędu setek tysięcy zdarzeń dziennie.
Moduły walidacji i wzbogacania danych w Scoring.One
Dzięki elastyczności Scoring.One stworzyliśmy bogaty ekosystem integracji – np. gotowe moduły do walidacji i uzupełniania danych (geokodowanie adresów, weryfikacja firm), integracje z zewnętrznymi bazami (np. bazy finansowe, bazy adresowe itp.), czy możliwość wdrażania własnych modeli ML.
Ważnym elementem jest integracja z zewnętrznymi źródłami danych o adresach IP. Scoring.One potrafi w locie pobrać informacje o danym IP, m.in. geolokalizację (kraj, miasto), nazwę organizacji / operatora oraz typ łącza. Wykorzystano to zarówno do odfiltrowywania ruchu botów, jak i do zdefiniowania reguł łączenia urządzeń w grafie – szczegóły opisujemy poniżej.
Proces nadawania identyfikatora użytkownika
Jedną z funkcjonalności udostępnianej przez Scoring.One jest konfigurowalny skrypt trackujący pozwalający na szybką i prostą integrację z portalem internetowym algorytmów pobierających dane i wysyłających je do Scoring.One.
Poniżej przedstawiamy krok po kroku, jak rozwiązanie Algolytics identyfikuje użytkownika na podstawie kolejnych zdarzeń www i nadaje mu wspólny identyfikator grupowy (crossuid):
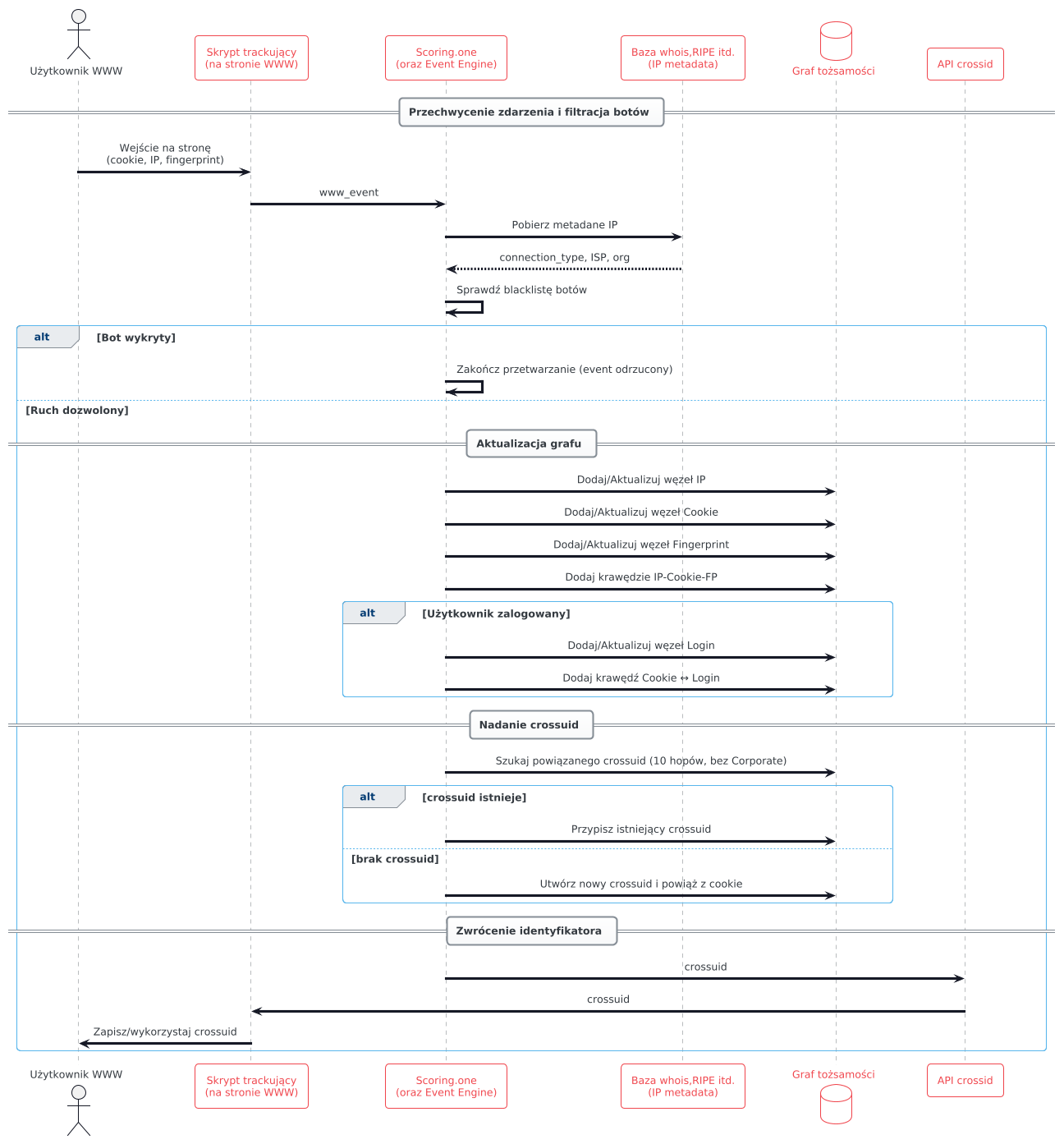
Przechwycenie zdarzenia i filtracja botów
Gdy Scoring.One odbiera nowe zdarzenie ze strony WWW (np. wywołanie skryptu śledzącego), pierwszym krokiem jest wykluczenie ruchu botów. System sprawdza adres IP źródłowy – jeśli znajduje się on na wewnętrznej liście znanych robotów (np. skanery Googlebot, Bing, crawlery Facebooka itp.), zdarzenie zostaje odrzucone już na poziomie scenariusza trackującego. Dodatkowo, po wzbogaceniu danych IP o informacje o geoloklizacji, operatorze czy typie połączenia stosowany jest kolejny filtr: odrzucane są zdarzenia, w których nazwa operatora telekomunikacyjnego wskazuje na duże firmy technologiczne lub dostawców chmurowych, typowych dla ruchu automatycznego. Przykładowo ruch pochodzący z adresów należących do Apple, Google, Microsoft, Yandex czy Facebook zostanie zignorowany. Takie adresy często generują setki wejść z unikalnymi ciasteczkami (typowy ślad bota), co w przypadku nieodfiltrowania sztucznie generowałoby nam graf z milionami fałszywych powiązań i węzłów.
Dodanie/aktualizacja węzła IP
Jeśli zdarzenie pochodzi od realnego użytkownika, platforma rejestruje w grafie jego adres IP (węzeł typu IP). IP mogą występować zarówno jako adresy domowe, firmowe, jak i mobilne – a każdy z tych typów wymaga innego traktowania. System etykietuje adresy IP atrybutami takimi jak typ połączenia, dostawca/usługa (ISP lub organizacja) itp., co pomaga w podejmowaniu dalszych decyzji. Adresy mobilne otrzymały specjalną logikę separacji: jeżeli to samo mobilne IP pojawia się po raz kolejny w ciągu 48 godzin, uznajemy że może to być wciąż ten sam abonent korzystający z puli adresów operatora komórkowego – wtedy aktualizujemy znacznik czasu istniejącego węzła IP. Natomiast jeśli od ostatniego użycia minęło ponad 48h, traktujemy to samo IP jak nowy, tworząc odrębny węzeł. Zapobiega to łączeniu w grafie zupełnie obcych osób, którym operator przydzielił ten sam adres np. w odstępie tygodnia. Dzięki temu sieci powiązań (komponenty grafu) nie rozrastają się niekontrolowanie w wyniku dynamicznej rotacji adresów IP typowej dla sieci komórkowych.
Powiązanie cookie z IP
Równocześnie ze zidentyfikowaniem IP, system przetwarza identyfikatory cookie obecne w zdarzeniu. Standardowo Algolytics wykorzystuje własny tracking cookie (nazywany ext_sceuid), a także może pobierać inne identyfikatory sesyjne (np. cookie Google Analytics _ga, session_id itp.). Dla każdego takiego identyfikatora tworzony jest (o ile nie istnieje) węzeł typu cookie w grafie. Następnie dodawane są krawędzie łączące cookie z aktualnym węzłem IP. Taka krawędź oznacza „cookie X widziano pod adresem IP Y” i stanowi pierwszą wskazówkę potencjalnej wspólnej tożsamości z innymi cookie pojawiającymi się na tym IP.
Dodanie fingerprintu urządzenia
Jeśli w zdarzeniu obecny jest wygenerowany fingerprint urządzenia, również i on jest uwzględniany. System tworzy węzeł fingerprint (np. na podstawie przekazanego identyfikatora przeglądarki wygenerowanego za pomocą biblioteki fingerprintingowej) i wiąże go krawędziami z węzłem cookie oraz IP. W efekcie w grafie powstaje trójstyk: IP – cookie – fingerprint, co oznacza „cookie X i fingerprint F wystąpiły razem na IP Y”. Jeżeli użytkownik wyczyści cookies i dostanie nowe cookie X2, ale fingerprint F pozostanie ten sam, w kolejnym zdarzeniu utworzy się połączenie X2 – F – Y, a ponieważ F połączył się już wcześniej z X, w grafie zbuduje się ścieżka łącząca X z X2 (poprzez wspólny fingerprint). To pozwoli rozpoznać, że X2 to ten sam użytkownik co X pomimo utraty ciasteczka.
Powiązanie identyfikatora zalogowanego użytkownika
W sytuacji, gdy użytkownik jest zalogowany i zdarzenie zawiera jego stały identyfikator, graf również to odnotowuje. Tworzony jest lub aktualizowany węzeł typu login/algolytics_uuid, który następnie zostaje powiązany z wcześniej utworzonym węzłem cookie. W praktyce oznacza to np.: „cookie X należy do zalogowanego użytkownika Jan Kowalski (user123)”. Dzięki temu, jeśli ten sam Jan Kowalski zaloguje się kiedyś na innym urządzeniu (inny cookie, fingerprint, IP), system szybko skonsoliduje te sesje – w grafie oba cookie będą miały wspólny węzeł login, a więc znajdą się w jednym komponencie tożsamości.
Nadanie wspólnego identyfikatora (crossuid)
Powyższe operacje dodają do grafu nowe węzły i powiązania. Ostatnim krokiem jest ustalenie, czy pojawiająca się właśnie sieć połączeń ma już przypisany swój identyfikator grupowy (crossuid). W tym celu system sprawdza, czy z danym węzłem cookie (rozpatrywanym jako punkt wyjścia) jest już połączony jakiś węzeł crossuid w promieniu do 10 krawędzi w grafie. Przeszukiwanie grafu ignoruje przy tym połączenia o typie Corporate, czyli powiązania przez sieć firmową/korporacyjną. Ma to zapobiec łączeniu w jedną grupę wielu użytkowników, którzy co prawda pojawili się pod wspólnym adresem (np. w biurze lub kawiarni), ale poza tym nie mają ze sobą związku. Jeśli w zasięgu 10 krawędzi znajdzie się węzeł crossuid, przyjmowany jest on jako identyfikator grupowy dla bieżącego urządzenia. Natomiast jeśli nie istnieje jeszcze crossuid dla tej podsieci powiązań, system utworzy nowy węzeł crossuid i powiąże go z analizowanym cookie. Tym samym cały nowo powstały komponent grafu (np. obejmujący cookie, fingerprint i IP danego użytkownika) zostaje oznaczony świeżym identyfikatorem grupowym. Każdy crossuid jest unikalnym UUID i reprezentuje w grafie odrębną grupę urządzeń, którą – zależnie od kontekstu – można utożsamiać z pojedynczym anonimowym użytkownikiem lub właśnie gospodarstwem domowym.
Identyfikator użytkownika na żądanie – jak działa API Algolytics
Na tym etapie platforma może zwrócić wynik do klienta, np. poprzez API zdarzeniowe lub metodę w JavaScript, dzięki czemu dalsze interakcje mogą już korzystać z tego scalonego identyfikatora. W rozwiązaniu Algolytics przygotowano dedykowany scenariusz, który udostępnia API HTTP umożliwiające uzyskanie crossuid na żądanie.
Przykładowo, wywołanie API z podaniem konkretnego cookie Algolytics (ext_sceuid) lub fingerprintu sesji spowoduje odpytywanie bazy grafowej w poszukiwaniu odpowiedniego crossuid. W odpowiedzi serwis zwraca unikalny identyfikator crossuid w formacie UUID, wraz z ewentualnymi dodatkowymi metadanymi (np. datą utworzenia).
Ten identyfikator może być następnie wykorzystany po stronie frontendu (np. zapisany w lokalnej bazie przeglądarki) lub przekazany do dalszych systemów analitycznych jako stabilny klucz użytkownika. Co ważne, jedna osoba zawsze ma przypisany ten sam crossuid (dopóki istnieje jakaś ścieżka powiązań między jej urządzeniami), więc nawet po długim czasie można rozpoznać powracającego klienta. Gdyby zaś doszło do potencjalnie bardzo rozbudowanego grafu (np. sieć powiązań wskazująca na bota, który generuje tysiące połączeń), system posiada mechanizmy ochronne – np. limit czasu 10 sekund na zapytanie grafowe oraz wybór najstarszego crossuid w razie wykrycia kolizji.
Przykłady zastosowań i korzyści
Opisane rozwiązanie – łączące grafową identyfikację z możliwościami Scoring.One – otwiera szereg możliwości praktycznego wykorzystania w biznesie. Poniżej kilka kluczowych zastosowań i korzyści:
Dokładniejsza analityka webowa
Dzięki grafowi tożsamości metryki takie jak liczba unikalnych użytkowników, częstotliwość wizyt czy ścieżki konwersji stają się rzetelniejsze. Eliminacja duplikatów (spowodowanych wieloma urządzeniami lub resetem cookies) oznacza, że wskaźniki KPI – np. średnia liczba sesji na użytkownika, czas życia klienta – odzwierciedlają rzeczywiste zachowania jednej osoby, a nie sumę kilku pseudotożsamości. Pozwala to firmom lepiej ocenić efektywność działań marketingowych i produktowych.
Lepsze modelowanie i personalizacja ML
Konsolidacja danych o użytkowniku przekłada się na bogatsze profile z większą liczbą atrybutów i dłuższą historią zachowań. Modele machine learning (np. do rekomendacji, predykcji churn czy oceny ryzyka fraudowego) mogą korzystać z pełniejszego obrazu aktywności klienta. Poprawia to ich dokładność predykcji, bo eliminujemy „szum” w postaci zniekształconych danych (np. model nie myli już jednego użytkownika z trzema). Dodatkowo, crossuid może służyć jako stabilny klucz do łączenia danych z różnych źródeł (np. danych transakcyjnych, CRM, behawioralnych), co sprzyja tworzeniu bardziej zaawansowanych funkcji wejściowych do modeli.
Trafniejsze kampanie marketingowe i UX
Mając wspólny identyfikator, marketerzy mogą prowadzić spójne kampanie cross-device – np. limitować liczbę wyświetleń reklamy per faktyczny użytkownik (frequency capping) niezależnie od urządzenia, czy kontynuować przekaz marketingowy zaczęty na komputerze również na smartfonie. Segmentacja klientów staje się precyzyjniejsza – można tworzyć grupy użytkowników na podstawie pełnej aktywności (np. osoby oglądające dany produkt najpierw na telefonie, a potem kupujące na desktopie). Dla samego użytkownika skutkuje to lepszym dopasowaniem treści (personalizacja) i mniejszą irytacją powtarzającymi się komunikatami. Poprawia się również doświadczenie użytkownika – np. znając crossuid, serwis może rozpoznać powracającego klienta i zapewnić ciągłość sesji (podtrzymanie koszyka zakupowego między urządzeniami itp.).
Redukcja błędnych danych i detekcja botów
Wdrożenie grafu tożsamości wymusza rygorystyczne podejście do jakości danych. Mechanizmy filtracji botów usuwają z ruchu spam i sztuczny ruch, zanim trafi on do analiz czy modeli. To przekłada się na czytelniejsze raporty oraz odporność na nadużycia (np. manipulację licznikami odsłon przez skrypty). Ponadto sam graf może służyć do wykrywania podejrzanych wzorców – np. węzeł IP połączony nagle z setkami unikalnych cookie (sygnał bota) albo fingerprint pojawiający się na dziesiątkach kont (sygnał oszustwa) może automatycznie podnosić alarm. Identyfikacja nieautentycznych użytkowników w czasie rzeczywistym umożliwia szybkie reagowanie (blokada, zmiana strategii), zanim wpłyną oni na metryki biznesowe.
Koniec z rozproszoną tożsamością – spójne dane o klientach
Rozwiązanie opracowane przez Algolytics pokazuje, że grafowa identyfikacja użytkowników w połączeniu z wydajnym silnikiem przetwarzania zdarzeń potrafi skutecznie rozwiązać problemy rozproszonej tożsamości w analityce internetowej. Z biznesowego punktu widzenia przekłada się to na bardziej wiarygodne dane o klientach, możliwość prowadzenia zaawansowanych analiz zachowań oraz optymalizację działań marketingowych pod kątem realnych osób, nie przeglądarek. Technicznie zaś, zastosowanie platformy Scoring.One gwarantuje skalowalność – system działa w czasie rzeczywistym nawet dla wysokiego wolumenu ruchu – oraz elastyczność w dostosowywaniu reguł.