
















Deduplikacja danych adresowych: jak poprawnie tworzyć rekordy typu "golden record"?
W erze cyfrowej transformacji jakościowe dane stają się jednym z kluczowych zasobów każdej organizacji. Niepoprawne, nieaktualne lub zdublowane dane w systemach CRM, bazach marketingowych czy rejestrach operacyjnych prowadzą nie tylko do utraty czasu, ale również kosztów finansowych i błędnych decyzji. Jednym z najważniejszych procesów w zakresie poprawy jakości danych jest deduplikacja – a jej zwieńczeniem stworzenie tzw. „golden record”, czyli pojedynczego, najbardziej wiarygodnego zapisu reprezentującego dany podmiot czy klienta.
Dlaczego deduplikacja jest konieczna?
W bazach danych często spotykamy zjawiska takie jak:
- ten sam klient zapisany wielokrotnie, z błędami lub wariantami pisowni,
- adresy zapisane niejednolicie, np. „ul. Mickiewicza 10” vs „Adama Mickiewicza 10” vs „Mickiewicza 10”,
- rozbieżności między bazami: CRM, systemy billingowe, e-commerce,
- brak standardów zapisu – dane luźne, skróty, literówki, błędy OCR, brak polskich znaków.
Te błędy skutkują:
- duplikacją działań i nadmiernym kontaktem z klientami,
- błędami i nieefektywnymi procesami operacyjnymi,
- nieskutecznymi kampaniami marketingowymi,
- błędną analizą danych przestrzennych i statystycznych,
- problemami z wysyłką korespondencji i faktur,
- błędami w raportach zarządczych i decyzyjnych.
Co to jest „golden record” i jak go tworzyć?
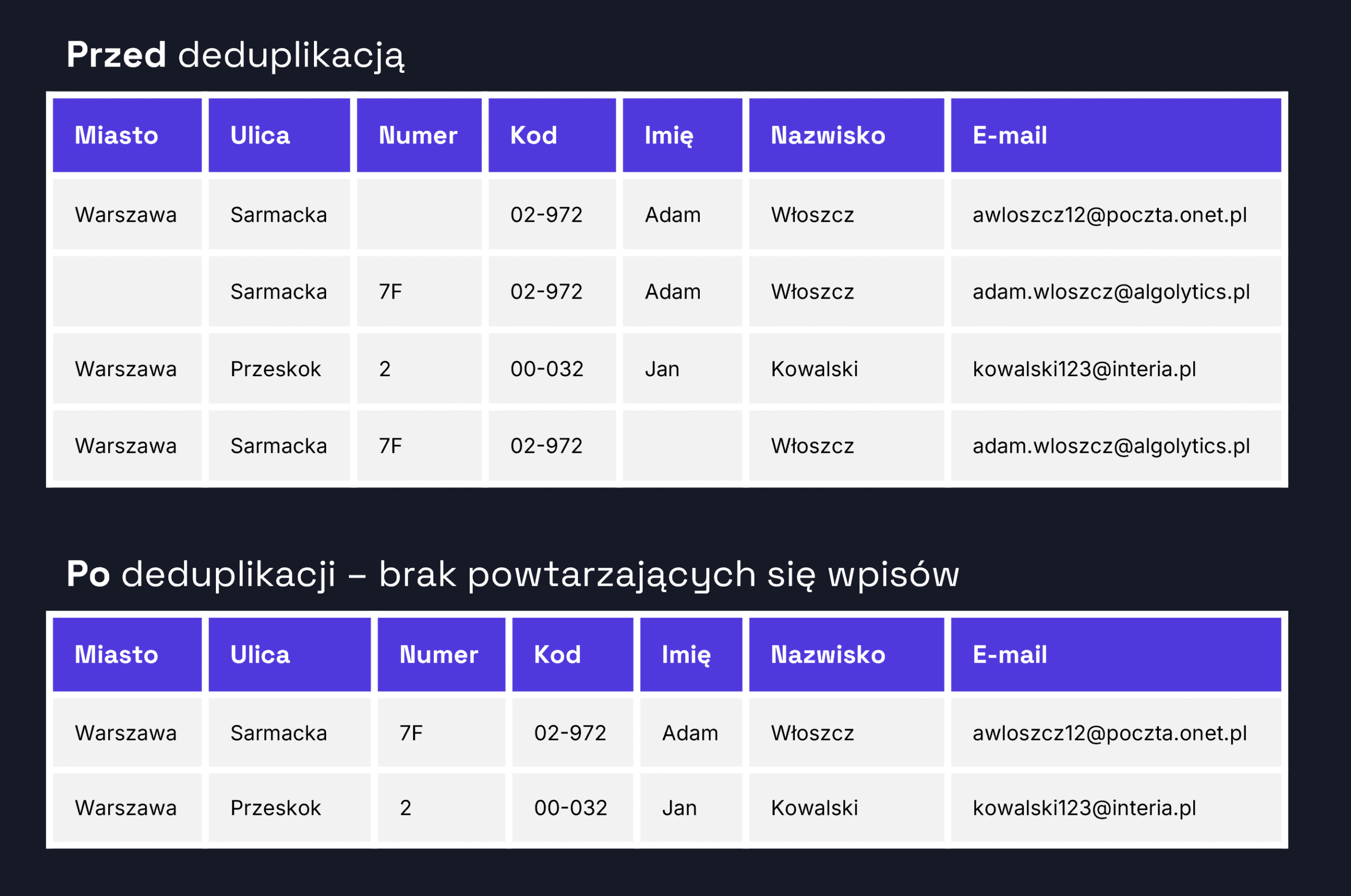
„Golden record” to ujednolicony, najlepszy jakościowo i najbardziej kompletny zapis opisujący konkretny byt – np. klienta, placówkę, punkt sprzedaży. Powstaje on poprzez analizę wielu wariantów zapisu i ich konsolidację do jednej, wzorcowej formy. Proces jego tworzenia wymaga przejścia przez kilka kluczowych etapów:
- Standaryzacja danych – ujednolicenie formatu zapisu danych: nazwy miejscowości, kodów pocztowych, nazw ulic, numerów budynków i mieszkań. Przykład: „ul. Jana Pawła II” → „Jana Pawła II”, „Warszawa-Włochy” → „Warszawa”.
- Normalizacja i czyszczenie – usunięcie błędów (literówek, zbędnych znaków), zamiana skrótów i nieformalnych nazw na oficjalne. Przykład: „wawa”, „WWA”, „warsz” → „Warszawa”.
- Weryfikacja poprawności – sprawdzenie, czy podane dane pasują do danych rejestrowych (np. czy NIP pasuje do nazwy firmy i pozostałych danych, które mamy), czy adresy faktycznie istnieją, czy kod pocztowy pasuje do ulicy, czy numer budynku mieści się w znanym zakresie dla danej ulicy.
- Deduplikacja właściwa – zastosowanie algorytmów porównujących podobieństwo rekordów. Wykorzystywane są metody m.in. Levenshteina, Soundex, porównania n-gramów oraz machine learning.
- Agregacja i tworzenie golden record – na podstawie oceny podobieństwa oraz kompletności danych wybierany lub konstruowany jest jeden, referencyjny rekord. Można też zastosować reguły hierarchii źródeł danych.
Techniki i podejścia do deduplikacji
Deduplikacja danych może być realizowana na wiele sposobów - wybór odpowiedniej techniki zależy od jakości, struktury i celu przetwarzania danych. W praktyce wykorzystuje się zarówno podejścia deterministyczne oparte na jasno zdefiniowanych regułach, jak i bardziej zaawansowane metody probabilistyczne, które lepiej radzą sobie z błędami, literówkami czy brakami w danych.
- Reguły logiczne (rule-based matching): np. porównanie pól miejscowość + ulica + numer budynku. Efektywne, gdy dane są dobrze wystandaryzowane.
- Algorytmy rozmyte (fuzzy matching): wykrywają podobieństwo mimo różnic w zapisie. Stosowane tam, gdzie dane są niekompletne lub zawierają błędy.
- Machine Learning (ML): wykorzystywany do uczenia modeli rozpoznających duplikaty na podstawie zbiorów treningowych. Skalowalne przy dużych zbiorach danych.
- Identyfikatory referencyjne: używanie zewnętrznych identyfikatorów adresów (np. z TERYT) jako wspólnego mianownika porównań.
Jak przygotować dane do deduplikacji?
- Zadbaj o rozbicie danych klienckich i adresowych na oddzielne kolumny: nazwa, imię, nazwisko, numery rejestrowe, miejscowość, kod, ulica, numer budynku itd.
- Usuń zbędne znaki (np. nawiasy, myślniki), popraw oczywiste błędy.
- Zdecyduj o priorytecie danych - np. które źródła traktujesz jako bardziej wiarygodne.
- Przemyśl sposób porównywania: po jakich polach, z jaką wagą, z jakim progiem podobieństwa?
- Przygotuj plan aktualizacji bazy - co zrobić z rekordami zduplikowanymi, czy są łączone, czy jeden nadpisuje drugi?
Deduplikacja w praktyce: kiedy jest szczególnie ważna?
Deduplikacja to nie tylko techniczne usprawnienie — w wielu procesach operacyjnych i analitycznych jej brak może prowadzić do poważnych błędów, nieefektywności lub zbędnych kosztów. W praktyce nabiera szczególnego znaczenia w momentach, gdy dane mają bezpośredni wpływ na decyzje biznesowe lub działania operacyjne.
Mowa tu m.in. o kampaniach marketingowych (gdzie duplikaty mogą skutkować podwójną wysyłką), analizach przestrzennych (w których wielokrotne wystąpienia tych samych punktów zaburzają obraz sytuacji), procesach konsolidacji baz danych (np. po fuzji firm), a także w e-commerce i administracji publicznej.
Prawidłowe uporządkowanie danych to fundament dla rzetelnych analiz, spójnej komunikacji z klientem i skutecznych działań w wielu branżach:
- Mniejszą liczbą błędów i lepszą obsługa klientów,
- Większą efektywność procesów i operacji,
- Przed uruchomieniem kampanii marketingowej (targetowanie, wysyłka katalogów),
- Przed analizą danych przestrzennych (np. identyfikacja białych plam),
- Podczas łączenia baz po fuzji lub przejęciu firmy,
- W e-commerce, by uniknąć wielu kont klientów do jednego adresu,
- W administracji publicznej – dla spójności danych ewidencyjnych i spisów ludności.
Dlaczego warto dbać o unikalność danych?
Deduplikacja danych adresowych to znacznie więcej niż jednorazowe czyszczenie bazy - to fundament zarządzania jakością danych w organizacji. Jej celem nie jest tylko uporządkowanie rekordów, ale budowanie trwałego zaufania do danych jako zasobu - zaufania, że są one spójne, kompletne i gotowe do wykorzystania w procesach biznesowych.
Tworzenie tzw. „golden record” - czyli pojedynczego, najbardziej wiarygodnego zapisu reprezentującego dany podmiot czy klienta - pozwala nie tylko ograniczyć koszty operacyjne (np. poprzez eliminację duplikatów w wysyłkach czy raportach), ale też znacząco podnieść skuteczność kampanii marketingowych, dokładność analiz oraz jakość decyzji strategicznych opartych na danych.
W erze coraz bardziej zautomatyzowanego i zintegrowanego zarządzania informacją, unikalność danych przestaje być opcją - staje się koniecznością.
Deduplikacja jest jedną z funkcjonalności narzędzia Data Quality (standaryzacja, geokodowanie, deduplikacja, weryfikacja, wzbogacanie danych) od Algolytics. Pierwsze 1 000 rekordów możesz przetworzyć za darmo.



