Transformacje odgrywają dużą rolę w przetwarzaniu danych. Bardzo często można spotkać się z sytuacją, kiedy zestaw danych posiada nieodpowiedni format lub zawiera nieprawidłowe dane, które uniemożliwiają użycie danych lub ich analizę. W sytuacji, kiedy konieczne jest konwertowanie danych z jednego formatu, może zostać użyta transformacja danych. W kolejnych częściach rozdziału omówione zostały wbudowane transformacje:
- binaryzacja
- normalizacja
- wartości odstające
- analiza głównych składowych (PCA)
- zastępowanie pustych wartości (replace missing)
- standaryzacja
- weight of evidence
Każda transformacja definiowana jest przez zestaw parametrów. Niektóre z nich są wspólne dla wszystkich transformacji, a inne zależą od typu transformacji. Unikalne parametry dla podstawowych transformacji opisane są w odpowiednim rozdziale. Tabela poniżej zawiera opis wspólnych parametrów.
Tabela 4.1. Użycie zestawu atrybutów
| Wartość | Opis |
|---|---|
| auto | Kolumna transformowana będzie według ustawień domyślnych (np. zastąpienie pustych wartości na mean/modal lub zmiennych numerical/categorical) |
| copy | Kolumna zostanie skopiowane bez żadnych zmian. |
| drop | Kolumna zostanie pominięta podczas transformacji. |
| transform | Kolumna zostanie transformowana zgodnie z ustawieniami użytkownika. |
W systemie Advanced Miner istnieją dwa sposoby użycia transformacji. Transformacja może być utworzona bezpośrednio przy pomocy linku: TransformationBuildTask lub pośrednio jako zautomatyzowany element procesu budowy modelu (Automatic transformacja danych). W pierwszym przypadku użytkownik wybiera typ transformacji, który może być zastosowany dla zestawu danych. W drugim przypadku system wykonuje transformację, która jest niezbędna dla zadanego algorytmu do pracy nad modelowaniem wybranego zestawu danych.
Binaryzacja zmienia wartości nominalne w n wartości binarne, gdzie n jest liczbą możliwych wartości zmiennej nominalnej. Wartości NULL kopiowane są bez zmian.
Transformacja Binaryzacji posiada następujące ustawienia:
Tabela 4.2. Ustawienia Binaryzacji
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Default Binarized Values | Dla unipolar kolumna binaryzowana przyjmuje wartości 0 oraz 1, dla bipolar -1 oraz 1. | unipolar / bipolar | unipolar |
| Max Values Count | Jeśli liczba różnych wartości atrybutu jest większa od 'Max Values Count' atrybut nie będzie binaryzowany. | Integer values | 100 |
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Podobnie jak w przypadku użycia zestawu atrybutów użytkownik może określić dodatkowe parametry transformacji dla każdej zmiennej.
Tabela 4.3. Binaryzacja - Atrybuty Spersonalizowane
| Nazwa | Opis |
|---|---|
| Variable Name | Nazwy zmiennych |
| Redundant |
Wybór zmiennej dla zmiennej binaryzowanej:
|
| Binarizedvalues |
Wybór zbioru wartości dla zmiennych binarnych:
|
Normalizacja używana jest do transformacji tabeli wejściowej, w sposób że po transformacji, wartości dla zadanej kolumny są w przedziale <MinValue, MaxValue>. Normalizacja transformuje dane według następującej formuły:
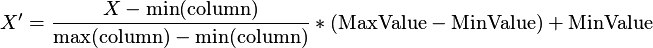
Jeżeli wszystkie wartości w kolumnie transformowanej są jednakowe, wtedy wszystkie wartości w kolumnie wyjściowej będą równe z
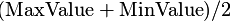 .
Wartości Null nie są zmieniane.
.
Wartości Null nie są zmieniane.
Transformacja Normalizacji posiada następujące ustawienia:
Tabela 4.4. Ustawienia Normalizacji
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Max Value | Prawy koniec przedziału targetu. | Liczba rzeczywista (większa niż wartość minimalna (Min Value)) | 1.0 |
| Min Value | Lewy koniec przedziału targetu. | Liczba rzeczywista (mniejsza niż wartość maksymalna (Max Value)) | 0.0 |
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
W procesach data miningu oraz analizach danych nie wszystkie anomalie występują z powodu niezadeklarowanych lub brakujących wartości. Innym powodem anomalii jest obecność wartości odstających (outliers) – których obserwacje są skrajnie odstające od reszty próbki danych. Rzadkie przypadki anomalii są typowym skutkiem istnienia wartości odstających. Wartości odstające mogą być także określone jako skrajne obserwacje, które z pewnych i prawidłowych powodów nie mieszczą się w zakresie innych wartości danych. Transformacja wartości odstających ma na celu poprawę normalności przez zastąpienie wartości odstających wartościami odpowiednimi.
Transformacja Wartości odstających posiada następujące ustawienia:
Tabela 4.5. Wartości odstające
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| lowerPercent | Wartość procentowa obserwacji do transformacji z niższego przedziału. | dodatnia wartość całkowita z przedziału (0-100) | 5 |
| upperPercent | Wartość procentowa obserwacji do transformacji z wyższego przedziału. | dodatnia wartość całkowita z przedziału (0-100) | 95 |
| minValuesCount | Minimalna liczba różnych wartości dla transformacji, na którą oddziałowują. | wartość całkowita | 10 |
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Analiza głównych składowych (PCA) jest procedurą matematyczną, która transformuje ilość (możliwych) skorelowanych zmiennych w mniejszą ilościowo wartość nieskorelowanych zmiennych nazywanych głównymi składowymi. Analiza głównych składowych została przedstawiona przez Karla Pearson’a w roku 1901, później rozwinięta przez kilku innych autorów (zobacz Hotelling (1933)). Doskonałe statystyczne omówienie głównych składowych można znaleźć u Morrison’a (1976), oraz Mardia, Kent, i Bibby (1979). Obszerny opis PCA oraz sprawozdanie można znaleźć u Jolliffe (2002). Analiza głównych składowych użyteczna jest przy podsumowaniu danych oraz wykryciu zależności liniowych. Celem analizy głównych składowych jest zredukowanie rozmiaru (liczby zmiennych) zestawu danych jednocześnie zachowując większość oryginalnych zmiennych w danych. Pierwszy element głównych składowych odpowiada za zmienność danych jak to tylko możliwe, a każda kolejna składowa odpowiada za zmienność pozostałych danych jak to tylko możliwe. Transformacja PCA dokonuje analizy głównych składowych na wybranym zestawie danych. Analiza głównych składowych wyjaśnienia struktury wariancji –kowariancji wielowymiarowego wektora za pomocą kilku liniowych kombinacji oryginalnych zmiennych głównych składowych. Rozpatrując 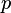 -wymiarowy wektor losowy
-wymiarowy wektor losowy
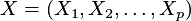 .
.
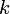 głównych składowych (dla
głównych składowych (dla
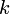 nie większych niż
nie większych niż
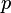 ) z
) z
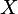 zmiennymi losowymi
zmiennymi losowymi
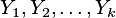 definiowanymi przez wzory
definiowanymi przez wzory
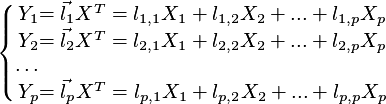
Dla danego 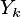 współczynniki wektorów
współczynniki wektorów 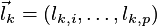 dobierane są w sposób aby
dobierane są w sposób aby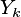 miał największą wariancję dla poniższych warunków:
miał największą wariancję dla poniższych warunków:
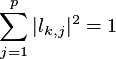
oraz
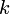 -ta Główna Składowa jest kombinacją liniową
-ta Główna Składowa jest kombinacją liniową
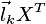 która maksymalizuje
która maksymalizuje
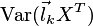 oraz
oraz
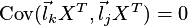 .
Istnieje dokładnie
.
Istnieje dokładnie
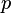 takich liniowych kombinacji. Pierwsze kilka z nich objaśnia większość wariancji w danych oryginalnych, zamiast pracy z wszystkimi zmiennymi oryginalnymi.
takich liniowych kombinacji. Pierwsze kilka z nich objaśnia większość wariancji w danych oryginalnych, zamiast pracy z wszystkimi zmiennymi oryginalnymi.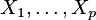 Domyślnie jedno wykonanie PCA może być wystarczające, następnie należy użyć pierwszych dwóch lub trzech głównych składowych w kolejnych krokach analizy. Kryterium Kaiser’a może być także użyte do przetrzymywania tylko głównych składowych z wartością własną macierzy większą niż jeden. Zostało to zaproponowane przez Kaiser’a (1960) i jest to prawdopodobnie najbardziej popularne kryterium tego typu.
Domyślnie jedno wykonanie PCA może być wystarczające, następnie należy użyć pierwszych dwóch lub trzech głównych składowych w kolejnych krokach analizy. Kryterium Kaiser’a może być także użyte do przetrzymywania tylko głównych składowych z wartością własną macierzy większą niż jeden. Zostało to zaproponowane przez Kaiser’a (1960) i jest to prawdopodobnie najbardziej popularne kryterium tego typu.
Transformacja PCA posiada następujące ustawienia:
Tabela 4.6. Ustawienia PCA
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Numer Składowej | Gdy kryteria ustawione są na KAISER, parametr ten jest ignorowany Gdy kryteria ustawione są na NUMBER, opisuje to liczbę głównych składowych. | liczby całkowite | 1 |
| Kryterium | Określa ile składowych zostało wybranych. kaiser używa samo obieralną liczbę głównych składowych. Za pomocą number użytkownik może określić liczbę składowych ręcznie. | number / kaiser | number |
| Normalizacja | Gdy ustawione TRUE, normalizacja wykonywana jest bez pominięcia priorytetów głównych składowych, FALSE w innym przypadku. | TRUE / FALSE | FALSE |
| Liberal Mode | Gdy TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Transformacja ta zastępuje lub usuwa wartości null w zestawie danych. Niektóre algorytmy nie działają z wartościami null i w takich przypadkach transformacja jest wyjątkowo użyteczna.
Notatka
W przypadku zmiennych kategorycznych i uporządkowanych zaginione/puste wartości zastępowane są przez najczęściej występującą wartośćZastępowanie pustych wartości (replace missing) posiada następujące ustawienia:
Tabela 4.7. Ustawienia zastępowania pustych wartości (replace missing)
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Zastępowanie Kategorycznych | Wartość, która zastąpi puste wartości zmiennych kategorycznych | mean/median/distirbutionBased/modal/custom | modal |
| Procent dolnego odcięcia | Procentowa wartość obserwacji z dolnego zakresu traktowana jako jeden interwał w bazowym procesie dystrybucji. | Dodatnie liczby całkowite z zakresu(0-100) | 0 |
| Procent górnego odcięcia | Procentowa wartość obserwacji z górnego zakresu traktowana jako jeden interwał w bazowym procesie dystrybucji. | Dodatnie liczby całkowite z zakresu(0-100) | 100 |
| Zastępowanie Numerycznych | Wartość, która zastąpi puste wartości zmiennych numerycznych | mean/median/distirbutionBased/modal/custom | mean |
| Zastępowanie Uporządkowanych | Wartość, która zastąpi puste wartości zmiennych uporządkowanych | mean/median/distirbutionBased/modal/custom | modal |
| Ziarno | Ziarno generatora liczb losowych używanych w przypadku bazowej dystrybucji zastępowania wartości pustych (distributionBased). | wartości całkowite | null |
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Tak jak w przypadku użycia zestawu atrybutów użytkownik może ustawić dodatkowe parametry transformacji dla każdej zmiennej.
Tabela 4.8. Zastępowanie pustych wartości (replace missing) - Atrybuty
| Nazwa | Opis |
|---|---|
| Name | Nazwa zmiennej |
| Replace Type | Sposób w jaki puste wartości będą zastępowane: mean/median/distirbutionBased/modal/custom. |
| Custom Value | Wybrany przez użytkownika sposób w jaki będą zastępowane puste wartości (w przypadku wybrania typu 'custom'). |
Standaryzacja oznacza odjęcie dla każdego wpisu w kolumnie (dla typów liczbowych) wartości średniej z wszystkich wpisów tej kolumny, następnie podzielenie wyniku przez odchylenie standardowe tej kolumny. Wartości null pozostaną niezmienione. Warunkiem koniecznym dla tej transformacji jest, aby odchylenie standardowe nie było zerem. Transformacja standaryzacji odbywa się na podstawie wzoru:
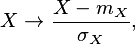
gdzie
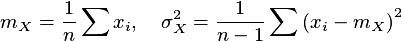
Po standaryzacji każda kolumna posiada swoją wartość średnią równą 0 oraz odchylenie standardowe równe 1.
Transformacja standaryzacji posiada następujące ustawienia:
Tabela 4.9. Ustawienia Standaryzacji
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Weight of evidence ocenia który zakres obserwowanych cech charakterystycznych danych dodać lub odjąć z impaktu dowodu. Weight of evidence może być wyliczona w następujący sposób:
Każdy atrybut 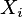 (gdzie
(gdzie 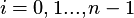 oraz
oraz 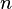 jest liczbą atrybutów), jest podzielony przez algorytm
na
jest liczbą atrybutów), jest podzielony przez algorytm
na
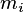 poziomów.
Niech
poziomów.
Niech 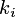 oznacza liczbę porządkową jednego z poziomu atrybutu
oznacza liczbę porządkową jednego z poziomu atrybutu
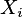 ,
,
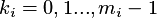 .
.
Po pierwsze, następujący parametr jest definiowany:
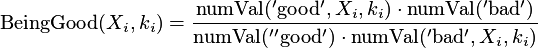
gdzie
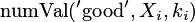 jest liczbą wartości targetu zbliżoną do 'dobrych' w
jest liczbą wartości targetu zbliżoną do 'dobrych' w
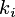 -tym
poziomie atrybutu
-tym
poziomie atrybutu
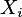 oraz
oraz
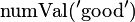 jest liczbą wartości targetu zbliżoną do 'dobrych' w całym zestawie danych.
Współczynnik dla 'złych' definiowany jest analogicznie.
jest liczbą wartości targetu zbliżoną do 'dobrych' w całym zestawie danych.
Współczynnik dla 'złych' definiowany jest analogicznie.
Weight of evidence jest wyliczane jako:
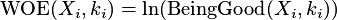
Weight of evidence posiada następujące ustawienia:
Tabela 4.10. Ustawienia Weight of evidence
| Nazwa | Opis | Dopuszczalne wartości | Wartość domyślna |
|---|---|---|---|
| Max Values Count | Jeżeli liczba różnych wartości atrybutu jest większa od 'Max Values Count', atrybut nie zostanie zbinaryzowany. | liczba całkowita | 100 |
| Positive Target Value | Nazwa dodatniej kategorii targetu. | dowolna wartość | |
| Target Attribute | Nazwa atrybutu targetu. | dowolna wartość | null |
| Liberal Mode | Jeśli TRUE, preferowane jest wykonanie ‘liberalne’ (nie zatrzyma się podczas drobnych błędów), w innym przypadku: FALSE. | TRUE / FALSE | TRUE |
Podczas procesu budowania transformacji, następujące obiekty MR są w użyciu:
- PhysicalData - obiekt opisujący użyte dane do budowania transformacji
- TransformationSettings - obiekt przechowujący szczegółowe ustawienia jak transformacja jest budowana
- TransformationBuildTask - obiekt kontrolujący cały proces budowania transformacji
Zadanie budujące transformację składa się z następujących kroków:
- krok 1: tworzenie obiektu PhysicalData dla zestawu danych użytego do budowy transformacji
- krok 2: wybór TransformationSettings z podstawowych
typów
- krok 2a: dodanie obiektów LogicalData odpowiednich do stworzenia obiektu PhysicalData
- krok 2b:ustawienie AttributeUsageSet
- krok 2c: ustawienie pozostałych parametrów
- krok 3: wybór zadania: TransformationBuildTask
- krok 3a: dodanie PhysicalData
- krok 3b: dodanie TransformationSettings
- krok 3c: ustawienie nazwy nowej transformacji
- krok 4: wykonanie zadania
Po wykonaniu zadania budującego transformację pojawi się nowy obiekt transformation w Repozytorium Metadanych, który może być użyty później do transformacji danych TransformationApplyTask
Podczas procesu stosowania transformacji, następujące obiekty MR są w użyciu:
- PhysicalData - obiekt opisujący użyte dane do stosowania transformacji
- TransformationApplyTask - obiekt kontrolujący cały proces stosowania transformacji
- Transformation - wynik procesu budowania transformacji
Zadanie stosowania transformacji składa się z następujących kroków:
- krok 1: tworzenie obiektu PhysicalData dla danych, na których transformacja będzie stosowana
- krok 2: tworzenie obiektu PhysicalData dla danych wynikowych transformacji
- krok 3: wybór zadania: TransformationApplyTask
- krok 3a: dodanie danych źródłowych - obiekt PhysicalData danych do transformacji
- krok 3b: dodanie danych targetu - obiekt PhysicalData danych dla wyniku transformacji
- krok 3c: dodanie transformacji do zastosowania
- krok 3d: Specyfikacja mapowania bezpośredniego – które zmienne z danych wejściowych powinny być kopiowane bez jakichkolwiek zmian do zestawu danych wyjściowych
- krok 4: wykonanie zadania
Po wykonaniu Zadania Stosowania Transformacji powstanie nowa tabela bazy danych, która zawiera dane transformowane. Nazwa wynikowej tabeli jest dziedziczona z nazwy targetu PhysicalDate.
Większość algorytmów data mining zaimplementowanych w AdvancedMiner wspiera opcję Automatic Data Transformation, która jest szybszym sposobem transformacji zmiennych podczas zadania budowania modelu. Za pomocą tej opcji transformacja danych odbywa się w tzw. „locie” z użyciem ustawień ręcznych transformation parameters. Ustawienia ręczne możliwe są przez użycie functionSettings | algorithmSettings | transformationSettings | internalTransformationsSettings (poprzez podwójne kliknięcie na nazwie transformacji oraz okno Properties). Transformacja jest wykonywana automatycznie, tuż przed krokiem estymacji modelu, jednakże transformowane dane nie są zapisywane w bazie danych.
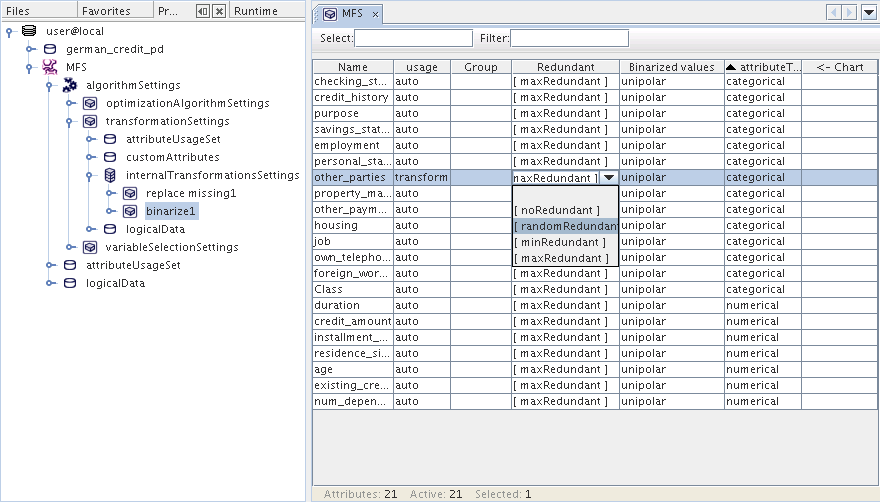
Skrypt poniżej pokazuje jak pracować z zadaniami transformacji
Przykład 4.40. A sample transformation script
table 'data_sample':
a b c
2 'a5' -4
10 'abcde5' 8
pd = PhysicalData('data_sample')
save('pd', pd)
ld = LogicalData(pd)
save('ld', ld)
# Create the TransformationSettings object
transformationSettings = BinarizeSettings() # or StandardizeSetting, NormalizeSettings etc.
# Set transformation parameters
transformationSettings.setLogicalData(ld)
transformationSettings.getAttributeUsageSet().getAttribute('a').setUsage\
(TransformationUsageOption.drop)
transformationSettings.getAttributeUsageSet().getAttribute('b').setUsage\
(TransformationUsageOption.copy)
transformationSettings.getAttributeUsageSet().getAttribute('c').setUsage\
(TransformationUsageOption.transform)
transformationSettings.allNoRedundant()
# and save it
save('transformation_settings', transformationSettings)
# Create TransformationBuildTask
bt = TransformationBuildTask()
# Set the TransformationBuildTask parameters
bt.transformationName='my_transformation'
bt.physicalDataName='pd'
bt.transformationSettingsName='transformation_settings'
# and save the TransformationBuildTask
save('transformation_bt', bt)
# and execute the build task
execute('transformation_bt')
# Create TransformationApplyTask
tat=TransformationApplyTask()
# if the table exists it will be replaced
tat.replaceExistingData = TRUE
# Add the transformation
tat.setTransformationName('my_transformation')
# set Source
tat.setSourceDataName('pd')
# Create PhysicalData for the TransformationApplyTask Target
save('pd_out',PhysicalData('output_table_name'))
# set the Target
tat.setTargetDataName('pd_out')
# Save TransformationApplyTask
save('transformation_at', tat)
# Run the task
execute('transformation_at')
print 'See the result in binarize_out table...'
data = tableRead('output_table_name')
# Print the output table
for i in range(len(data)):
for j in range(len(data[i])):
print data[i][j],
print
Output:
See the result in binarize_out table...
b __c___4_0 __c__8_0
a5 1.0 0.0
abcde5 0.0 1.0
Przykład 4.41. Weight of evidence transformation :
table 'data_sample':
id sex target
1 'woman' 'good'
2 'man' 'bad'
3 'man' 'good'
4 'woman' 'good'
5 'man' 'good'
6 'woman' 'good'
7 'woman' 'bad'
pd = PhysicalData('data_sample')
save('pd', pd)
ld = LogicalData(pd)
save('ld', ld)
transformationSettings = WeightOfEvidenceSettings()
transformationSettings.setTarget('target')
transformationSettings.setPositiveTargetValue('good')
transformationSettings.setLogicalData(ld)
transformationSettings.getAttributeUsageSet().getAttribute('id').setUsage(TransformationUsageOption.copy)
transformationSettings.getAttributeUsageSet().getAttribute('target').setUsage(TransformationUsageOption.copy)
transformationSettings.getAttributeUsageSet().getAttribute('sex').setUsage(TransformationUsageOption.transform)
save('transformation_settings', transformationSettings)
bt = TransformationBuildTask()
bt.transformationName='my_transformation'
bt.physicalDataName='pd'
bt.transformationSettingsName='transformation_settings'
save('transformation_bt', bt)
execute('transformation_bt')
tat=TransformationApplyTask()
tat.replaceExistingData=TRUE
tat.setTransformationName('my_transformation')
source = DataObjectSet('data_sample')
tat.setSourceDataName('pd')
save('pd_out',PhysicalData('output_table_name'))
tat.setTargetDataName('pd_out')
save('transformation_at', tat)
execute('transformation_at')
print 'Transformed table:'
sql res:
select * from output_table_name
print res
# Exmaple - caluculating weight of evidence
good_target = 0.0
bad_target = 0.0
good_target_in_man = 0.0
bad_target_in_man = 0.0
good_target_in_woman = 0.0
bad_target_in_woman = 0.0
trans None <- 'data_sample':
if target == 'good':
$good_target+=1
if sex == 'man':
$good_target_in_man+=1
elif sex == 'woman':
$good_target_in_woman+=1
elif target == 'bad':
$bad_target+=1
if sex == 'man':
$bad_target_in_man+=1
elif sex == 'woman':
$bad_target_in_woman+=1
import math
man_woe = math.log( (good_target_in_man/good_target)/(bad_target_in_man/bad_target) )
woman_woe = math.log( (good_target_in_woman/good_target)/(bad_target_in_woman/bad_target) )
print 'Weight of evidence for man=%2.4f'%man_woe
print 'Weight of evidence for woman=%2.4f'%woman_woe
Output:
Transformed table: id | target | sex | +--+--------+---------------------+-- 1 | good | 0.1823215567939546 | 2 | bad | -0.2231435513142097 | 3 | good | -0.2231435513142097 | 4 | good | 0.1823215567939546 | 5 | good | -0.2231435513142097 | 6 | good | 0.1823215567939546 | 7 | bad | 0.1823215567939546 | Weight of evidence for man=-0.2231 Weight of evidence for woman=0.1823
LogicalData wywłaszczona przez ustawienia transformacji obiektu nie powinna być zmieniana ręcznie. Tylko wygenerowana automatycznie LogicalData może zostać użyta w transformacjach.