















Zajrzyjmy do wnętrza silnika Scoring.One
W poprzednich częściach tej serii (Część 1, Część 2) pokazaliśmy, że z odpowiednim podejściem technologicznym i właściwymi narzędziami da się tworzyć rozwiązania oparte na machine learningu szybko, skutecznie i niskim kosztem. Porównaliśmy popularne platformy i wyjaśniliśmy, dlaczego to właśnie Algolytics wypada najlepiej. Teraz – zgodnie z zapowiedzią – zapraszamy na spojrzenie „pod maskę” naszej architektury MLOps: silnika Scoring.One.
Od modelu do skalowalnej aplikacji
Większość platform MLOps kończy działanie na etapie trenowania modelu i udostępnienia go przez API lub jako element procesu scoringowego (batch). W Algolytics patrzymy na model jako na jeden z elementów większego systemu. Prawdziwa wartość biznesowa pojawia się dopiero wtedy, gdy cały proces – od pobierania danych, przez inżynierię cech, uruchomienie modelu i logikę decyzyjną, aż po integrację z systemami operacyjnymi – jest ujęty w jednym spójnym i zoptymalizowanym scenariuszu.
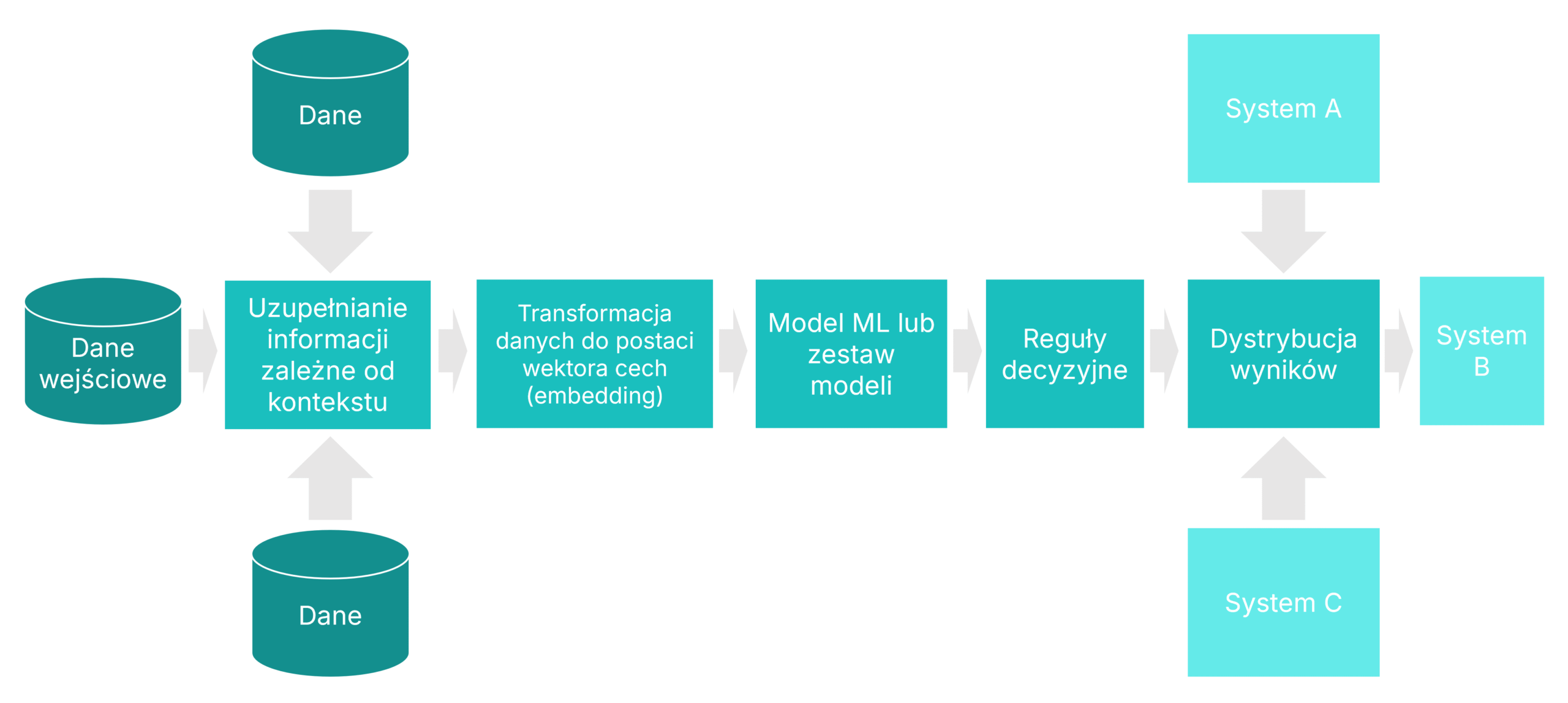
Elementy aplikacji opartej na machine learningu
Scenariusz zaprojektowany w graficznym edytorze platformy staje się w pełni funkcjonalną aplikacją gotową do użycia w środowisku produkcyjnym. Składa się z gotowych do użycia komponentów, takich jak źródła danych, transformacje, modele, reguły decyzyjne, podscenariusze, wywołania API czy operacje równoległe. Co ważne, jego wdrożenie nie wymaga kosztownej ani czasochłonnej implementacji. Jednocześnie zachowuje pełną elastyczność – pozwalając na wykorzystanie własnej logiki napisanej w Pythonie, R lub Groovy.
Co stoi za wydajnością Scoring.One (MLOps)? Zacznijmy od fundamentów – Vert.x
Odpowiedź na pytanie o źródło wydajności i skalowalności Scoring.One (MLOps) prowadzi do technologicznego fundamentu platformy – reaktywnego frameworka Vert.x.
W przeciwieństwie do podejścia opartego na Pythonie, kontenerach Dockera i mikroserwisach, Scoring.One (MLOps) działa jako reaktywna, wielowątkowa aplikacja JVM, która potrafi obsłużyć setki zapytań równolegle, bez konieczności duplikowania środowisk uruchomieniowych. Kluczem jest asynchroniczne, nieblokujące przetwarzanie danych i zdarzeń – dokładnie to, do czego została zaprojektowana architektura Vert.x.
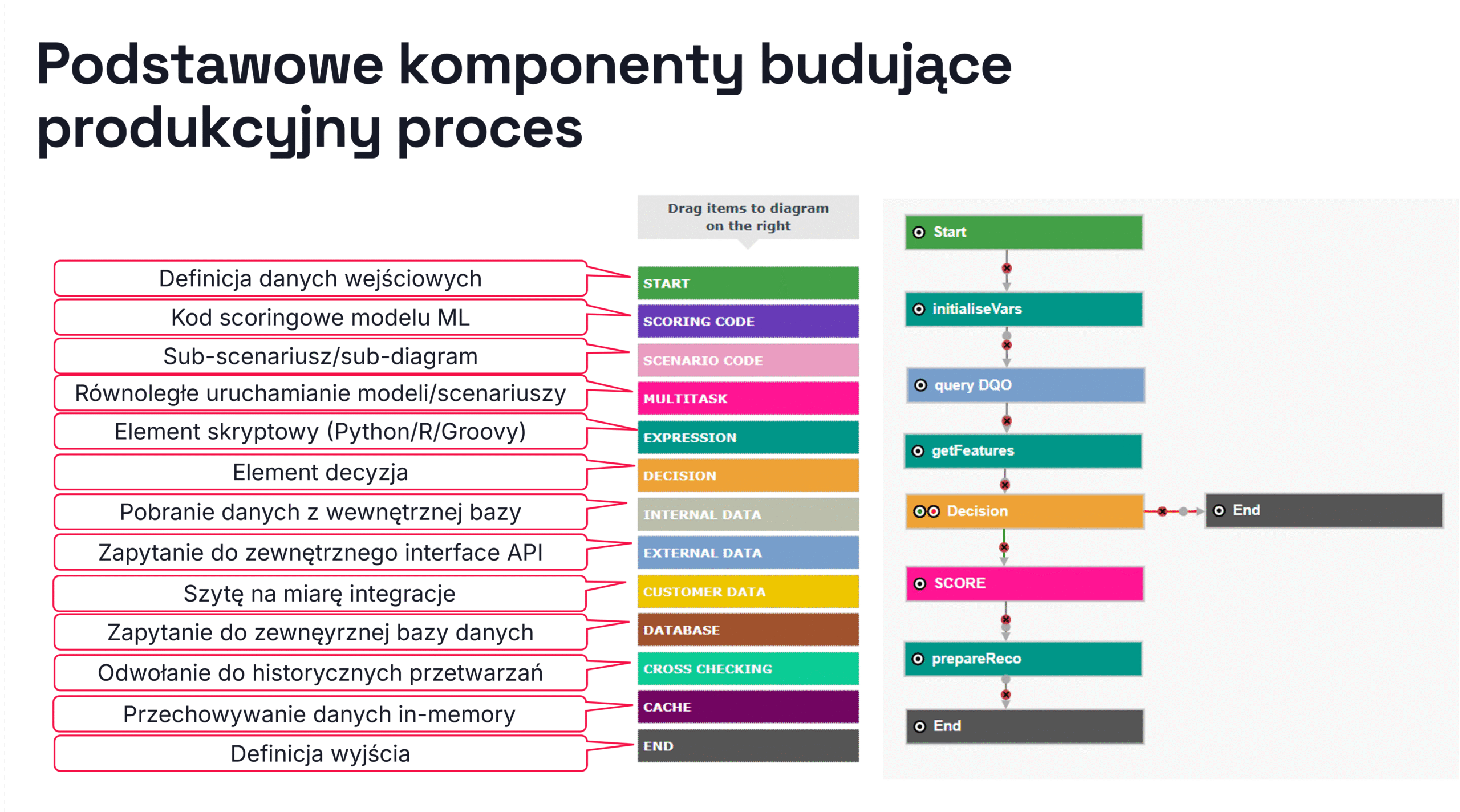
Scenariusz to nie diagram – to produkcyjna aplikacja
Scenariusz scoringowy w naszym edytorze przypomina graficzny workflow złożony z węzłów, połączeń, modeli i warunków logicznych. Ale to nie tylko wizualna reprezentacja – to gotowa do uruchomienia aplikacja, w której każdy element scenariusza działa jako niezależny procesor zdarzeń osadzony w środowisku Vert.x.

Oparty na zdarzeniach, nieblokujący, działający równolegle
Zapytanie scoringowe jest traktowane jako zdarzenie, które przechodzi przez kolejne etapy przetwarzania: pobieranie danych, przygotowanie cech, modele ML, reguły biznesowe i systemy wyjściowe. Każdy z tych etapów działa:
- nieblokująco – nie czeka na zakończenie innych operacji,
- asynchronicznie – korzysta z własnej puli wątków,
- równolegle – umożliwiając jednoczesną obsługę wielu zapytań.
Dzięki temu pojedyncza instancja Scoring.One (MLOps) może skalować się pionowo i efektywnie obsługiwać duże obciążenia – bez konieczności duplikowania kontenerów w ramach skalowania poziomego.
Jednocześnie Scoring.One (MLOps) wspiera także skalowanie poziome – pozwalając na uruchamianie dodatkowych procesów JVM na wielu maszynach. Tworzą one rozproszony klaster połączony wspólną szyną zdarzeń i działający jako jeden system. Wspólna pula verticles dynamicznie równoważy obciążenie przetwarzania.
Eliminacja klasycznych wąskich gardeł
Tradycyjne platformy MLOps często napotykają na kilka ograniczeń:
- każdy model działa w osobnym kontenerze (co oznacza większe zużycie pamięci i duplikację środowisk),
- komunikacja między komponentami odbywa się przez sieć, co generuje znaczne opóźnienia,
- Python i GIL uniemożliwiają prawdziwe przetwarzanie wielowątkowe.
Scoring.One pokonuje te ograniczenia, uruchamiając cały proces w jednej, zoptymalizowanej instancji JVM. Dzięki temu oferuje znacznie prostsze i bardziej efektywne środowisko w porównaniu do tradycyjnego zestawu Docker + Python + REST + MLflow.
Odporność, monitoring i przejrzystość
Każdy komponent działa niezależnie. W przypadku błędu (np. brakujących danych czy błędnego adresu) problem jest obsługiwany lokalnie, bez przerywania całego scenariusza. Co więcej:
- Wszystkie zdarzenia są logowane i archiwizowane.
- Scenariusze mają pełną historię realizacji,
- Każdy etap można uruchomić i debugować osobno.
Wielojęzyczna i elastyczna integracja
W jednym scenariuszu możesz łączyć modele i komponenty napisane w różnych językach:
- Python, R, Java, Groovy,
- a także PMML oraz kod generowany przez system AutoML Algolytics.
Nie ma potrzeby tworzenia mikroserwisów, osobnych kontenerów czy skomplikowanych pipeline’ów CI/CD. Większość integracji realizowana jest za pomocą gotowych komponentów, co eliminuje konieczność pisania kodu.
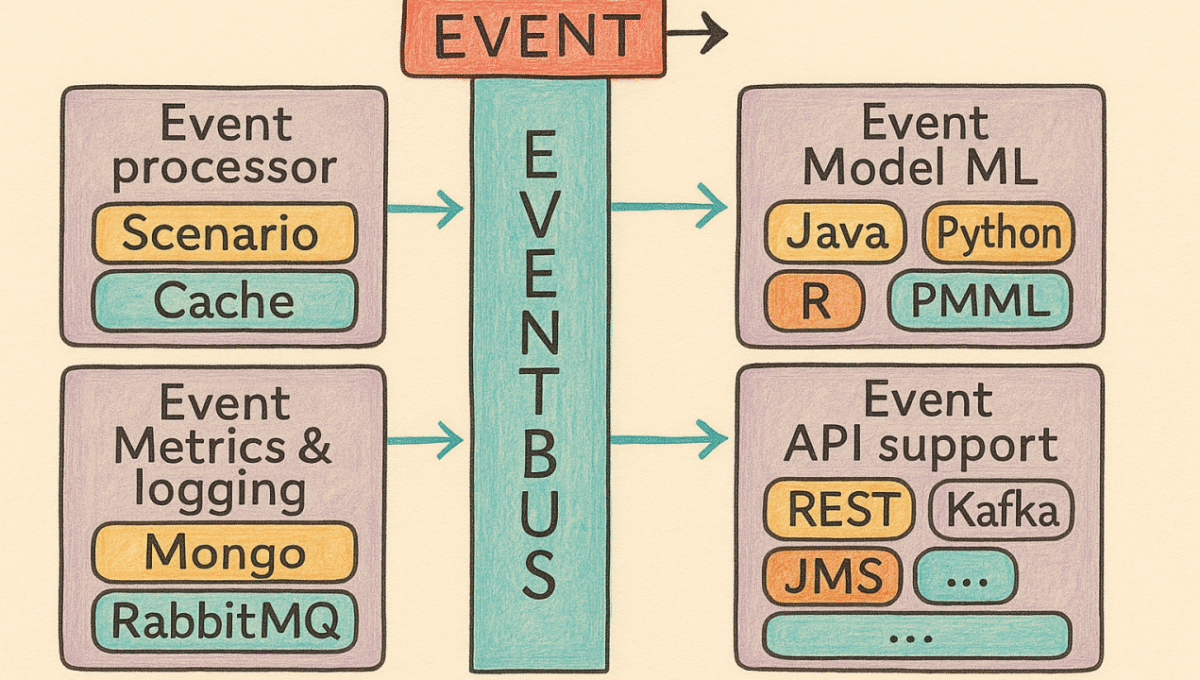
Event Bus – podstawowy mechanizm komunikacji aplikacji
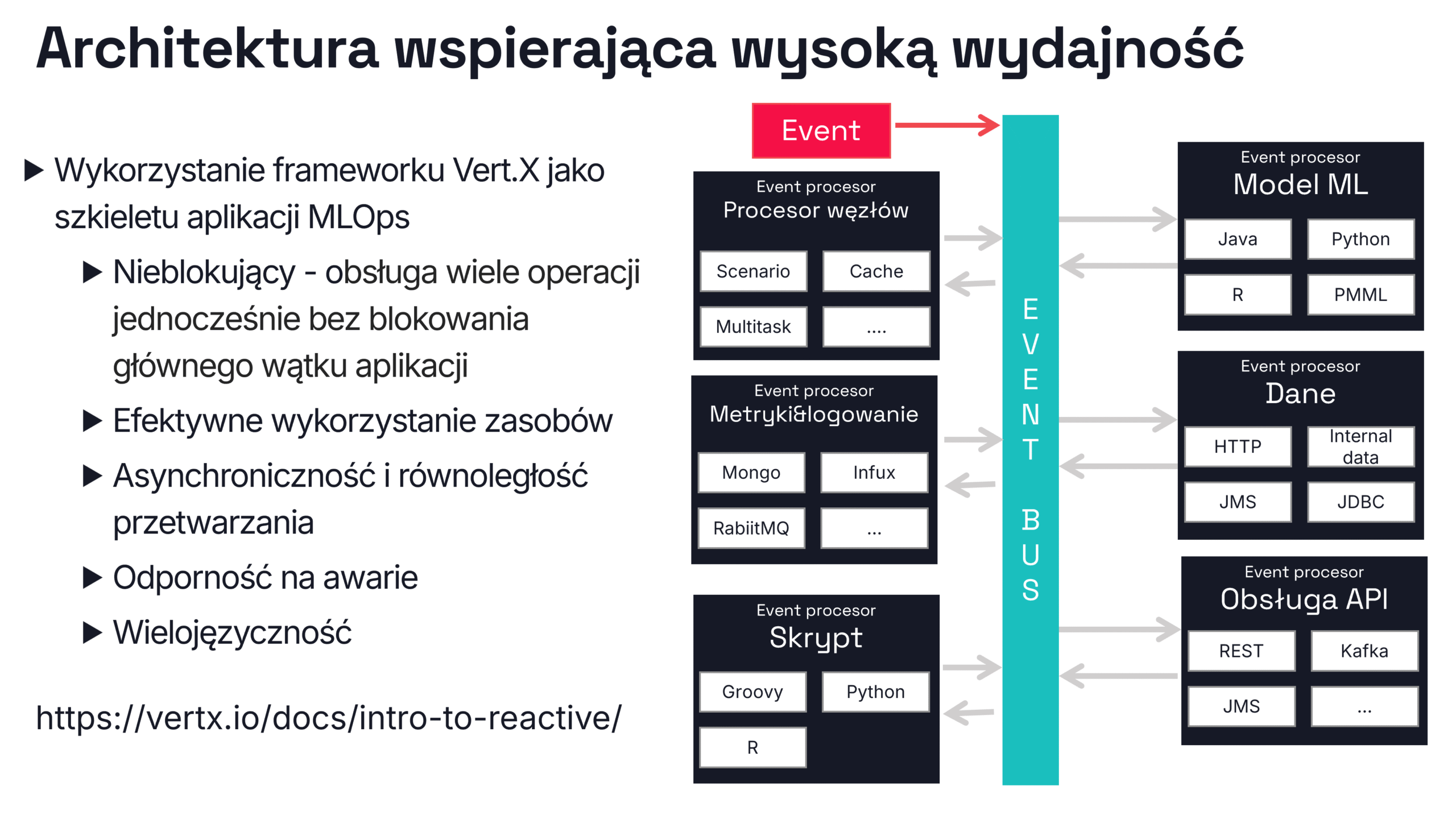
Komunikacja między komponentami Scoring.One (MLOps) odbywa się za pośrednictwem wewnętrznej szyny zdarzeń – reaktywnego busa danych. Każdy element scenariusza (np. transformacja, model, wywołanie API) to osobny verticle reagujący na określony typ zdarzenia i przekazujący wynik do kolejnego komponentu.
Ta architektura pozwala na:
- Cały przepływ jest asynchroniczny i nieblokujący,
- Aplikacja może jednocześnie obsługiwać wiele zapytań, nie tracąc na responsywności,
- System automatycznie radzi sobie z przeciążeniami (mechanizmy back-pressure),
- Każdy komponent może działać w innym języku programowania (np. Java, Python, R), co zapewnia pełną elastyczność technologiczną.
Grupy verticles i ich funkcje w Scoring.One (MLOps)
Architektura Scoring.One składa się ze specjalistycznych verticles, zorganizowanych w funkcjonalne grupy:
- Model processors – uruchamiają modele ML napisane jako klasy Java, skrypty Python lub obiekty PMML/ONNX.
- Script processors – pozwalają na wykonanie własnej logiki w językach skryptowych (Python, Groovy, R).
- API processors – integrują się z systemami zewnętrznymi (REST, Kafka, SOAP) za pomocą asynchronicznego I/O.
- Data processors – pobierają i zapisują dane z/do baz danych, kolejek i cache, wykorzystując protokoły JDBC, HTTP i inne.
- Control processors – odpowiadają za kontrolę przepływu: warunki logiczne, rozgałęzienia, multitasking, wywołania podscenariuszy.
- Monitoring & logging processors – zapewniają logowanie i metryki wydajności w czasie rzeczywistym (Mongo, Influx, RabbitMQ).
Każdy verticle działa niezależnie i jest odporny na błędy dzięki izolacji – to oznacza, że awaria jednego komponentu nie wpływa na działanie całego systemu.
Studium przypadku: ocena przedsiębiorcy
Skuteczność tej architektury najlepiej widać na przykładzie rzeczywistych zastosowań, takich jak złożony proces oceny przedsiębiorców wdrożony przez czołowe instytucje finansowe i ubezpieczeniowe.
Złożoność danych i przetwarzania
Choć na pierwszy rzut oka scoring przedsiębiorcy wydaje się prosty („Czy klient jest wiarygodny?”), w praktyce wymaga:
- pozyskania danych z wielu publicznych źródeł (np. KRS, CEIDG, GUS, CRBR, SUDOP, MSIG), często za pomocą crawlerów WWW,
- przetwarzania nieustrukturyzowanych dokumentów (np. plików rejestrowych, PDF, XML),
- wykorzystania zintegrowanych modeli LLM do wydobywania danych z tekstu (np. analiza plików rejestrowych),
- pobierania danych z baz wewnętrznych i feature store’ów (np. historia płatności, sygnały z systemu transakcyjnego),
- uruchamiania kilku modeli ML i zestawu reguł eksperckich,
- dostarczenia wyniku scoringu do systemu decyzyjnego w czasie rzeczywistym.
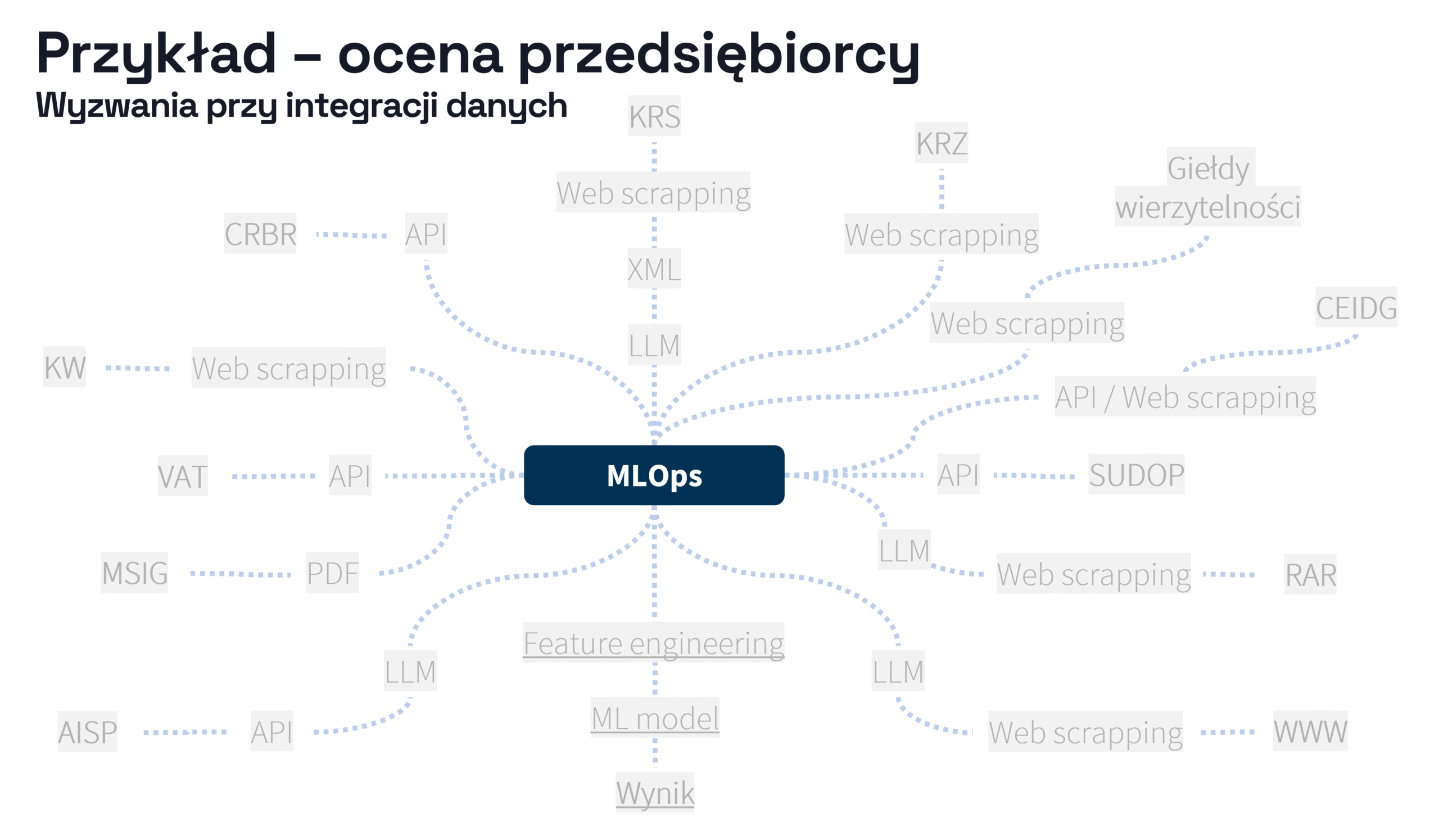
W sumie mamy do czynienia z setkami interakcji systemowych, warunkowych zależności, asynchronicznych zapytań, transformacji danych oraz decyzji logicznych. Implementacja takiego rozwiązania w klasycznym podejściu mikroserwisowym oznacza tygodnie pracy i wiele potencjalnych punktów awarii.
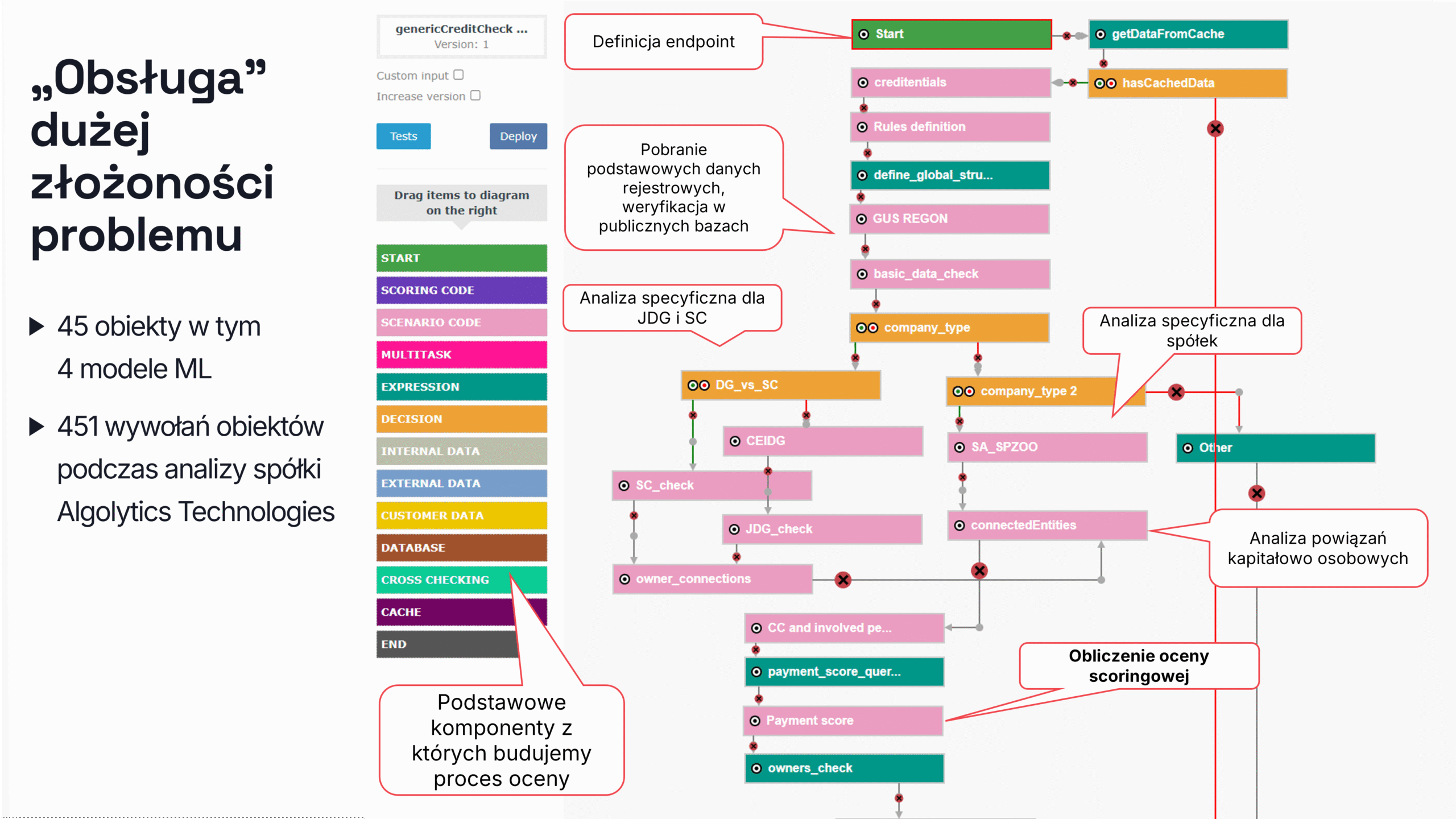
Jeden scenariusz – złożony proces
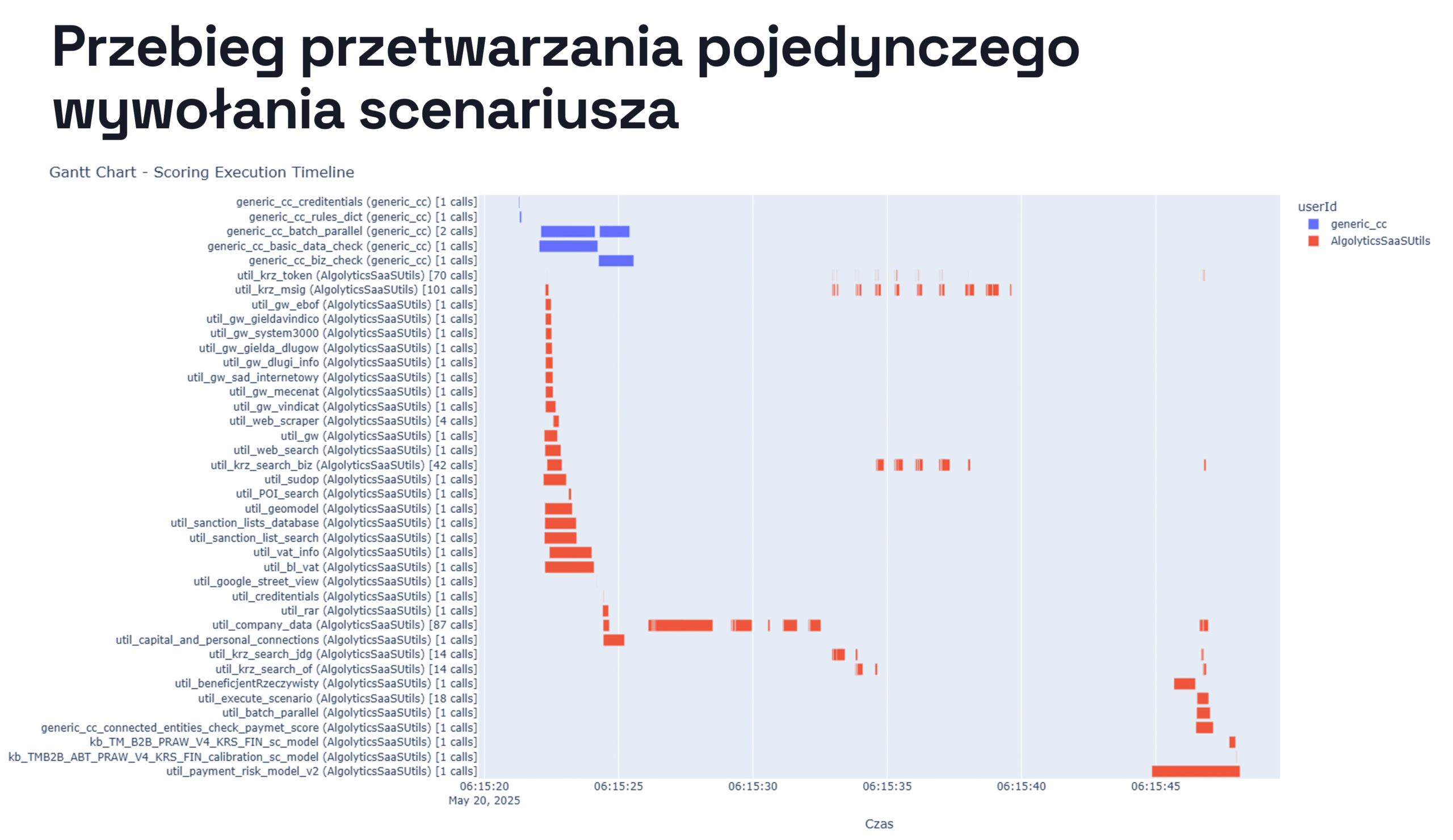
W Scoring.One (MLOps) cały proces jest zamknięty w jednym scenariuszu low-code, który korzysta z kilkudziesięciu podscenariuszy i setek komponentów. Podczas analizy przeprowadzonej przez Algolytics Technologies system wykonał 707 wywołań do różnych komponentów i modeli, w tym podmiotów powiązanych oraz osób, których dane wzbogaciły cechy wejściowe.
Dzięki asynchronicznemu i równoległemu przetwarzaniu cały proces zajmuje mniej niż minutę. Co więcej, platforma pozwala na przeprowadzanie wielu takich ocen jednocześnie.
Podsumowanie
W tej części pokazaliśmy, że wyjątkowa wydajność i efektywność kosztowa Scoring.One (MLOps) wynikają ze świadomie zaprojektowanej, reaktywnej architektury opartej na Vert.x. To fundament, który sprawia, że nasze scenariusze scoringowe są nie tylko bardzo wydajne, ale też elastyczne, odporne i gotowe do wdrożenia na produkcji. To rozwiązanie, które realnie wspiera zespoły data science i IT — przyspieszając wdrożenia, upraszczając integracje i obniżając koszty infrastruktury.



