W systemie AdvancedMiner użytkownik może korzystać z języka skryptowego, jakim jest Gython. Oferuje on różnorodne narzędzia do przetwarzania danych takie jak funkcje próbkowania oraz podziału zbioru danych (sample i tableSplit). Poniżej zaprezentowano przykład ilustrujący użycie i efekt działania obydwu funkcji wraz z przykładem definiowania własnych funkcji w języku Gython.
Przykład 1.1. Data processing examples
if not tableExists('german_credit'):
raise "Table 'german_credit' does not exists. Please run german_credit.py script from data directory first"
# FUNCTION DEFINITION Example in Gython
# includes illustration of SQL parametrization - "tableName" parameter
def rowCount(tableName):
sql result:
SELECT count(*) FROM $tableName
return result[0][0]
# SPLITTING DATA Example
# splitting data into data_1 and data_2 sets
in_data = 'german_credit'
split_data_1 = 'german_credit_1'
split_data_2 = 'german_credit_2'
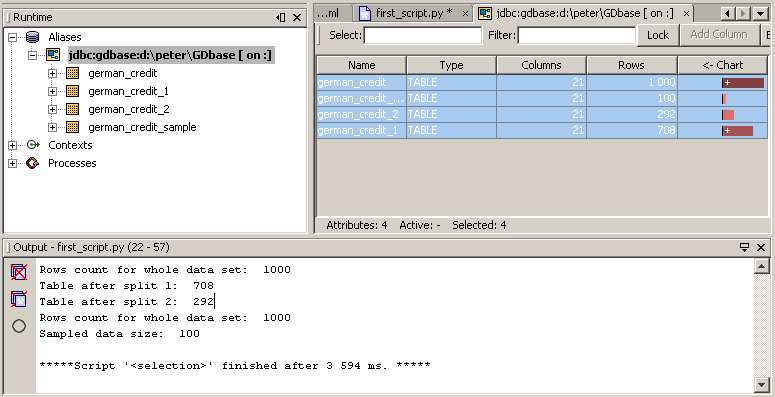
print "Rows count for whole dataset: ", rowCount(in_data )
tableSplit(in_data , split = [7,3], seed = 1234, output=[split_data_1, split_data_2])
print "Table after split 1: ", rowCount(split_data_1)
print "Table after split 2: ", rowCount(split_data_2)
# SAMPLING DATA Example
in_data = 'german_credit'
sample_size = 100
sampled_data = 'german_credit_sample'
print "Rows count for whole dataset: ", rowCount(in_data)
sample(in_data, sampled_data, sample_size)
print "Sampled data size: ", rowCount(sampled_data)
Output:
Rows count for whole dataset: 1000 Table after split 1: 709 Table after split 2: 291 Rows count for whole dataset: 1000 Sampled data size: 100
Notatka
Praca ze skryptem jest wspierana przez zaawansowany edytor wyposażony w funkcję dopełniania kodu, podkreślania składni i.t.p
Gython umożliwia dostęp do:
- szerokiego wachlarza konstrukcji językowych (instrukcji warunkowych, pętli, funkcji i.in) oraz bibliotek dedykowanych projektom analitycznym (zobacz rozdział poświęcony językowi Gython
- języka przetwarzania danych (zobacz rozdział Data Access and Data Processing w Dokumentacji Technicznej) umożliwiającego pracę z tabelami (np.: ich tworzenie, formatowanie, łączenie)
- poleceń SQL, umożliwiając tym samym ich parametryzację, uruchamianie w pętlach, włączanie do funkcji i.t.p.
Oprócz zaprezentowanych metod istnieją jeszcze inne sposoby przetwarzania danych, na przykład Transformacje (binaryzacja, normalizacja, traktowanie wartości odstających, PCA, wypełnianie wartości brakujących, standaryzacja, WoE). Dodatkowe informacje na ten temat można znaleźć w Dokumentacji Technicznej w rozdziale Transformations.